
Xavier's diary entry "Abusing DLLs EntryPoint for the Fun" inspired me to do some tests with TLS Callbacks and DLLs.
Monthly Archives: December 2025

Positive trends related to public IP ranges from the year 2025, (Thu, Dec 18th)
This post was originally published on this site
Since the end of the year is quickly approaching, it is undoubtedly a good time to look back at what the past twelve months have brought to us… And given that the entire cyber security profession is about protecting various systems from “bad things” (and we’ve all correspondingly seen more than our share of the “bad”), I thought that it might be pleasant to look at a few positive background trends that have accompanied us throughout the year, without us necessarily noticing…

Maybe a Little Bit More Interesting React2Shell Exploit, (Wed, Dec 17th)
AWS Weekly Roundup: Amazon ECS, Amazon CloudWatch, Amazon Cognito and more (December 15, 2025)
This post was originally published on this site
Can you believe it? We’re nearly at the end of 2025. And what a year it’s been! From re:Invent recap events, to AWS Summits, AWS Innovate, AWS re:Inforce, Community Days, and DevDays and, recently, adding that cherry on the cake, re:Invent 2025, we have lived through a year filled with exciting moments and technology advancements which continue to shape our new modern world.
Speaking of re:Invent, if you haven’t caught up yet on all the new releases and announcements (and there were plenty of exciting launches across every area), be sure to check out our curated post highlighting the top announcements from AWS re:Invent 2025. We’ve organized all the key releases into easy-to-navigate categories and included links so you can dive deeper into anything that sparks your interest.
While the year may be wrapping up, our teams are still busy working on things that you have either asked for as customers or that we pro-actively create to make your lives easier. Last week had quite a few interesting releases as usual, so let’s look at a few that I think could be useful for many of you out there.
Last week’s launches
Amazon WorkSpaces Secure Browser introduces Web Content Filtering – Organizations can now control web access through category-based filtering across 25+ predefined categories, granular URL policies, and integrated compliance logging. The feature works alongside existing Chrome policies and integrates with Session Logger for enhanced monitoring and is available at no additional cost in 10 AWS Regions with pay-as-you-go pricing.
Amazon Aurora DSQL now supports cluster creation in seconds – Developers can now instantly provision Aurora DSQL databases with setup time reduced from minutes to seconds, enabling rapid prototyping through the integrated AWS console query editor or AI-powered development via the Aurora DSQL Model Context Protocol server. Available at no additional cost in all AWS Regions where Aurora DSQL is offered, with AWS Free Tier access available.
Amazon Aurora PostgreSQL now supports integration with Kiro powers – Developers can now accelerate Aurora PostgreSQL application development using AI-assisted coding through Kiro powers, a repository of pre-packaged Model Context Protocol servers. The Aurora PostgreSQL integration provides direct database connectivity for queries, schema management, and cluster operations, dynamically loading relevant context as developers work. Available for one-click installation in Kiro IDE across all AWS Regions.
Amazon ECS now supports custom container stop signals on AWS Fargate – Fargate tasks now honor the stop signal configured in container images, enabling graceful shutdowns for containers that rely on signals like SIGQUIT or SIGINT instead of the default SIGTERM. The ECS container agent reads the STOPSIGNAL instruction from OCI-compliant images and sends the appropriate signal during task termination. Available at no additional cost across all AWS Regions.
Amazon CloudWatch SDK supports optimized JSON, CBOR protocols – CloudWatch SDK now defaults to JSON and CBOR protocols, delivering lower latency, reduced payload sizes, and decreased client-side CPU and memory usage compared to the traditional AWS Query protocol. Available at no additional cost across all AWS Regions and SDK language variants.
Amazon Cognito identity pools now support private connectivity with AWS PrivateLink – Organizations can now securely exchange federated identities for temporary AWS credentials through private VPC connections, eliminating the need to route authentication traffic over the public internet. Available in all AWS Regions where Cognito identity pools are supported, except AWS China (Beijing) and AWS GovCloud (US) Regions.
AWS Application Migration Service supports IPv6 – Organizations can now migrate applications using IPv6 addressing through dual-stack service endpoints that support both IPv4 and IPv6 communications. During replication, testing, and cutover phases, you can use IPv4, IPv6, or dual-stack configurations to launch servers in your target environment. Available at no additional cost in all AWS Regions that support MGN and EC2 dual-stack endpoints.
And that’s it for the AWS News Blog Weekly Roundup…not just for this week, but for 2025! We’ll be taking a break and returning in January to continue bringing you the latest AWS releases and updates.
As we close out 2025, it’s remarkable to look back at just how much has changed since the beginning of year. From groundbreaking AI capabilities to transformative infrastructure innovations, AWS has delivered an incredible year of releases that have reshaped what’s possible in the cloud. Throughout it all, the AWS News Blog has been right here with you every week with our Weekly Roundup series, helping you stay informed and ready to take advantage of each new opportunity as it arrived. We’re grateful you’ve joined us on this journey, and we can’t wait to continue bringing you the latest AWS innovations when we return in January 2026.
Until then, happy building, and here’s to an even more exciting year ahead!

Possible exploit variant for CVE-2024-9042 (Kubernetes OS Command Injection), (Wed, Dec 10th)

Microsoft Patch Tuesday December 2025, (Tue, Dec 9th)

AutoIT3 Compiled Scripts Dropping Shellcodes, (Fri, Dec 5th)
This post was originally published on this site
AutoIT3[1] is a powerful language that helps to built nice applications for Windows environments, mainly to automate tasks. If it looks pretty old, the latest version was released last September and it remains popular amongst developers, for the good… or the bad! Malware written in AutoIt3 has existed since the late 2000s, when attackers realized that the language was easy to learn (close to basic) but can also compiled into standalone PE files! From a malware point of view, such executables make an extended use of packed data, making them more stealthy.

