This
post was originally published on
this siteToday, I’m happy to announce a new capability to resolve location data for Amazon Sidewalk enabled devices with the AWS IoT Core Device Location service. This feature removes the requirement to install GPS modules in a Sidewalk device and also simplifies the developer experience of resolving location data. Devices powered by small coin cell batteries, such as smart home sensor trackers, use Sidewalk to connect. Supporting built-in GPS modules for products that move around is not only expensive, it can creates challenge in ensuring optimal battery life performance and longevity.
With this launch, Internet of Things (IoT) device manufacturers and solution developers can build asset tracking and location monitoring solutions using Sidewalk-enabled devices by sending Bluetooth Low Energy (BLE), Wi-Fi, or Global Navigation Satellite System (GNSS) information to AWS IoT for location resolution. They can then send the resolved location data to an MQTT topic or AWS IoT rule and route the data to other Amazon Web Services (AWS) services, thus using different capabilities of AWS Cloud through AWS IoT Core. This would simplify their software development and give them more options to choose the optimal location source, thereby improving their product performance.
This launch addresses previous challenges and architecture complexity. You don’t need location sensing on network-based devices when you use the Sidewalk network infrastructure itself to determine device location, which eliminates the need for power-hungry and costly GPS hardware on the device. And, this feature also allows devices to efficiently measure and report location data from GNSS and Wi-Fi, thus extending the product battery life. Therefore, you can build a more compelling solution for asset tracking and location-aware IoT applications with these enhancements.
For those unfamiliar with Amazon Sidewalk and the AWS IoT Core Device Location service, I’ll briefly explain their history and context. If you’re already familiar with them, you can skip to the section on how to get started.
AWS IoT Core integrations with Amazon Sidewalk
Amazon Sidewalk is a shared network that helps devices work better through improved connectivity options. It’s designed to support a wide range of customer devices with capabilities ranging from locating pets or valuables, to smart home security and lighting control and remote diagnostics for appliances and tools.
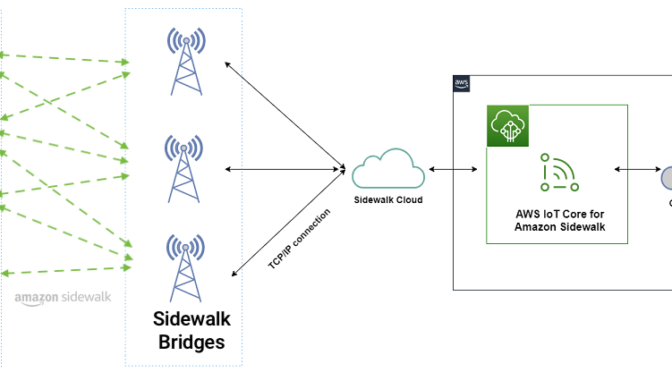
Amazon Sidewalk is a secure community network that uses Amazon Sidewalk Gateways (also called Sidewalk Bridges), such as compatible Amazon Echo and Ring devices, to provide cloud connectivity for IoT endpoint devices. Amazon Sidewalk enables low-bandwidth and long-range connectivity at home and beyond using BLE for short-distance communication and LoRa and frequency-shift keying (FSK) radio protocols at 900MHz frequencies to cover longer distances.
Sidewalk now provides coverage to more than 90% of the US population and supports long-range connected solutions for communities and enterprises. Users with Ring cameras or Alexa devices that act as a Sidewalk Bridge can choose to contribute a small portion of their internet bandwidth, which is pooled to create a shared network that benefits all Sidewalk-enabled devices in a community.
