A couple of editions ago I wrote about what I find so energizing about working with startups. Last week I got a fresh dose of it: I spent a few days with the AWS Startups team, listening to stories of founders talking about the problems they’re actually solving. One story that stayed with me came from Marco Negreiros, founder of EyeCare Health, a Brazilian healthtech expanding access to eye care. He shared a striking fact: more than 70% of Brazilian municipalities don’t have a single ophthalmologist. His answer was to put a vision test on the one device almost everyone already carries, the smartphone, so a basic eye screening no longer depends on living near a clinic. Watching a founder turn a gap that big into something that concrete is exactly why I love this space.

This week, I’ll take a closer look at some key launches, and then cover the quarterly AWS Service Availability updates.
Last week’s launches
Here are some of the launches covered from this past week in the AWS News Blog:
- Amazon EC2 C9g and C9gd instances powered by AWS Graviton5 processors: They deliver up to 25% better compute performance than Graviton4-based instances, 5x larger cache, fastest memory of any processor instances in the cloud, and local NVMe storage options (C9gd).
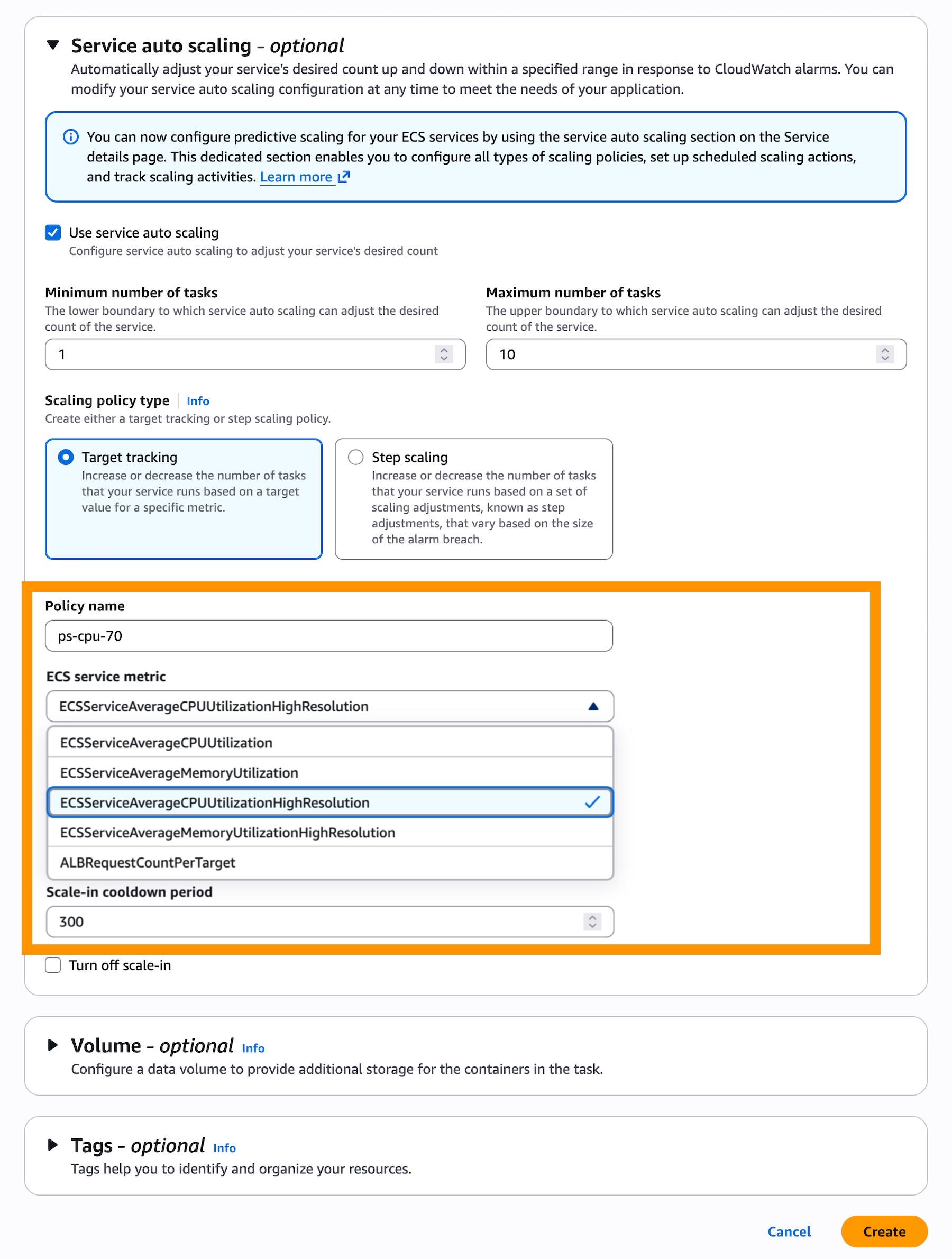
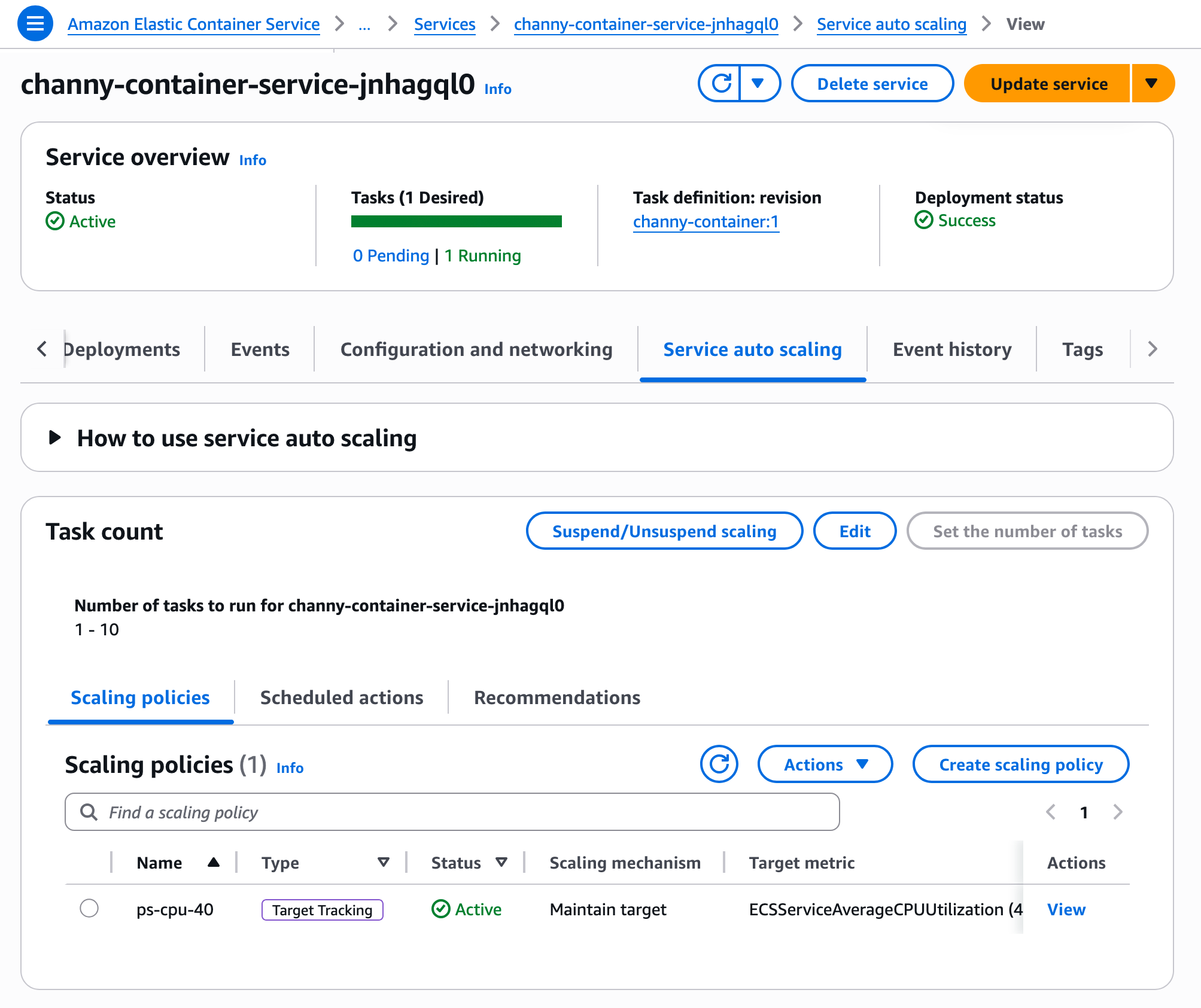
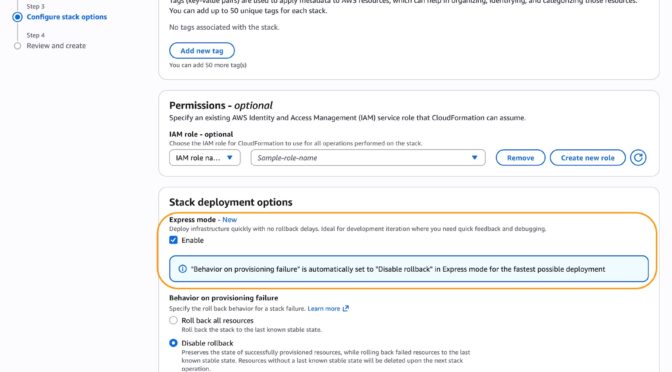
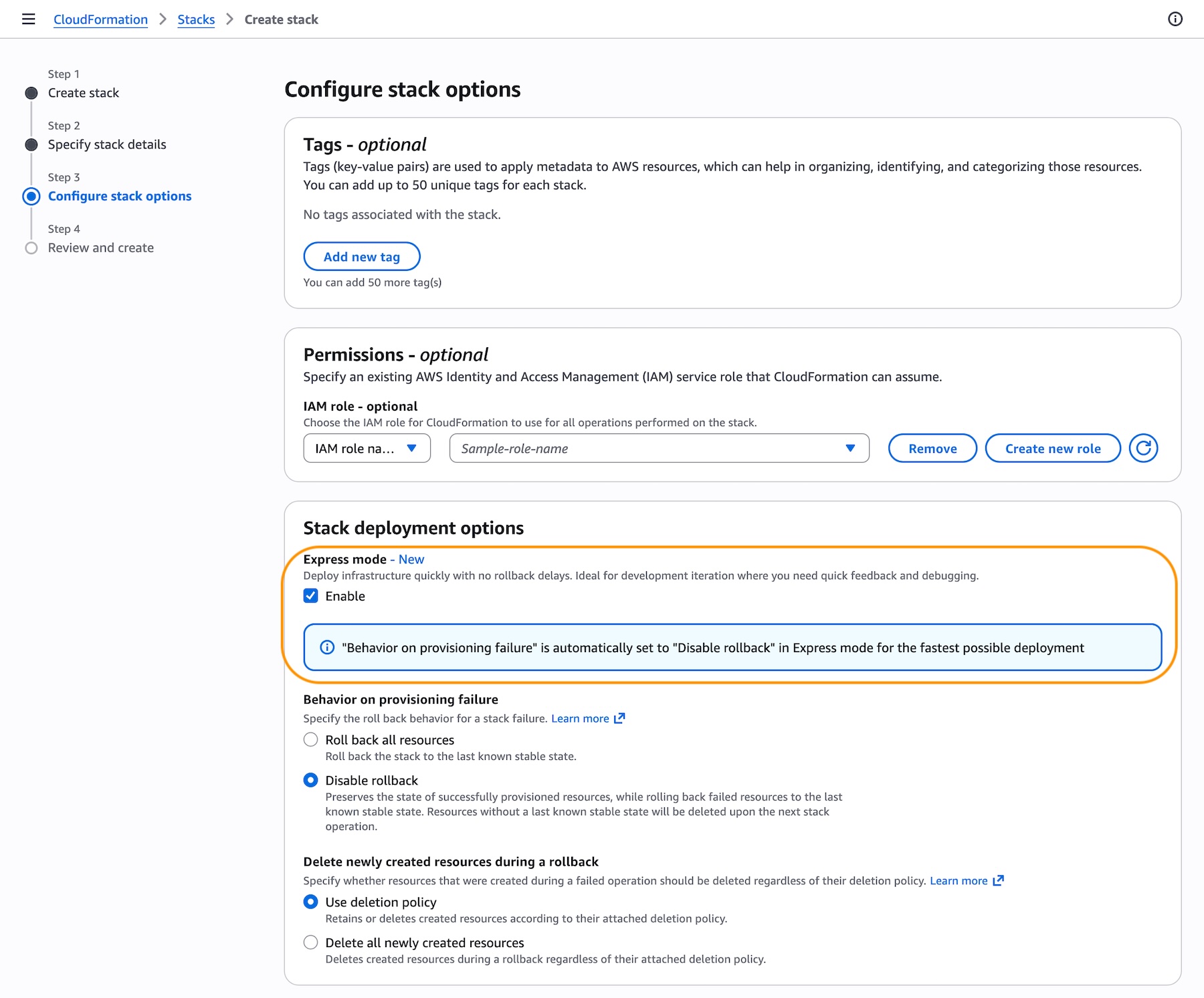
- A new AWS CloudFormation Express mode: You can speed up infrastructure deployment with AWS CloudFormation Express mode, enabling AI agents and developers to receive deployment confirmation in seconds and iterate faster. Available in all commercial Regions at no additional cost.