Attempts to Bypass CDNs, (Wed, Dec 3rd)
This post was originally published on this site
Currently, in order to provide basic DDoS protection and filter aggressive bots, some form of Content Delivery Network (CDN) is usually the simplest and most cost-effective way to protect a web application. In a typical setup, DNS is used to point clients to the CDN, and the CDN will then forward the request to the actual web server. There are a number of companies offering services like this, and cloud providers will usually have solutions like this as well.
New serverless customization in Amazon SageMaker AI accelerates model fine-tuning
This post was originally published on this site
Today, I’m happy to announce new serverless customization in Amazon SageMaker AI for popular AI models, such as Amazon Nova, DeepSeek, GPT-OSS, Llama, and Qwen. The new customization capability provides an easy-to-use interface for the latest fine-tuning techniques like reinforcement learning, so you can accelerate the AI model customization process from months to days.
With a few clicks, you can seamlessly select a model and customization technique, and handle model evaluation and deployment—all entirely serverless so you can focus on model tuning rather than managing infrastructure. When you choose serverless customization, SageMaker AI automatically selects and provisions the appropriate compute resources based on the model and data size.
Getting started with serverless model customization
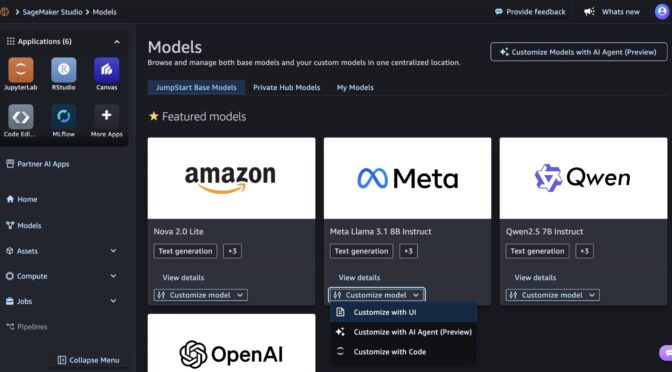
You can get started customizing models in Amazon SageMaker Studio. Choose Models in the left navigation pane and check out your favorite AI models to be customized.
Customize with UI
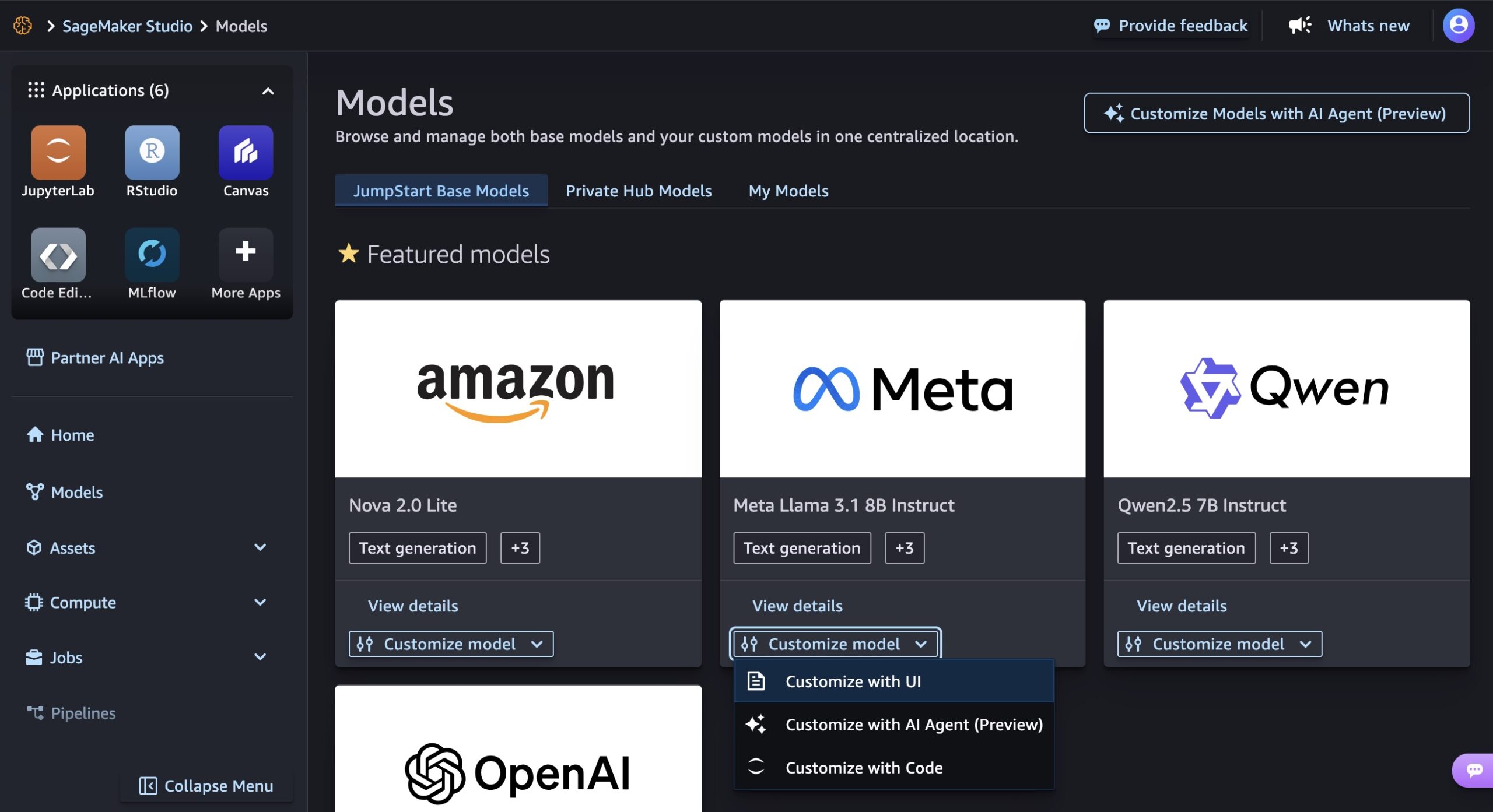
You can customize AI models in a only few clicks. In the Customize model dropdown list for a specific model such as Meta Llama 3.1 8B Instruct, choose Customize with UI.
