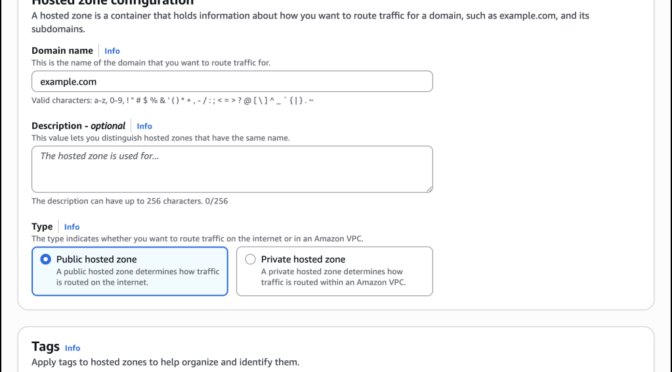
Today, we’re announcing IAM Policy Autopilot, a new open source Model Context Protocol (MCP) server that analyzes your application code and helps your AI coding assistants generate AWS Identity and Access Management (IAM) identity-based policies. IAM Policy Autopilot accelerates initial development by providing builders with a starting point that they can review and further refine. It integrates with AI coding assistants such as Kiro, Claude Code, Cursor, and Cline, and it provides them with AWS Identity and Access Management (IAM) knowledge and understanding of the latest AWS services and features. IAM Policy Autopilot is available at no additional cost, runs locally, and you can get started by visiting our GitHub repository.
Amazon Web Services (AWS) applications require IAM policies for their roles. Builders on AWS, from developers to business leaders, engage with IAM as part of their workflow. Developers typically start with broader permissions and refine them over time, balancing rapid development with security. They often use AI coding assistants in hopes of accelerating development and authoring IAM permissions. However, these AI tools don’t fully understand the nuances of IAM and can miss permissions or suggest invalid actions. Builders seek solutions that provide reliable IAM knowledge, integrate with AI assistants and get them started with policy creation, so that they can focus on building applications.
Create valid policies with AWS knowledge
IAM Policy Autopilot addresses these challenges by generating identity-based IAM policies directly from your application code. Using deterministic code analysis, it creates reliable and valid policies, so you spend less time authoring and debugging permissions. IAM Policy Autopilot incorporates AWS knowledge, including published AWS service reference implementation, to stay up to date. It uses this information to understand how code and SDK calls map to IAM actions and stays current with the latest AWS services and operations.
The generated policies provide a starting point for you to review and scope down to implement least privilege permissions. As you modify your application code—whether adding new AWS service integrations or updating existing ones—you only need to run IAM Policy Autopilot again to get updated permissions.
Getting started with IAM Policy Autopilot
Developers can get started with IAM Policy Autopilot in minutes by downloading and integrating it with their workflow.
As an MCP server, IAM Policy Autopilot operates in the background as builders converse with their AI coding assistants. When your application needs IAM policies, your coding assistants can call IAM Policy Autopilot to analyze AWS SDK calls within your application and generate required identity-based IAM policies, providing you with necessary permissions to start with. After permissions are created, if you still encounter Access Denied errors during testing, the AI coding assistant invokes IAM Policy Autopilot to analyze the denial and propose targeted IAM policy fixes. After you review and approve the suggested changes, IAM Policy Autopilot updates the permissions.
You can also use IAM Policy Autopilot as a standalone command line interface (CLI) tool to generate policies directly or fix missing permissions. Both the CLI tool and the MCP server provide the same policy creation and troubleshooting capabilities, so you can choose the integration that best fits your workflow.
When using IAM Policy Autopilot, you should also understand the best practices to maximize its benefits. IAM Policy Autopilot generates identity-based policies and doesn’t create resource-based policies, permission boundaries, service control policies (SCPs) or resource control policies (RCPs). IAM Policy Autopilot generates policies that prioritize functionality over minimal permissions. You should always review the generated policies and refine if necessary so they align with your security requirements before deploying them.
Let’s try it out
To set up IAM Policy Autopilot, I first need to install it on my system. To do so, I just need to run a one-liner script:
curl https://github.com/awslabs/iam-policy-autopilot/raw/refs/heads/main/install.sh | bash
Then I can follow the instructions to install any MCP server for my IDE of choice. Today, I’m using Kiro!
In a new chat session in Kiro, I start with a straightforward prompt, where I ask Kiro to read the files in my file-to-queue folder and create a new AWS CloudFormation file so I can deploy the application. This folder contains an automated Amazon Simple Storage Service (Amazon S3) file router that scans a bucket and sends notifications to Amazon Simple Queue Service (Amazon SQS) queues or Amazon EventBridge based on configurable prefix-matching rules, enabling event-driven workflows triggered by file locations.