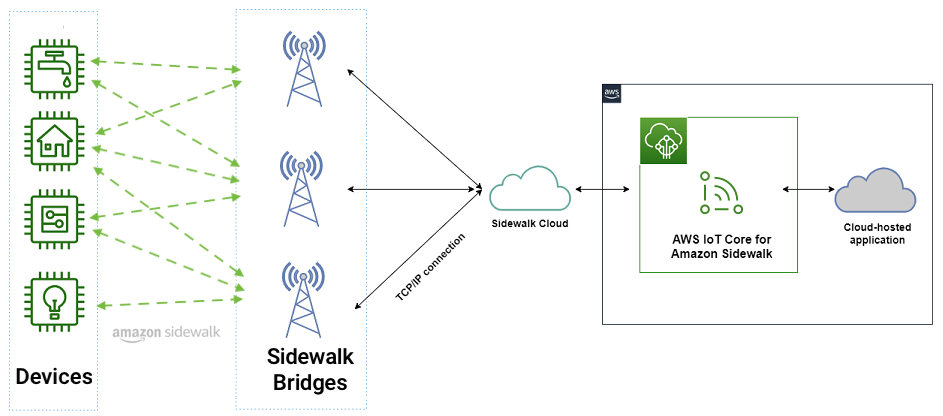
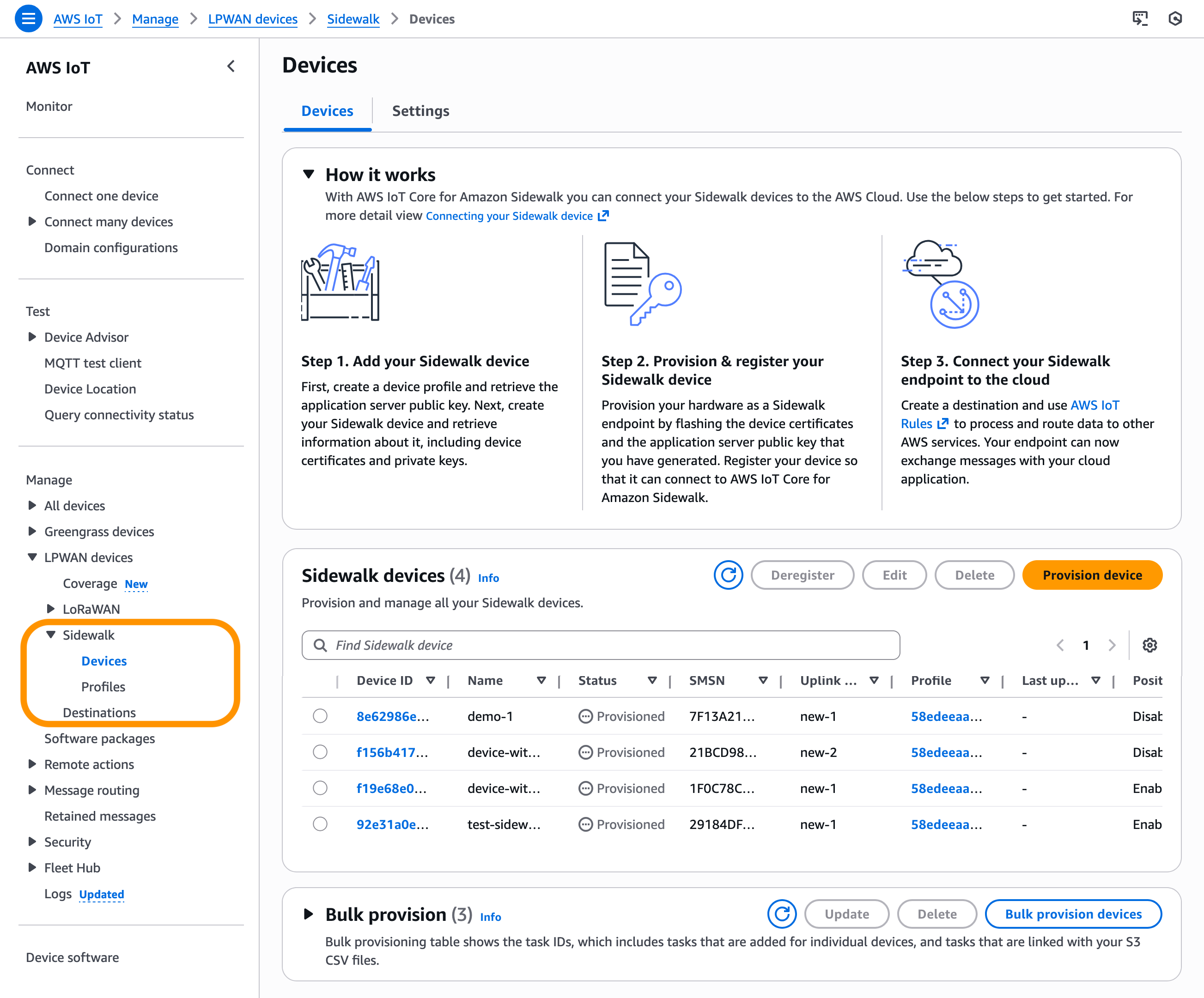
In March 2023, AWS IoT Core deepened its integration with Amazon Sidewalk to seamlessly provision, onboard, and monitor Sidewalk devices with qualified hardware development kits (HDKs), SDKs, and sample applications. As of this writing, AWS IoT Core is the only way for customers to connect the Sidewalk network.