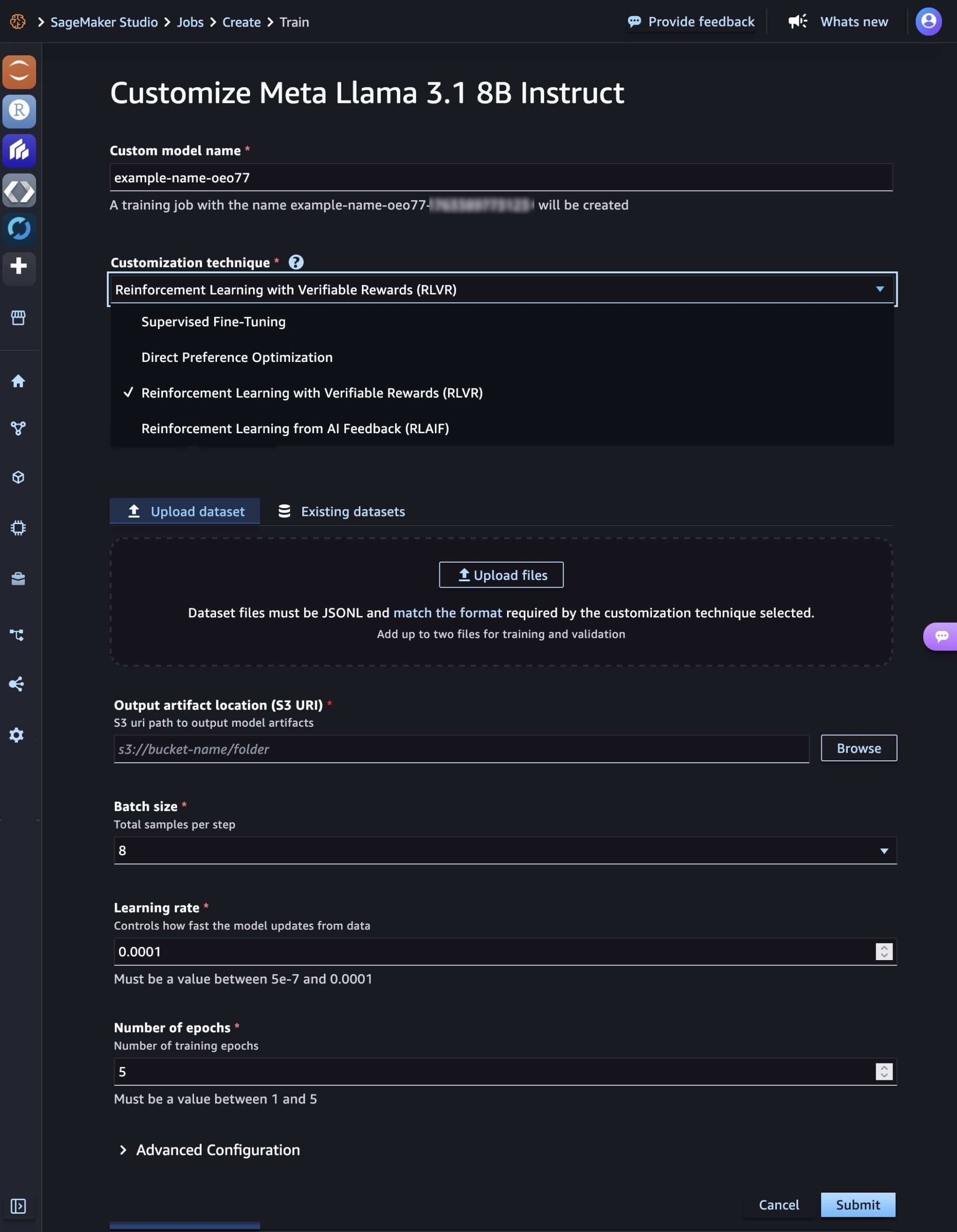
You can select a customization technique used to adapt the base model to your use case. SageMaker AI supports Supervised Fine-Tuning and the latest model customization techniques including Direct Preference Optimization, Reinforcement Learning from Verifiable Rewards (RLVR), and Reinforcement Learning from AI Feedback (RLAIF). Each technique optimizes models in different ways, with selection influenced by factors such as dataset size and quality, available computational resources, task at hand, desired accuracy levels, and deployment constraints.
Upload or select a training dataset to match the format required by the customization technique selected. Use the values of batch size, learning rate, and number of epochs recommended by the technique selected. You can configure advanced settings such as hyperparameters, a newly introduced serverless MLflow application for experiment tracking, and network and storage volume encryption. Choose Submit to get started on your model training job.
After your training job is complete, you can see the models you created in the My Models tab. Choose View details in one of your models.