The last part asks Kiro to make sure I’m including necessary IAM policies. This should be enough to get Kiro to use the IAM Policy Autopilot MCP server.
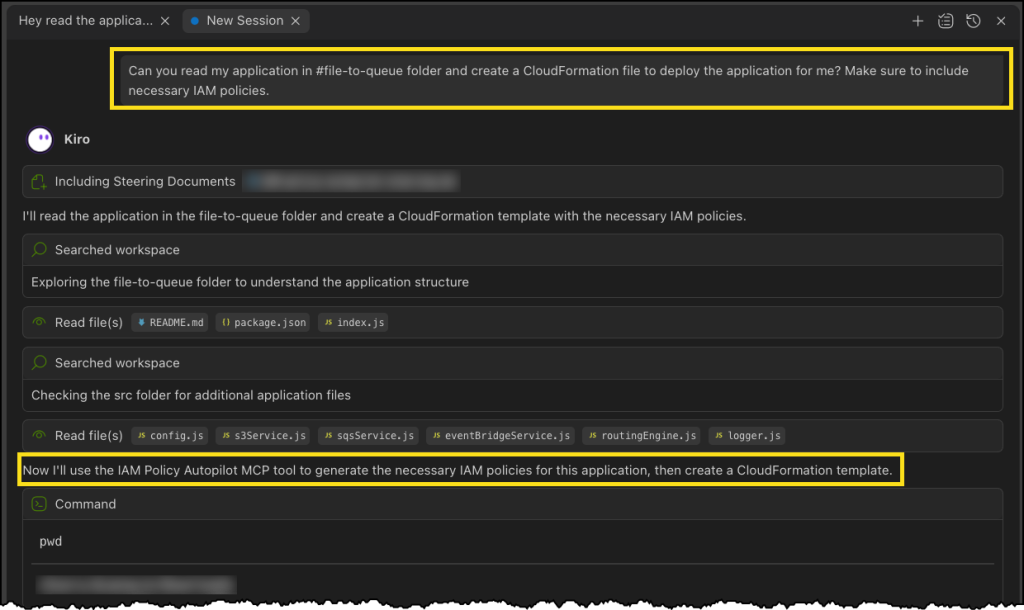
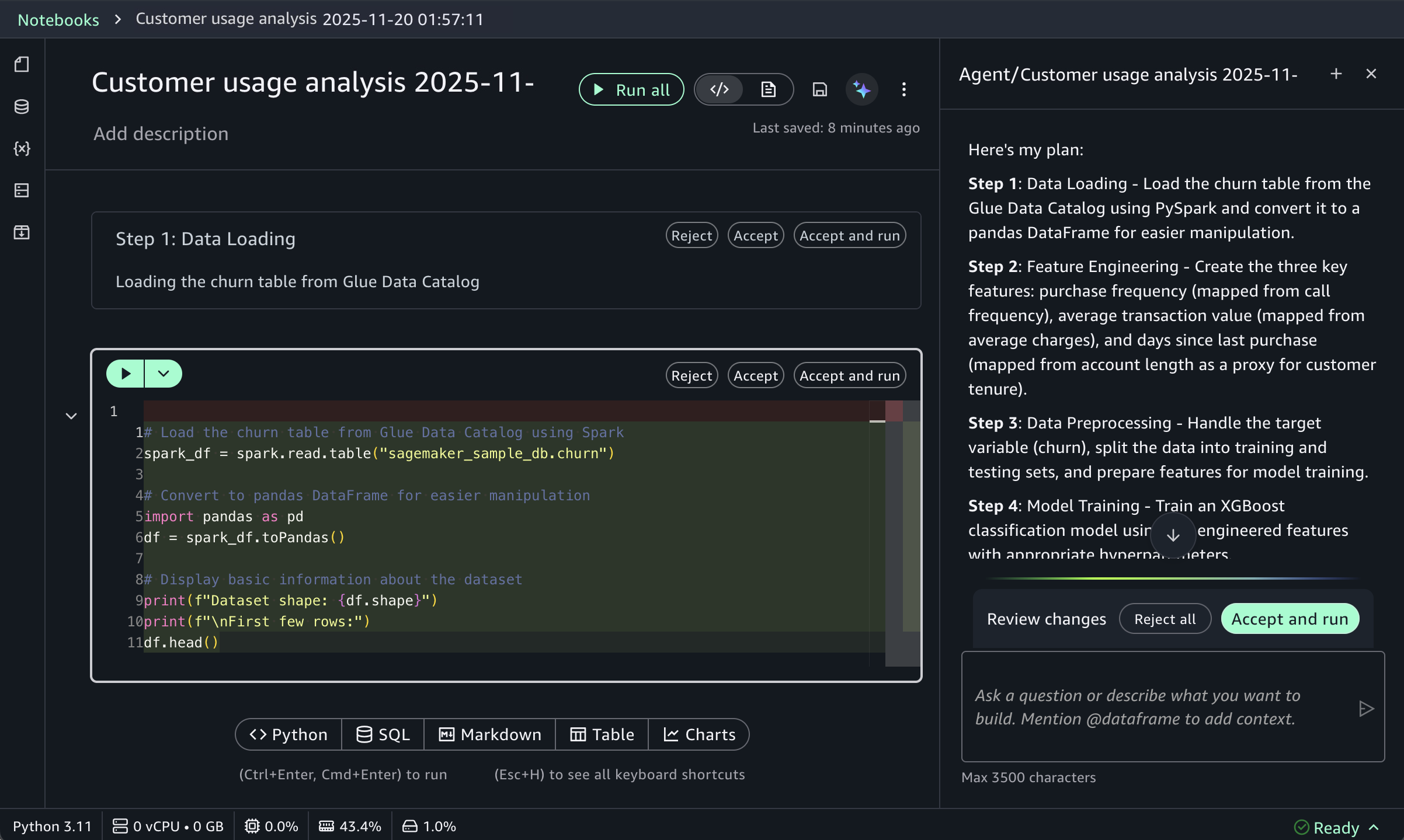
Next, Kiro uses the IAM Policy Autopilot MCP server to generate a new policy document, as depicted in the following image. After it’s done, Kiro will move on to building out our CloudFormation template and some additional documentation and relevant code files.

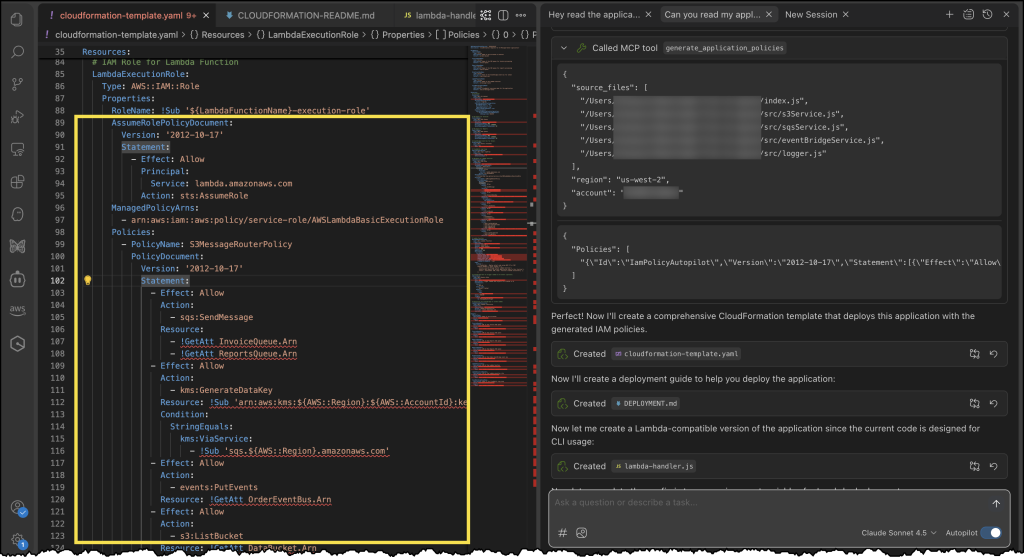
Finally, we can see our generated CloudFormation template with a new policy document, all generated using the IAM Policy Autopilot MCP server!
Enhanced development workflow
IAM Policy Autopilot integrates with AWS services across multiple areas. For core AWS services, IAM Policy Autopilot analyzes your application’s usage of services such as Amazon S3, AWS Lambda, Amazon DynamoDB, Amazon Elastic Compute Cloud (Amazon EC2), and Amazon CloudWatch Logs, then generates necessary permissions your code needs based on the SDK calls it discovers. After the policies are created, you can copy the policy directly into your CloudFormation template, AWS Cloud Development Kit (AWS CDK) stack, or Terraform configuration. You can also prompt your AI coding assistants to integrate it for you.
IAM Policy Autopilot also complements existing IAM tools such as AWS IAM Access Analyzer by providing functional policies as a starting point, which you can then validate using IAM Access Analyzer policy validation or refine over time with unused access analysis.
Now available
IAM Policy Autopilot is available as an open source tool on GitHub at no additional cost. The tool currently supports Python, TypeScript, and Go applications.
These capabilities represent a significant step forward in simplifying the AWS development experience so builders of different experience levels can develop and deploy applications more efficiently.