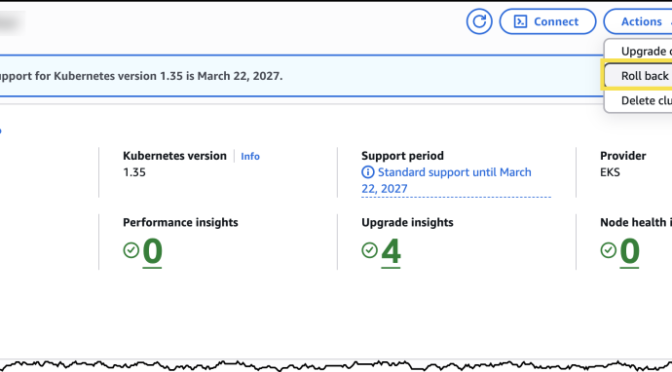
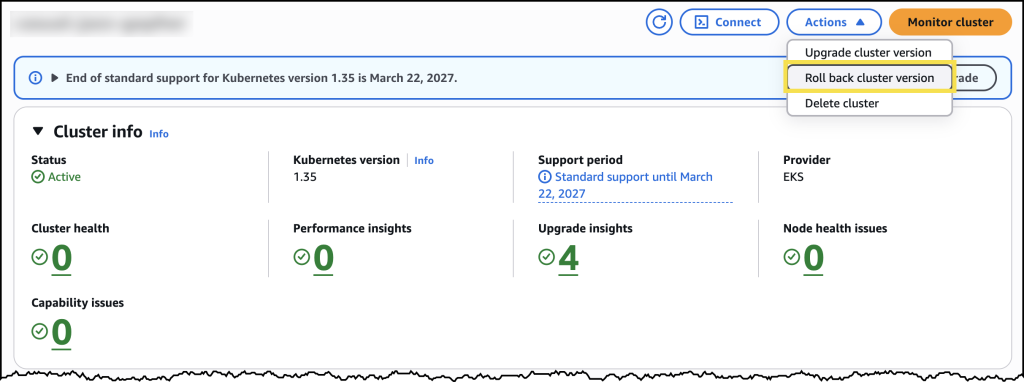
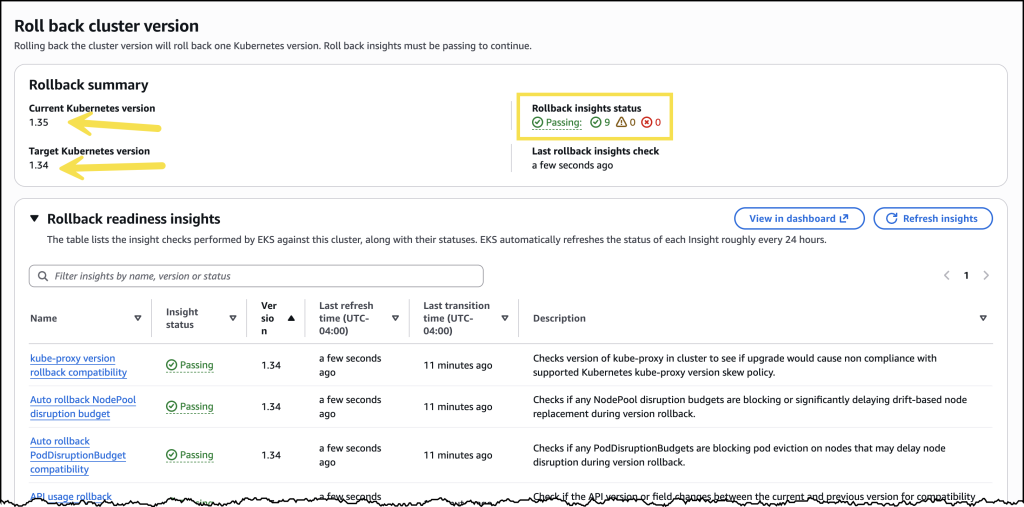
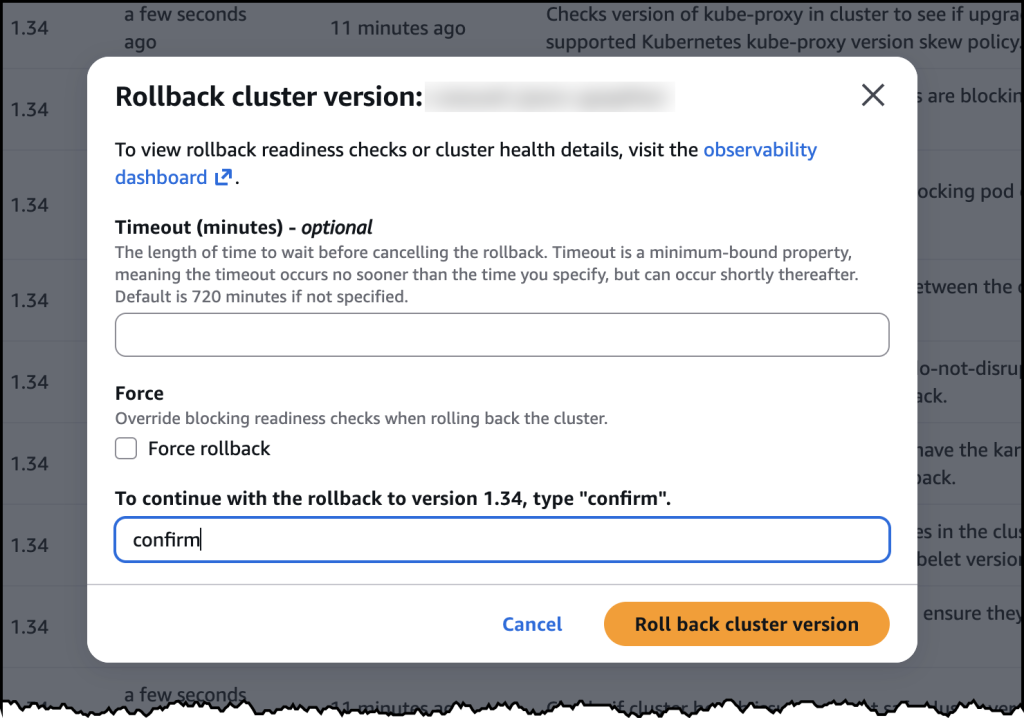
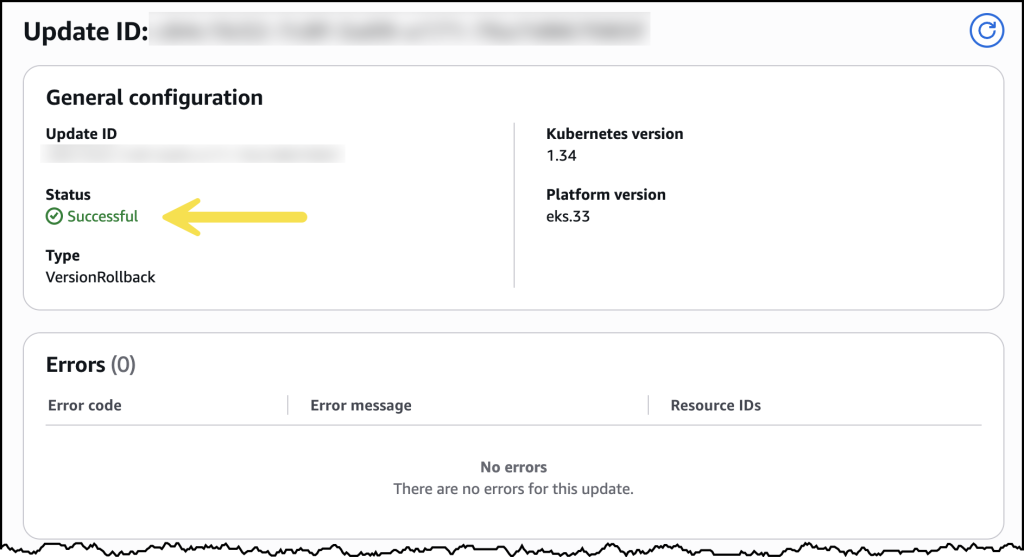
- Upgrade Amazon EKS clusters with confidence using Kubernetes version rollbacks: Learn how Kubernetes version rollbacks for Amazon EKS let you reverse cluster upgrades within seven days. This new feature provides a safety net for upgrade failures, no cluster rebuilds required, turning Kubernetes version upgrades into a reversible, low-risk operation.