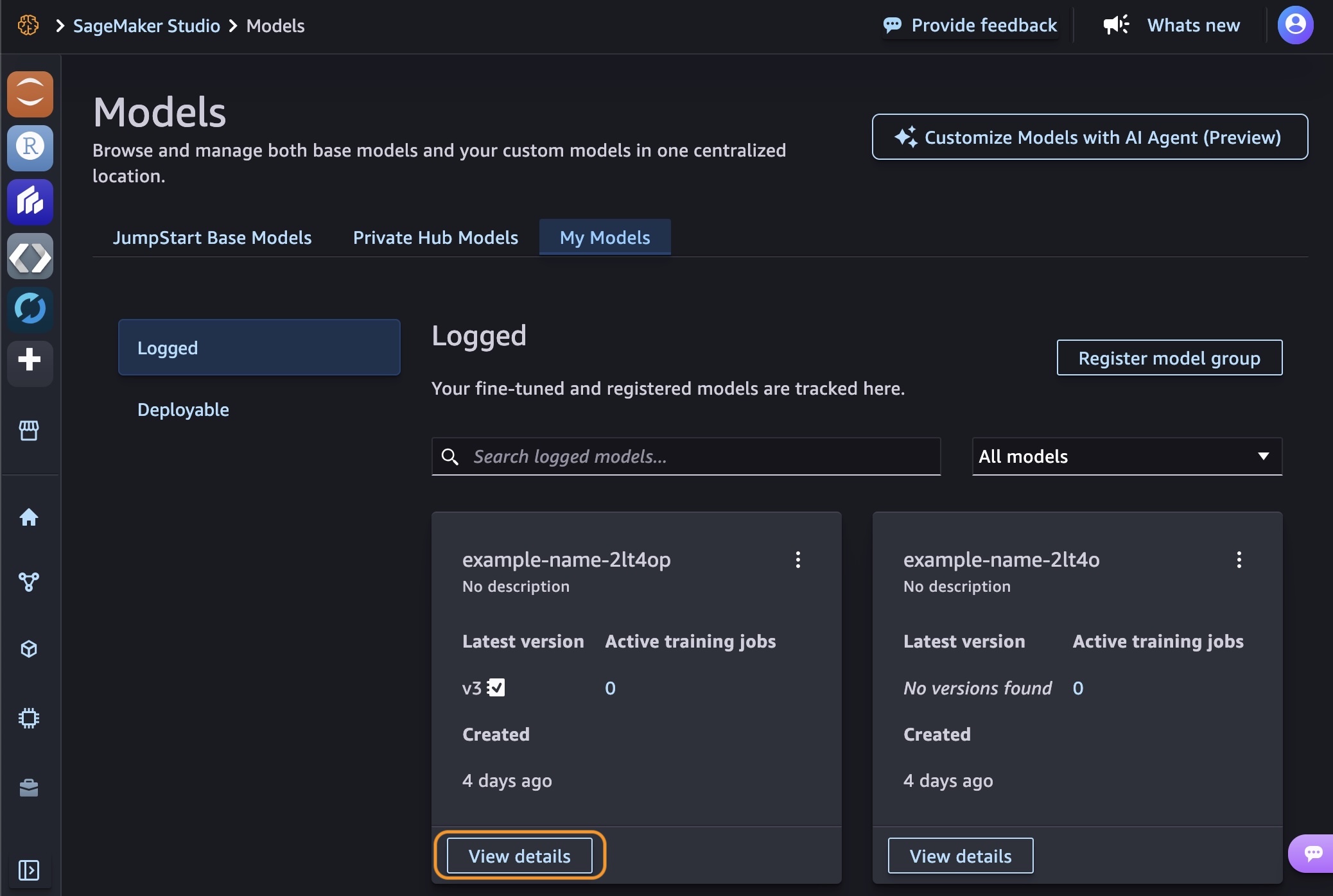
By choosing Continue customization, you can continue to customize your model by adjusting hyperparameters or training with different techniques. By choosing Evaluate, you can evaluate your customized model to see how it performs compared to the base model.
When you complete both jobs, you can choose either the SageMaker or Bedrock in the Deploy dropdown list to deploy your model.

You can choose Amazon Bedrock for serverless inference. Choose Bedrock and the model name to deploy the model into Amazon Bedrock. To find your deployed models, choose Imported models in the Bedrock console.