In the AWS IoT Core console, you can add your Sidewalk device, provision and register your devices, and connect your Sidewalk endpoint to the cloud. To learn more about onboarding your Sidewalk devices, visit the Getting started with AWS IoT Core for Amazon Sidewalk in the AWS IoT Wireless Developer Guide.
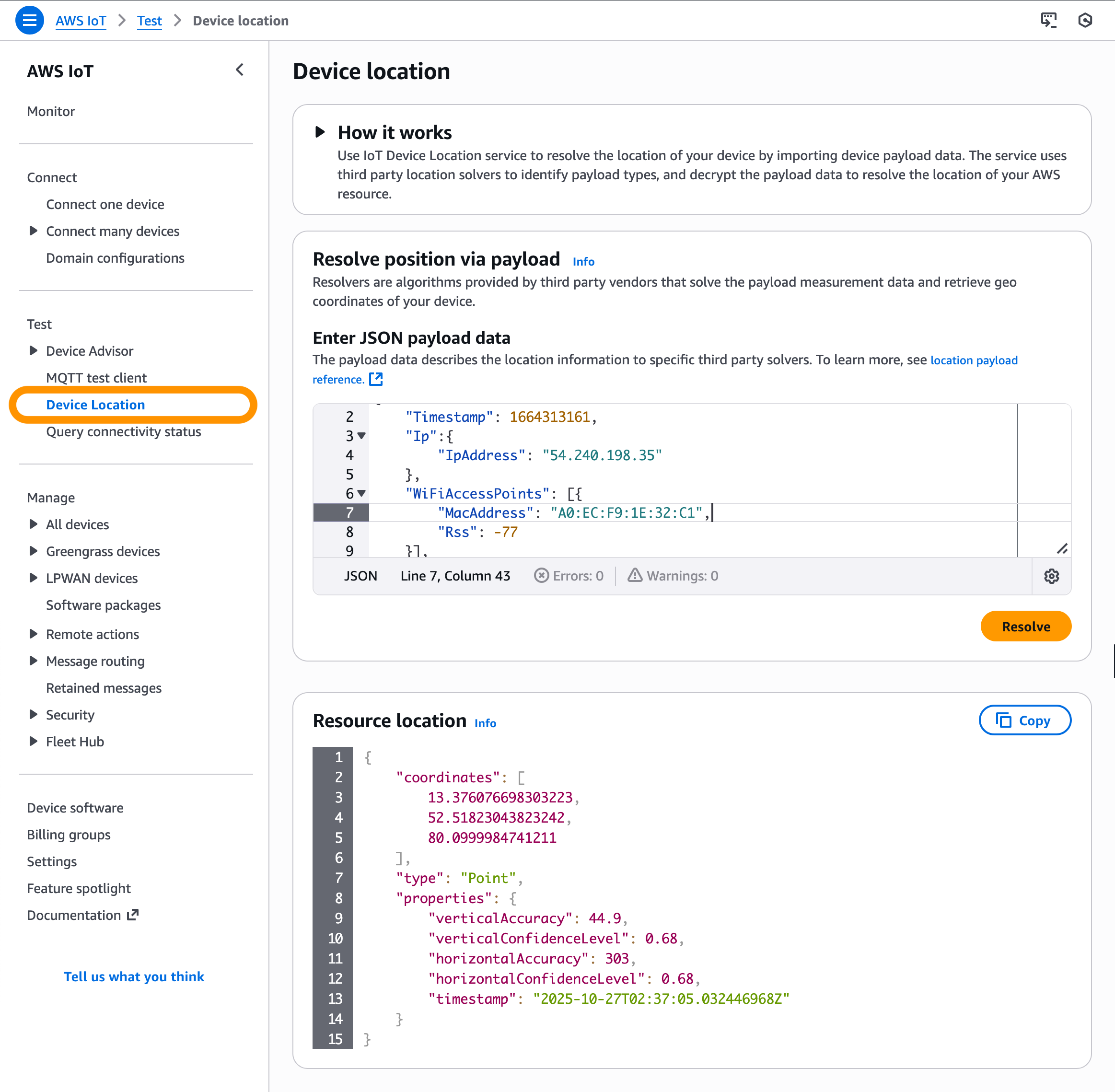
In November 2022, we announced AWS IoT Core Device Location service, a new feature that you can use to get the geo-coordinates of their IoT devices even when the device doesn’t have a GPS module. You can use the Device Location service as a simple request and response HTTP API, or you can use it with IoT connectivity pathways like MQTT, LoRaWAN, and now with Amazon Sidewalk.
In the AWS IoT Core console, you can test the Device Location service to resolve the location of your device by importing device payload data. Resource location is reported as a GeoJSON payload. To learn more, visit the AWS IoT Core Device Location in the AWS IoT Core Developer Guide.