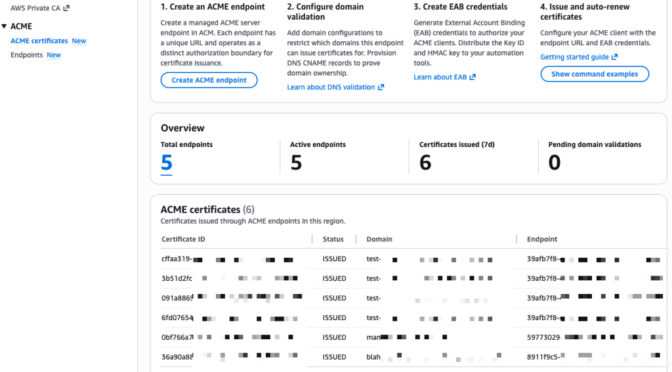
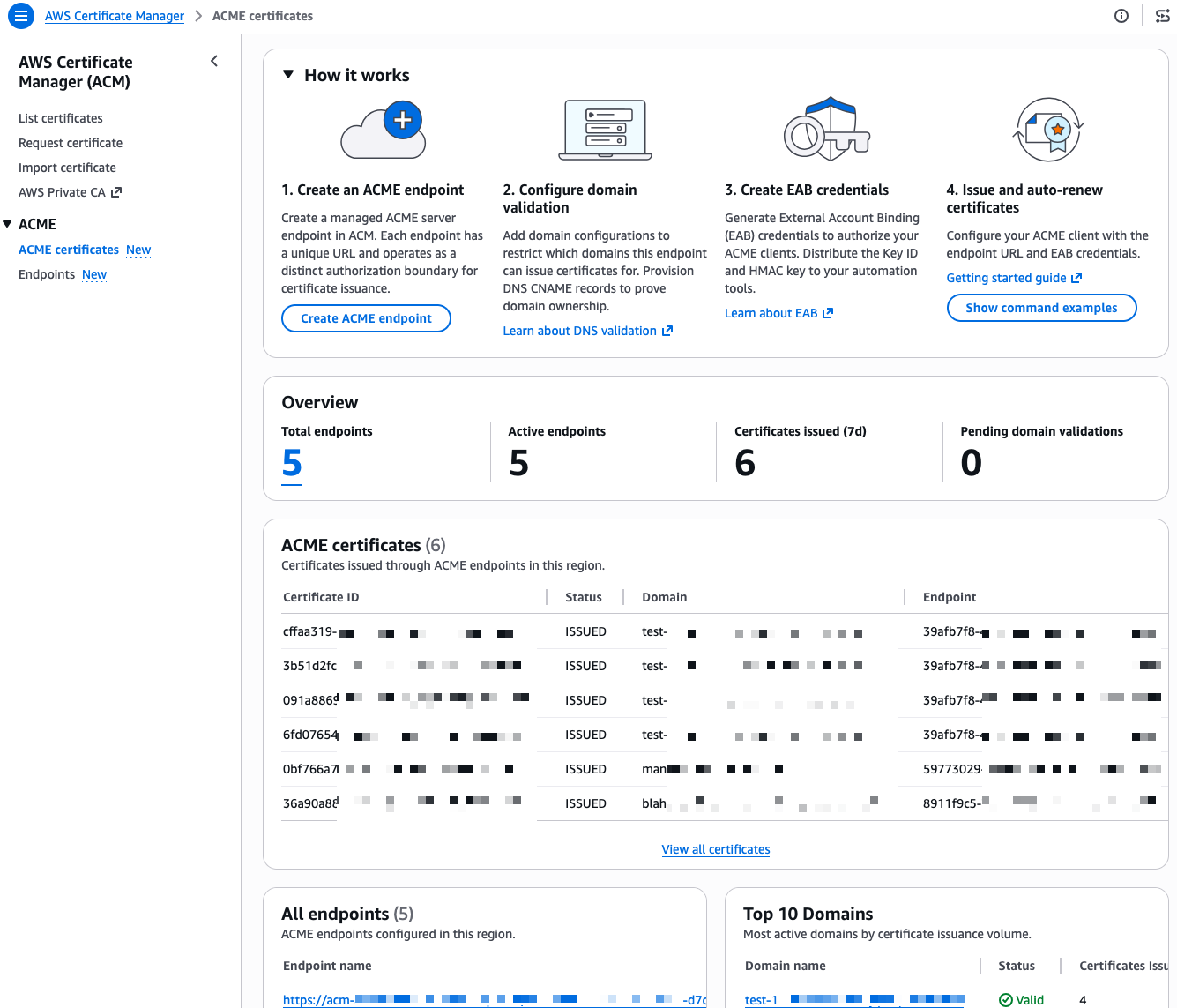