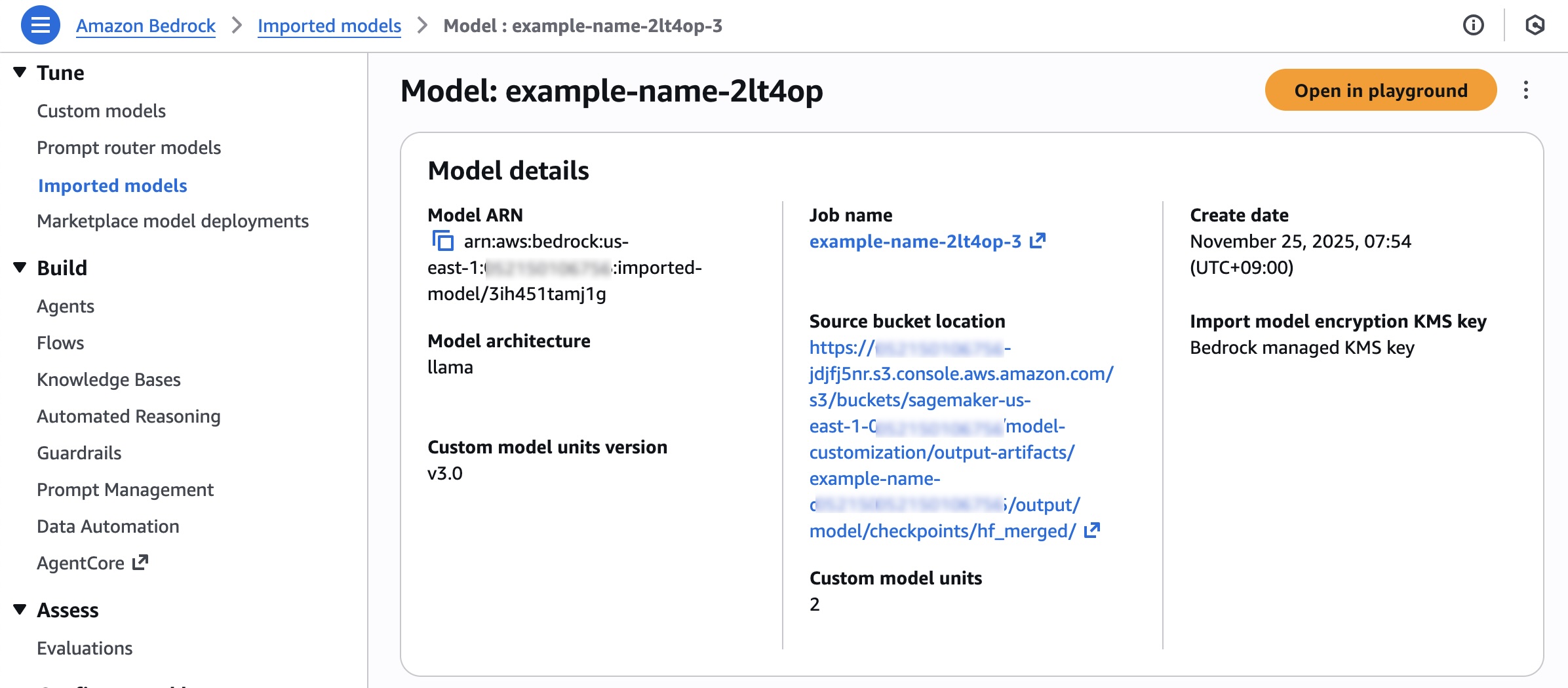
You can also deploy your model to a SageMaker AI inference endpoint if you want to control your deployment resources such as an instance type and instance count. After the SageMaker AI deployment is In service, you can use this endpoint to perform inference. In the Playground tab, you can test your customized model with a single prompt or chat mode.

With the serverless MLflow capability, you can automatically log all critical experiment metrics without modifying code and access rich visualizations for further analysis.
Customize with code
When you choose customizing with code, you can see a sample notebook to fine-tune or deploy AI models. If you want to edit the sample notebook, open it in JupyterLab. Alternatively, you can deploy the model immediately by choosing Deploy.
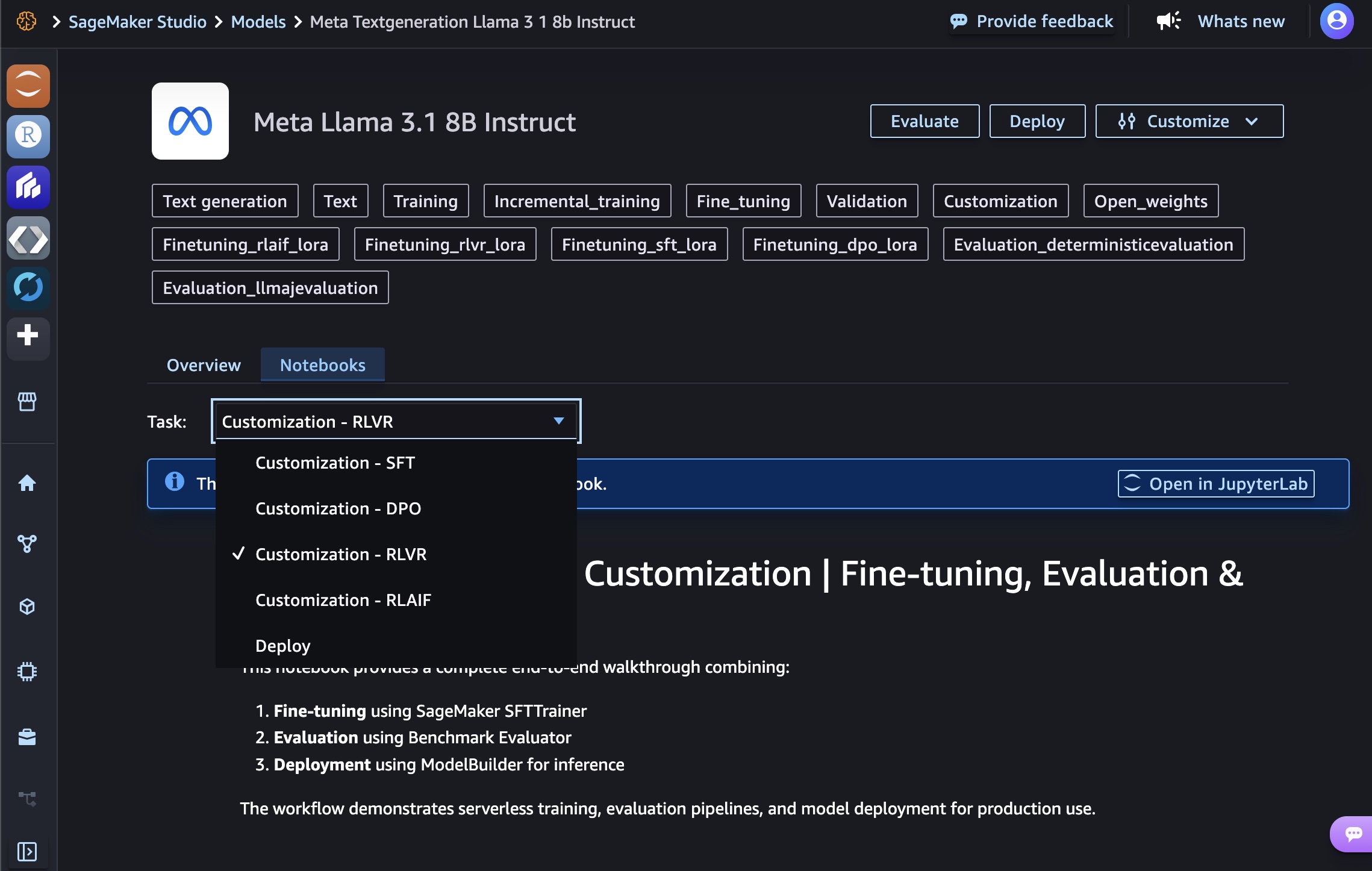
You can choose the Amazon Bedrock or SageMaker AI endpoint by selecting the deployment resources either from Amazon SageMaker Inference or Amazon SageMaker Hyperpod.