Customers across multiple industries like automotive, supply chain, and industrial tools have requested a simplified solution such as the Device Location service to extract location-data from Sidewalk products. This would streamline customer software development and give them more options to choose the optimal location source, thereby improving their product.
Get started with a Device Location integration with Amazon Sidewalk
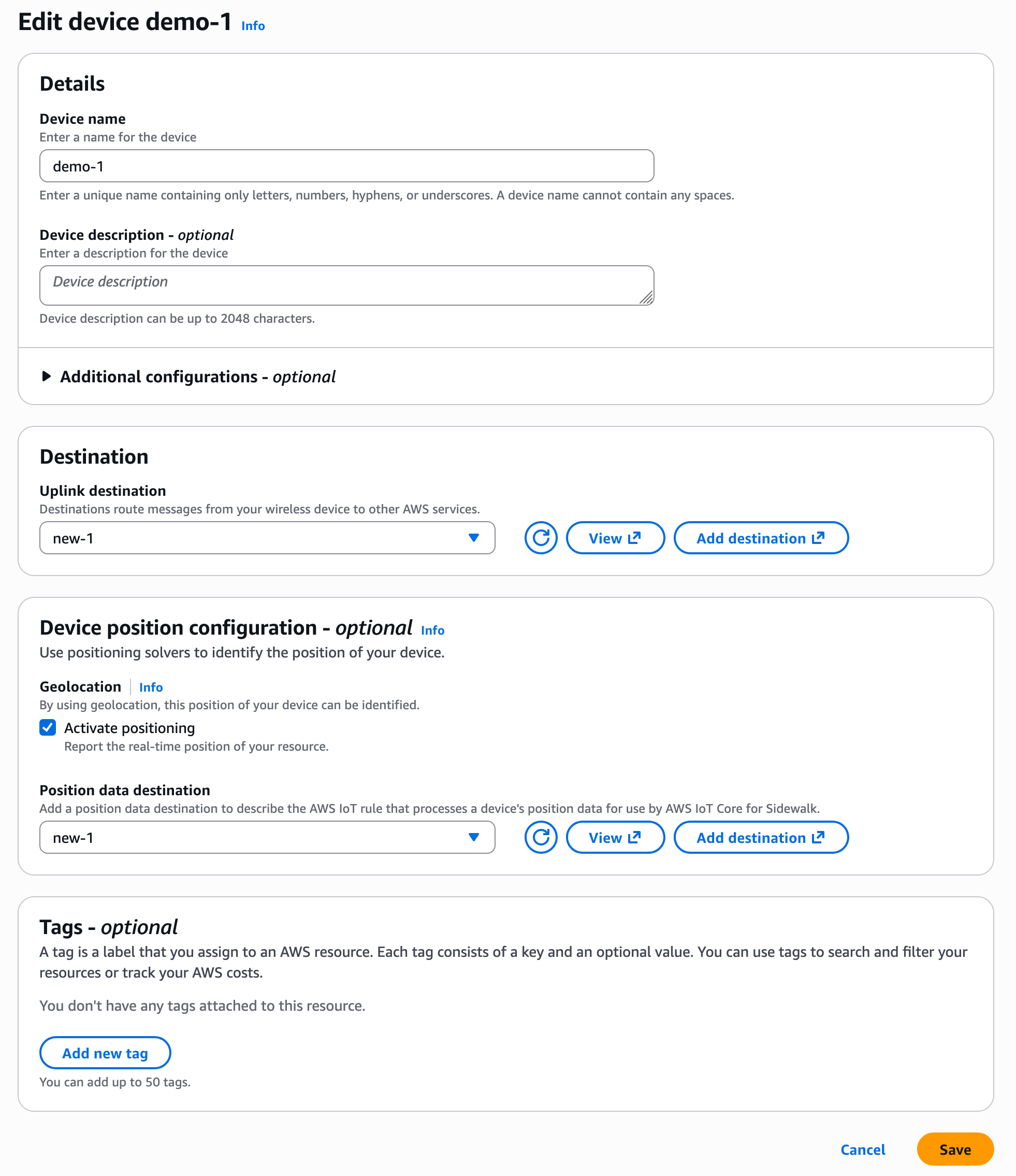
To enable Device Location for Sidewalk devices, go to the AWS IoT Core for Amazon Sidewalk section under LPWAN devices in the AWS IoT Core console. Choose Provision device or your existing device to edit the setting and select Activate positioning in the Geolocation option when creating and updating your Sidewalk devices.
While activating position, you need to specify a destination where you want to send your location data. The destination can either be an AWS IoT rule or an MQTT topic.
Here is a sample AWS Command Line Interface (AWS CLI) command to enable position while provisioning a new Sidewalk device:
$ aws iotwireless createwireless device --type Sidewalk
--name "demo-1" --destination-name "New-1"
--positioning Enabled
After your Sidewalk device establishes a connection to the Amazon Sidewalk network, the device SDK will send the GNSS-, Wi-Fi- or BLE-based information to AWS IoT Core for Amazon Sidewalk. If the customer has enabled Positioning, then AWS IoT Core Device Location will resolve the location data and send the location data to the specified Destination. After your Sidewalk device transmits location measurement data, the resolved geographic coordinates and a map pin will also be displayed in the Position section for the selected device.