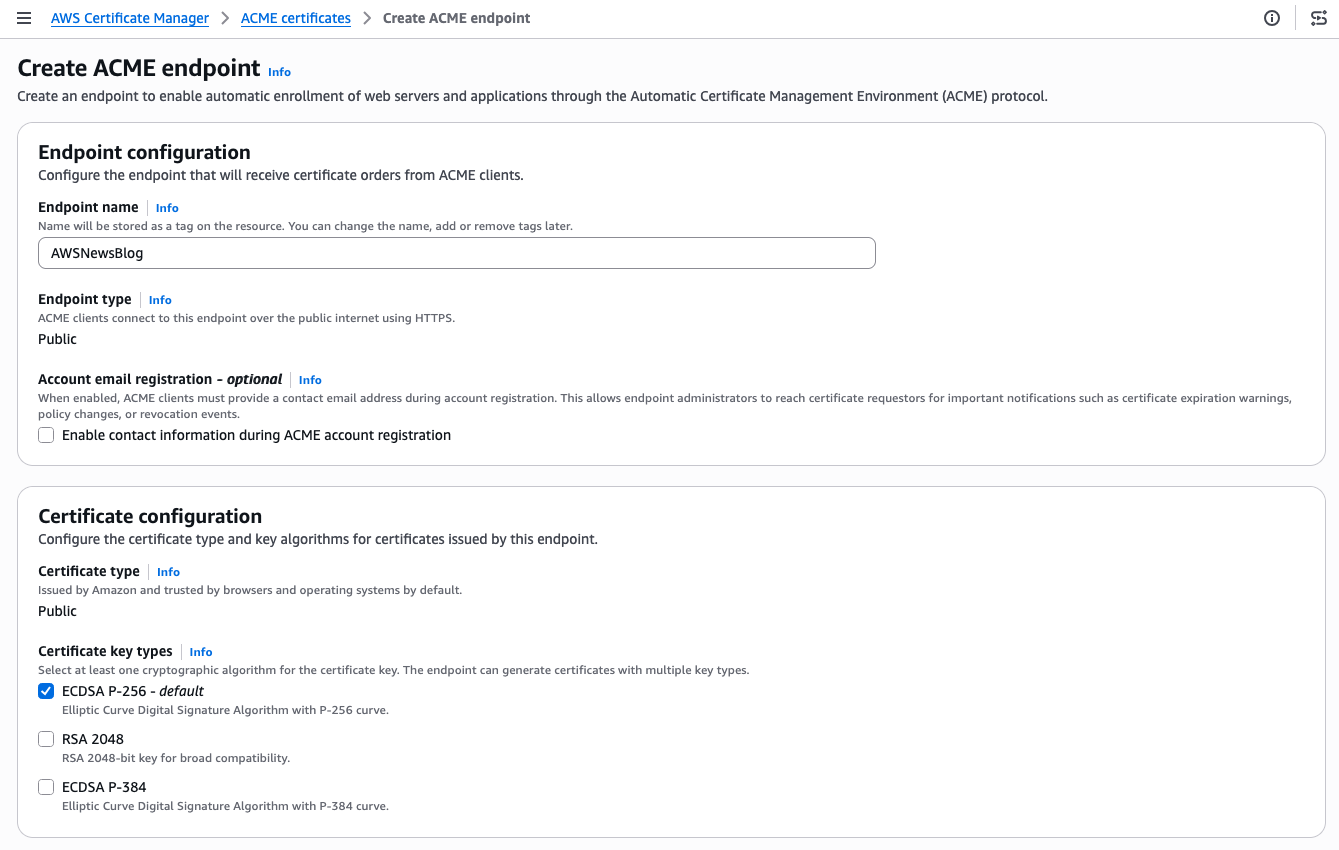
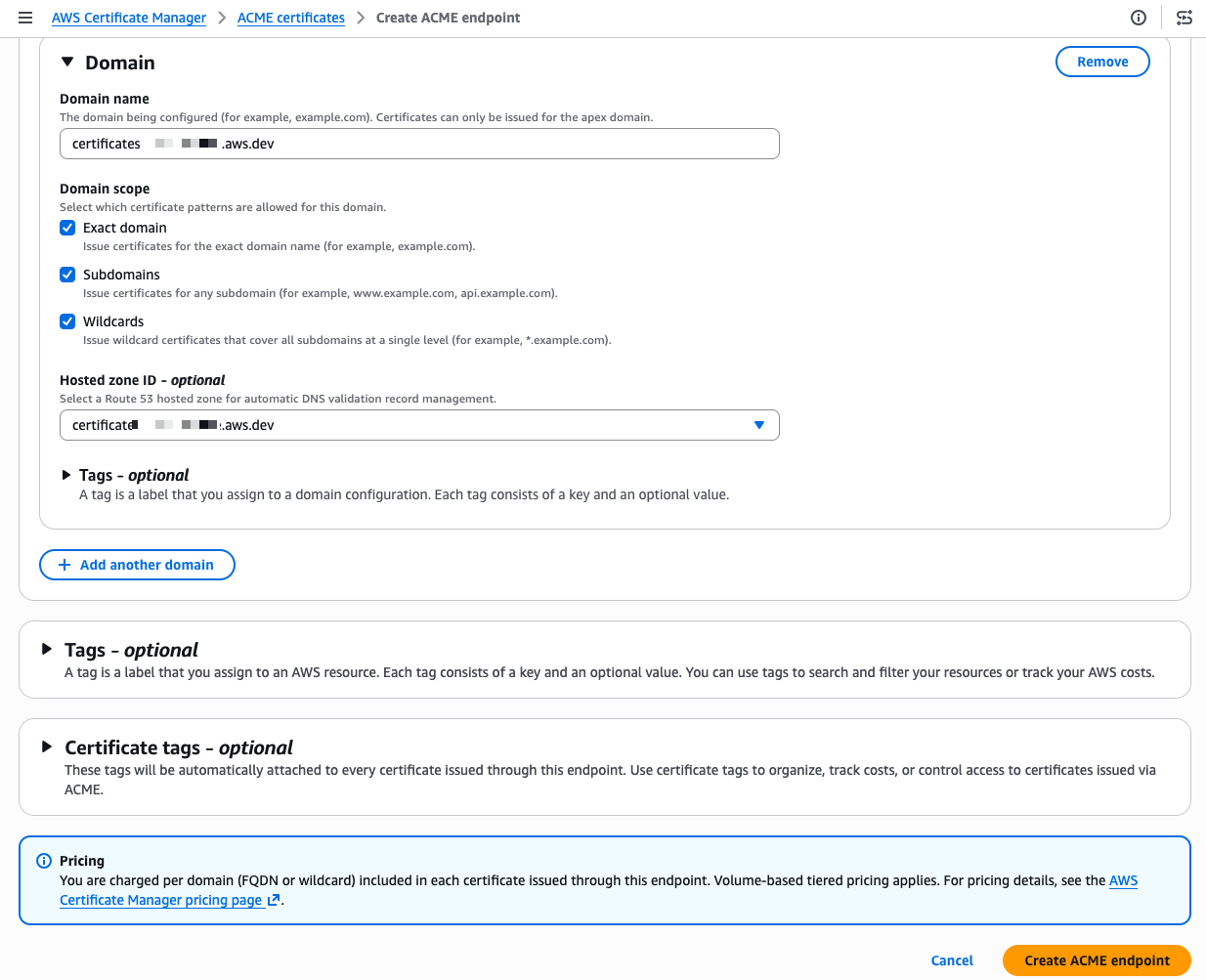