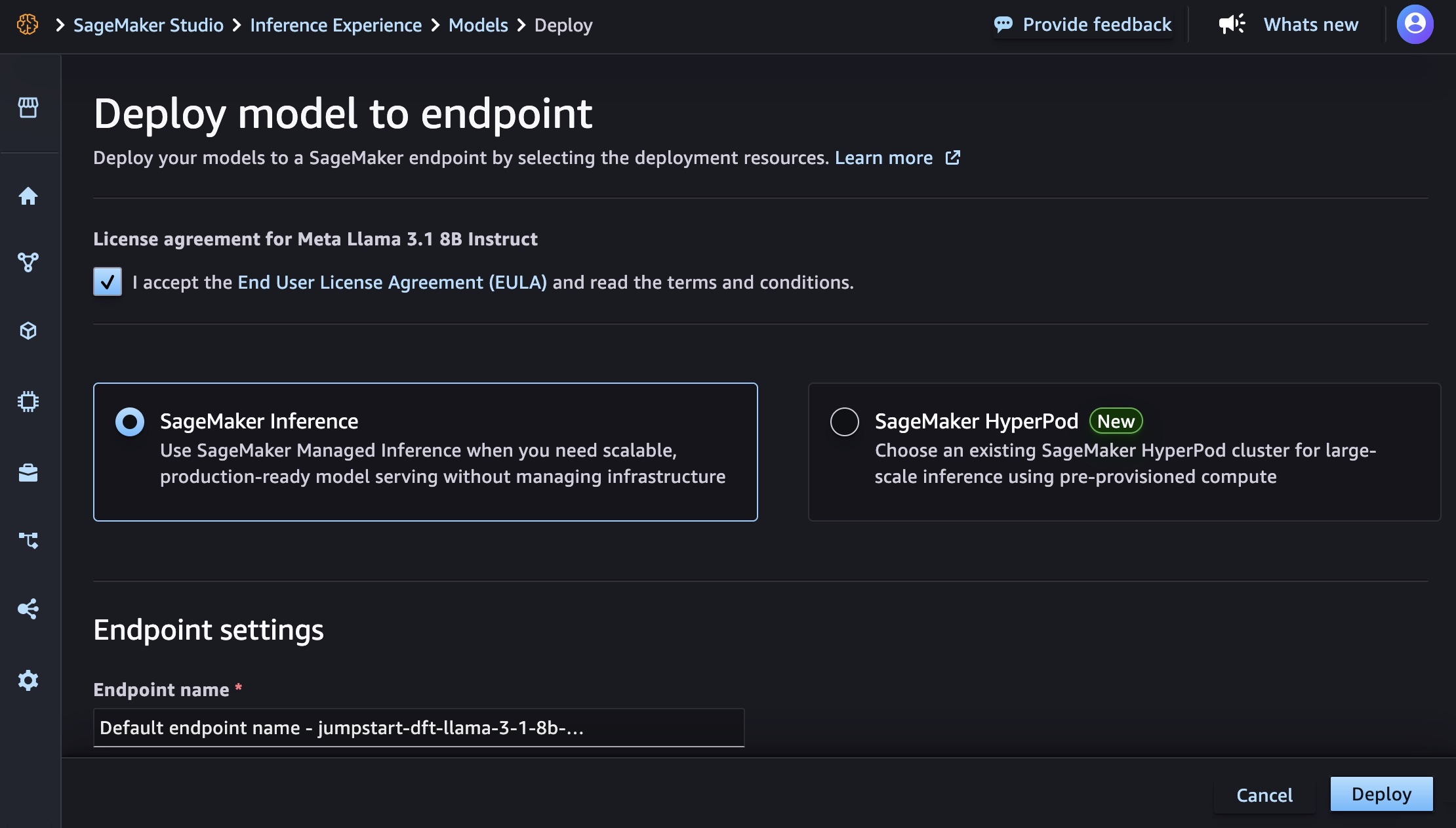
When you choose Deploy on the bottom right of the page, it will be redirected back to the model detail page. After the SageMaker AI deployment is in service, you can use this endpoint to perform inference.
Okay, you’ve seen how to streamline the model customization in the SageMaker AI. You can now choose your favorite way. To learn more, visit the Amazon SageMaker AI Developer Guide.
Now available
New serverless AI model customization in Amazon SageMaker AI is now available in US East (N. Virginia), US West (Oregon), Asia Pacific (Tokyo), and Europe (Ireland) Regions. You only pay for the tokens processed during training and inference. To learn more details, visit Amazon SageMaker AI pricing page.
Give it a try in Amazon SageMaker Studio and send feedback to AWS re:Post for SageMaker or through your usual AWS Support contacts.
— Channy
Introducing checkpointless and elastic training on Amazon SageMaker HyperPod
This post was originally published on this site
Today, we’re announcing two new AI model training features within Amazon SageMaker HyperPod: checkpointless training, an approach that mitigates the need for traditional checkpoint-based recovery by enabling peer-to-peer state recovery, and elastic training, enabling AI workloads to automatically scale based on resource availability.