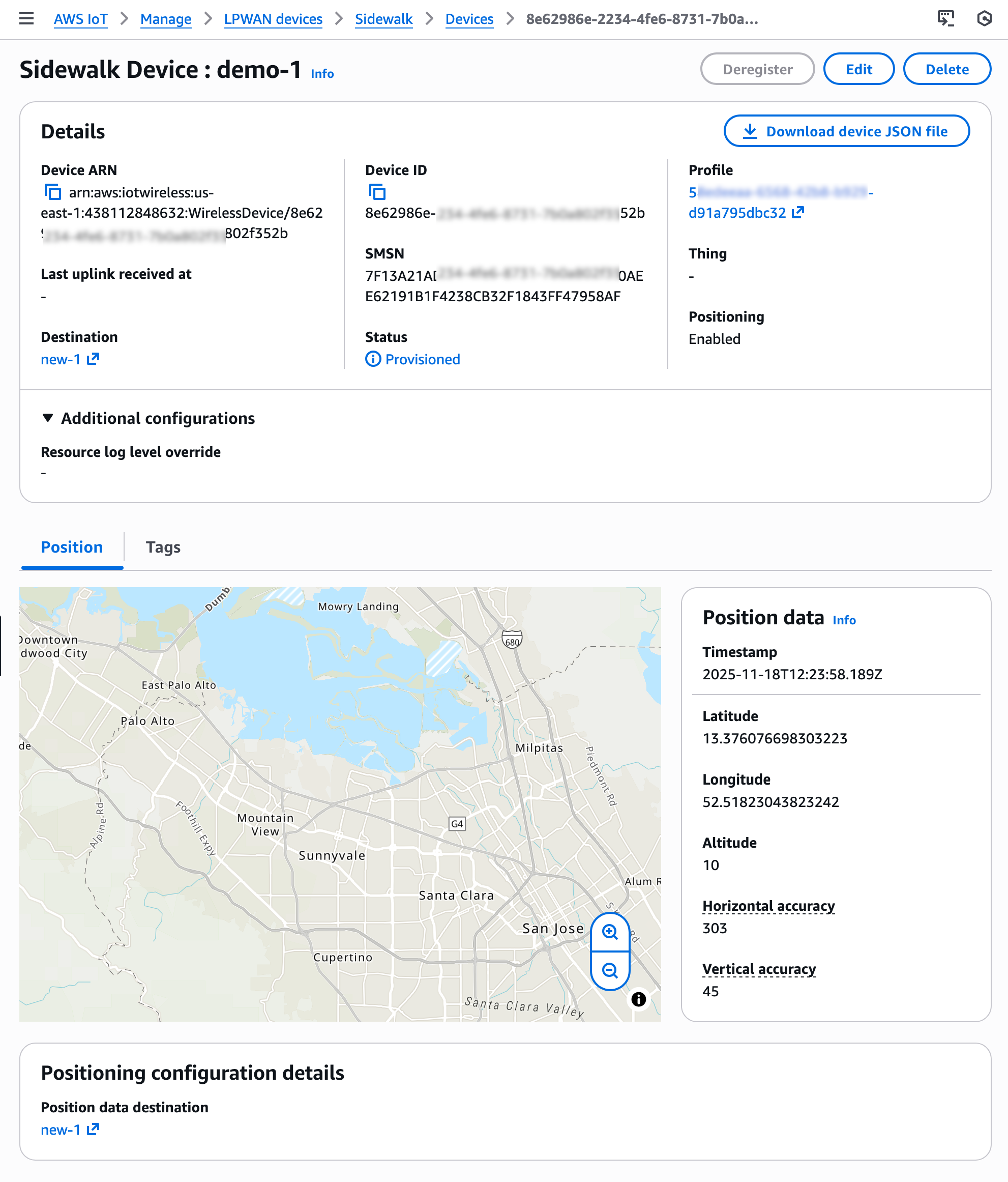
You will also get location information delivered to your destination in GeoJSON format, as shown in the following example:
{
"coordinates": [
13.376076698303223,
52.51823043823242
],
"type": "Point",
"properties": {
"verticalAccuracy": 45,
"verticalConfidenceLevel": 0.68,
"horizontalAccuracy": 303,
"horizontalConfidenceLevel": 0.68,
"country": "USA",
"state": "CA",
"city": "Sunnyvale",
"postalCode": "91234",
"timestamp": "2025-11-18T12:23:58.189Z"
}
}
You can monitor the Device Location data between your Sidewalk devices and AWS Cloud by enabling Amazon CloudWatch Logs for AWS IoT Core. To learn more, visit the AWS IoT Core for Amazon Sidewalk in the AWS IoT Wireless Developer Guide.
Now available
AWS IoT Core Device Location integration with Amazon Sidewalk is now generally available in the US East (N. Virginia) Region. To learn more about use cases, documentation, sample codes, and partner devices, visit the AWS IoT Core for Amazon Sidewalk product page.
Give it a try in the AWS IoT Core console and send feedback to AWS re:Post for AWS IoT Core or through your usual AWS Support contacts.
— Channy













 Last week I met Jeff Barr at the
Last week I met Jeff Barr at the