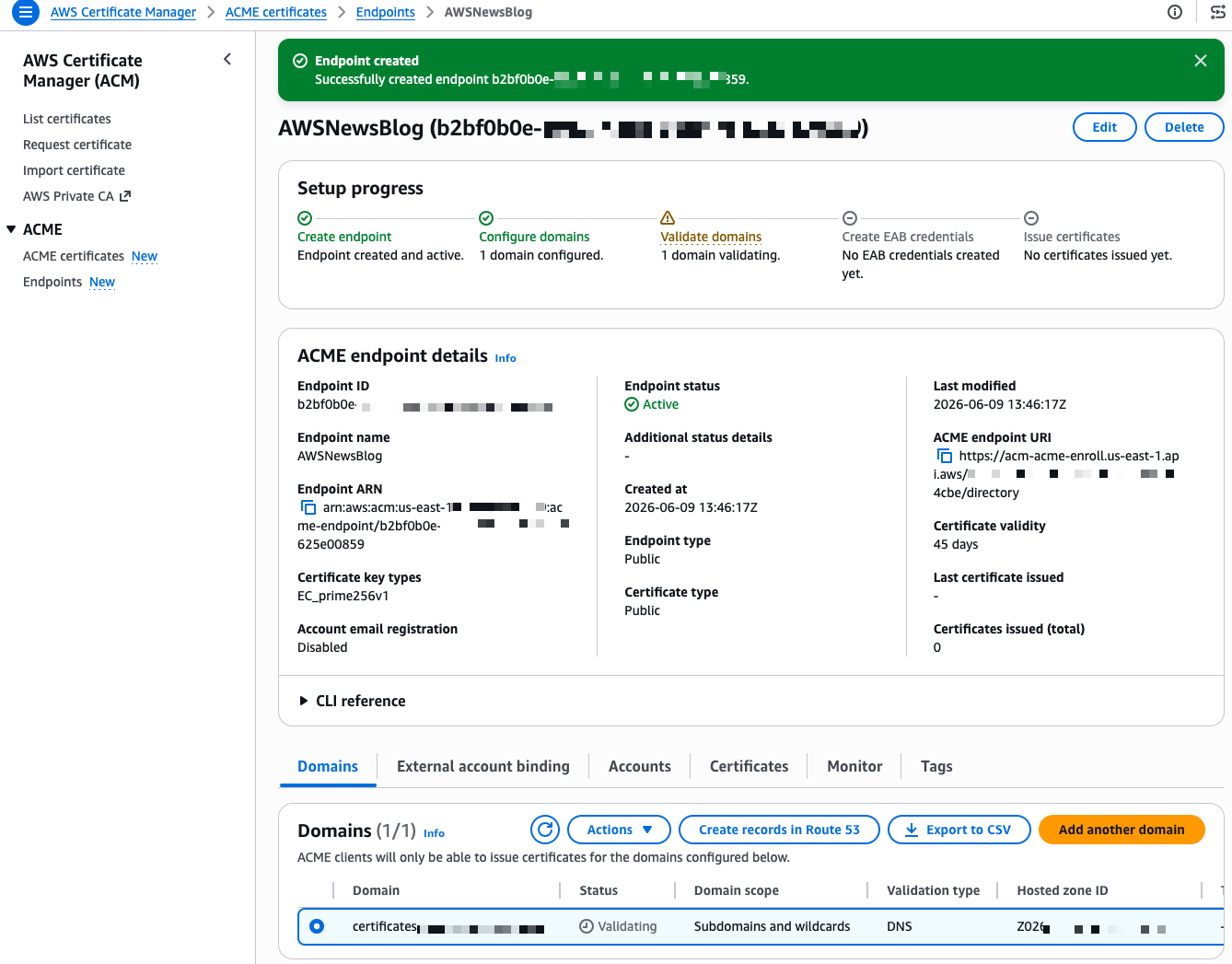