- Checkpointless training – Checkpointless training eliminates disruptive checkpoint-restart cycles, maintaining forward training momentum despite failures, reducing recovery time from hours to minutes. Accelerate your AI model development, reclaim days from development timelines, and confidently scale training workflows to thousands of AI accelerators.
- Elastic training – Elastic training maximizes cluster utilization as training workloads automatically expand to use idle capacity as it becomes available, and contract to yield resources as higher-priority workloads like inference volumes peak. Save hours of engineering time per week spent reconfiguring training jobs based on compute availability.
Rather than spending time managing training infrastructure, these new training techniques mean that your team can concentrate entirely on enhancing model performance, ultimately getting your AI models to market faster. By eliminating the traditional checkpoint dependencies and fully utilizing available capacity, you can significantly reduce model training completion times.
Checkpointless training: How it works
Traditional checkpoint-based recovery has these sequential job stages: 1) job termination and restart, 2) process discovery and network setup, 3) checkpoint retrieval, 4) data loader initialization, and 5) training loop resumption. When failures occur, each stage can become a bottleneck and training recovery can take up to an hour on self-managed training clusters. The entire cluster must wait for every single stage to complete before training can resume. This can lead to the entire training cluster sitting idle during recovery operations, which increases costs and extends the time to market.
Checkpointless training removes this bottleneck entirely by maintaining continuous model state preservation across the training cluster. When failures occur, the system instantly recovers by using healthy peers, avoiding the need for a checkpoint-based recovery that requires restarting the entire job. As a result, checkpointless training enables fault recovery in minutes.
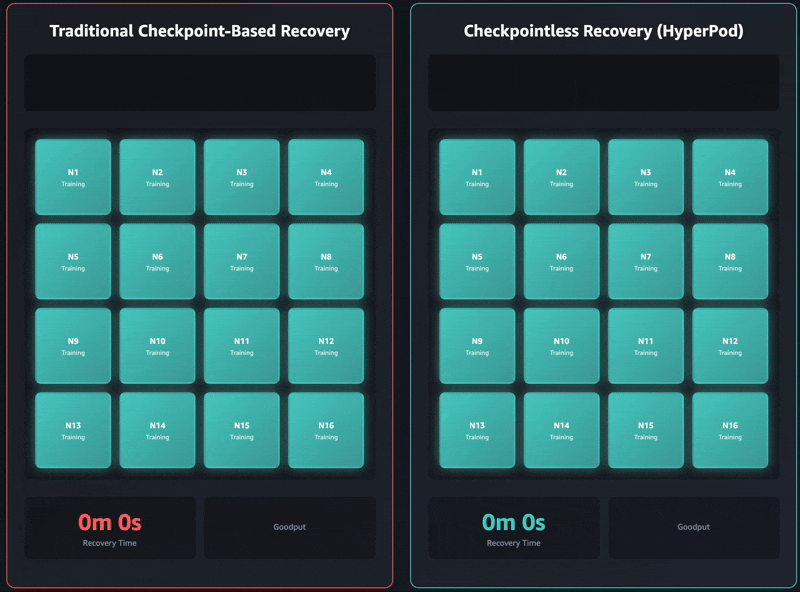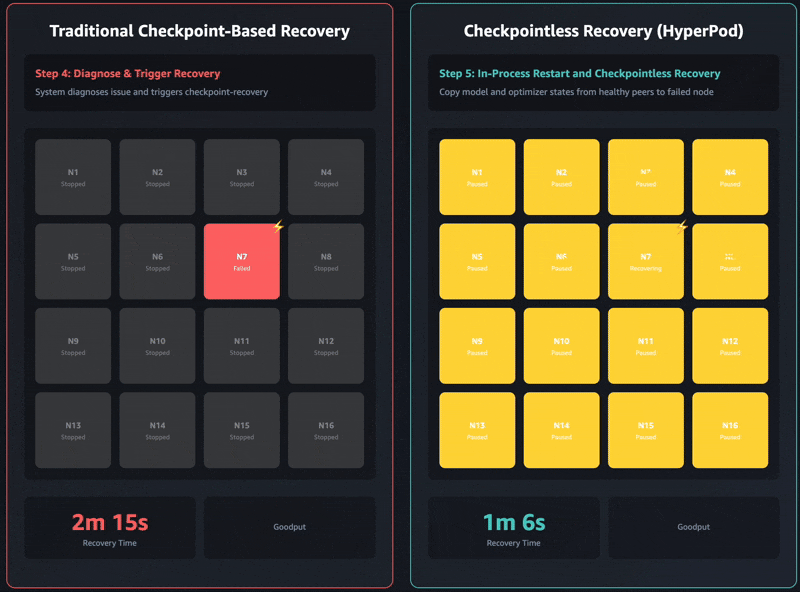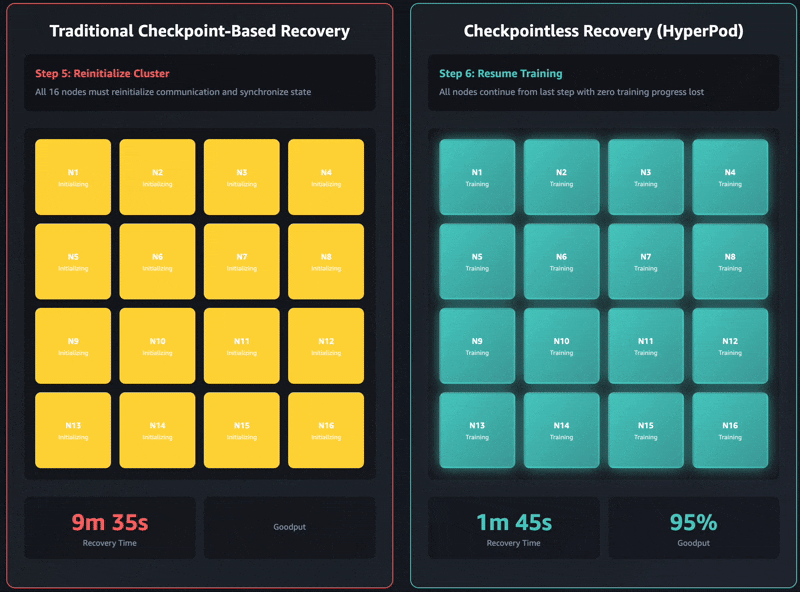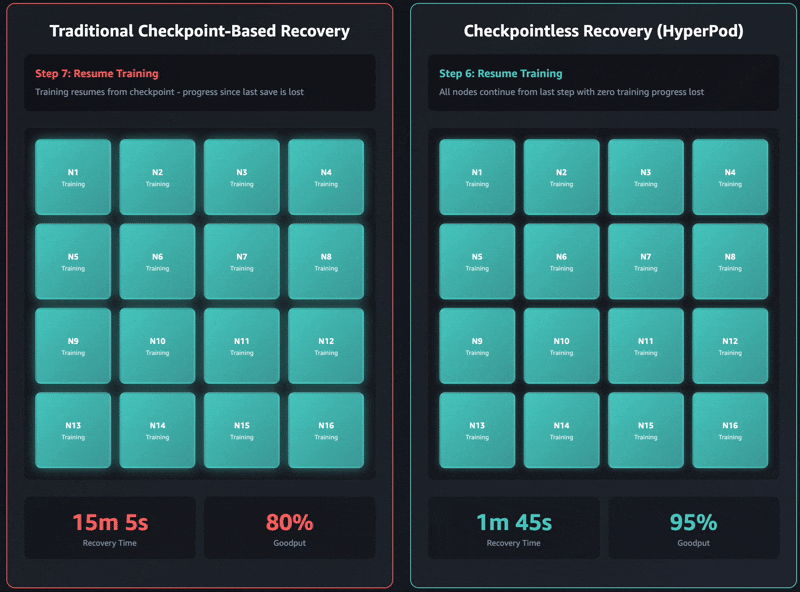
Checkpointless training is designed for incremental adoption and built on four core components that work together: 1) collective communications initialization optimizations, 2) memory-mapped data loading that enables caching, 3) in-process recovery, and 4) checkpointless peer-to-peer state replication. These components are orchestrated through the HyperPod training operator that is used to launch the job. Each component optimizes a specific step in the recovery process, and together they enable automatic detection and recovery of infrastructure faults in minutes with zero manual intervention, even with thousands of AI accelerators. You can progressively enable each of these features as your training scales.
The latest Amazon Nova models were trained using this technology on tens of thousands of accelerators. Additionally, based on internal studies on cluster sizes ranging between 16 GPUs to over 2,000 GPUs, checkpointless training showcased significant improvements in recovery times, reducing downtime by over 80% compared to traditional checkpoint-based recovery.
To learn more, visit HyperPod Checkpointless Training in the Amazon SageMaker AI Developer Guide.
Elastic training: How it works
On clusters that run different types of modern AI workloads, accelerator availability can change continuously throughout the day as short-duration training runs complete, inference spikes occur and subside, or resources free up from completed experiments. Despite this dynamic availability of AI accelerators, traditional training workloads remain locked into their initial compute allocation, unable to take advantage of idle accelerators without manual intervention. This rigidity leaves valuable GPU capacity unused and prevents organizations from maximizing their infrastructure investment.
 Elastic training transforms how training workloads interact with cluster resources. Training jobs can automatically scale up to utilize available accelerators and gracefully contract when resources are needed elsewhere, all while maintaining training quality.
Elastic training transforms how training workloads interact with cluster resources. Training jobs can automatically scale up to utilize available accelerators and gracefully contract when resources are needed elsewhere, all while maintaining training quality.
Workload elasticity is enabled through the HyperPod training operator that orchestrates scaling decisions through integration with the Kubernetes control plane and resource scheduler. It continuously monitors cluster state through three primary channels: pod lifecycle events, node availability changes, and resource scheduler priority signals. This comprehensive monitoring enables near-instantaneous detection of scaling opportunities, whether from newly available resources or requests from higher-priority workloads.
The scaling mechanism relies on adding and removing data parallel replicas. When additional compute resources become available, new data parallel replicas join the training job, accelerating throughput. Conversely, during scale-down events (for example, when a higher-priority workload requests resources), the system scales down by removing replicas rather than terminating the entire job, allowing training to continue at reduced capacity.
Across different scales, the system preserves the global batch size and adapts learning rates, preventing model convergence from being adversely impacted. This enables workloads to dynamically scale up or down to utilize available AI accelerators without any manual intervention.
You can start elastic training through the HyperPod recipes for publicly available foundation models (FMs) including Llama and GPT-OSS. Additionally, you can modify your PyTorch training scripts to add elastic event handlers, which enable the job to dynamically scale.
To learn more, visit the HyperPod Elastic Training in the Amazon SageMaker AI Developer Guide. To get started, find the HyperPod recipes available in the AWS GitHub repository.
Now available
Both features are available in all the Regions in which Amazon SageMaker HyperPod is available. You can use these training techniques without additional cost. To learn more, visit the SageMaker HyperPod product page and SageMaker AI pricing page.
Give it a try and send feedback to AWS re:Post for SageMaker or through your usual AWS Support contacts.
— Channy