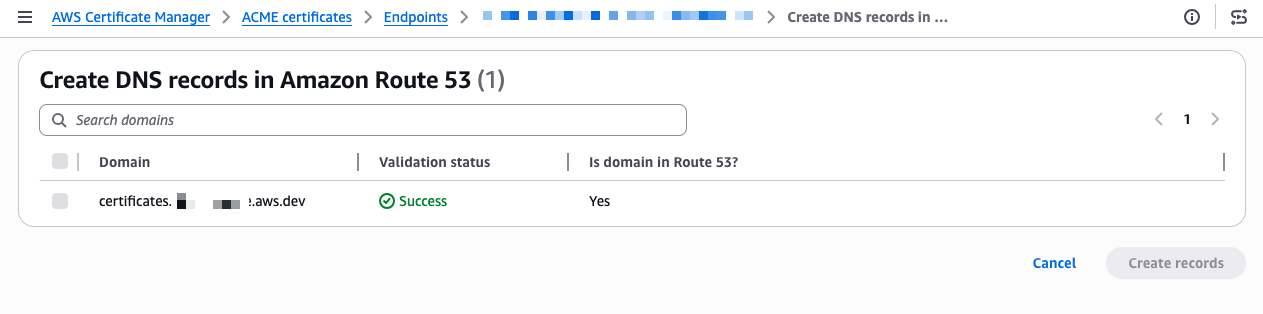
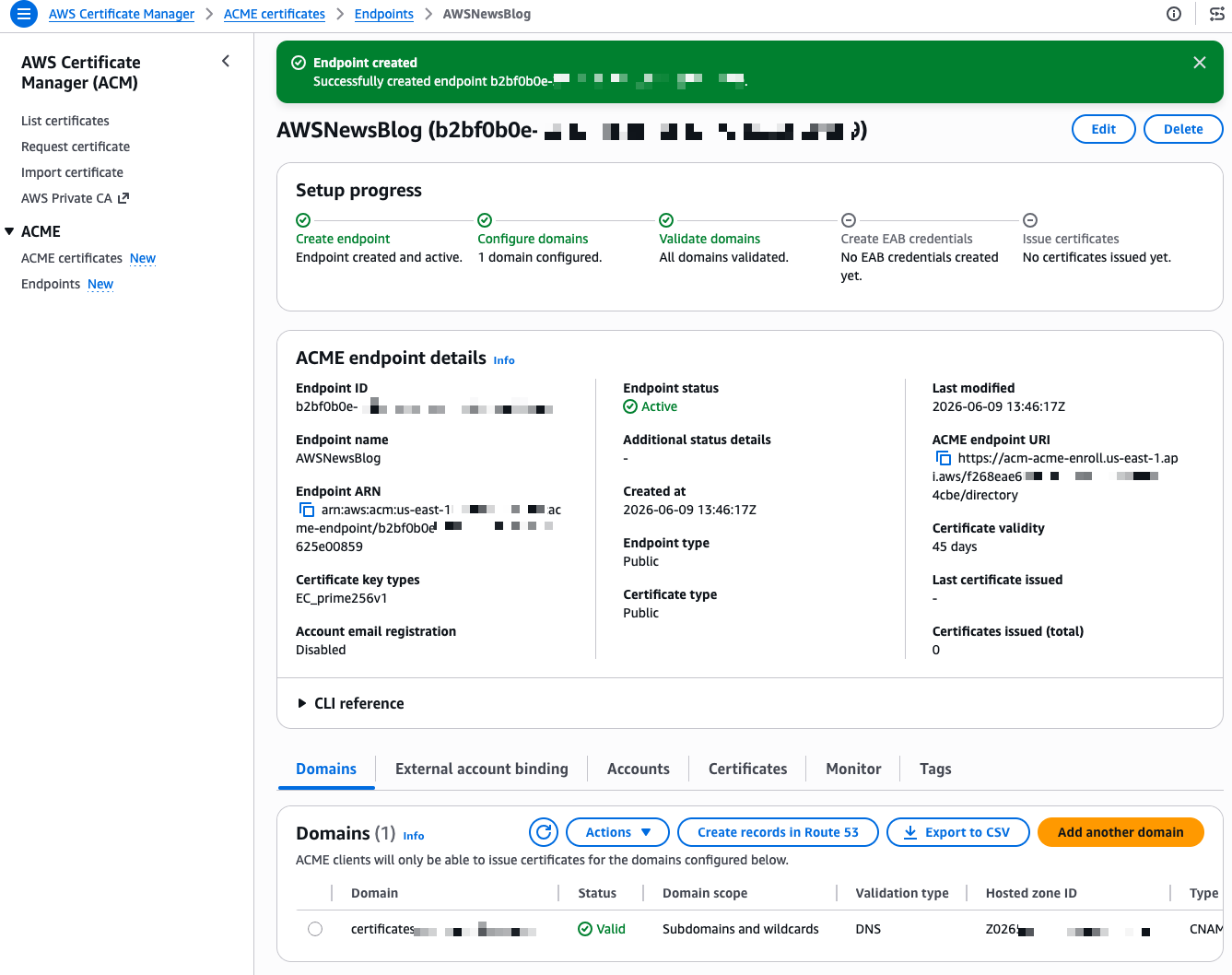
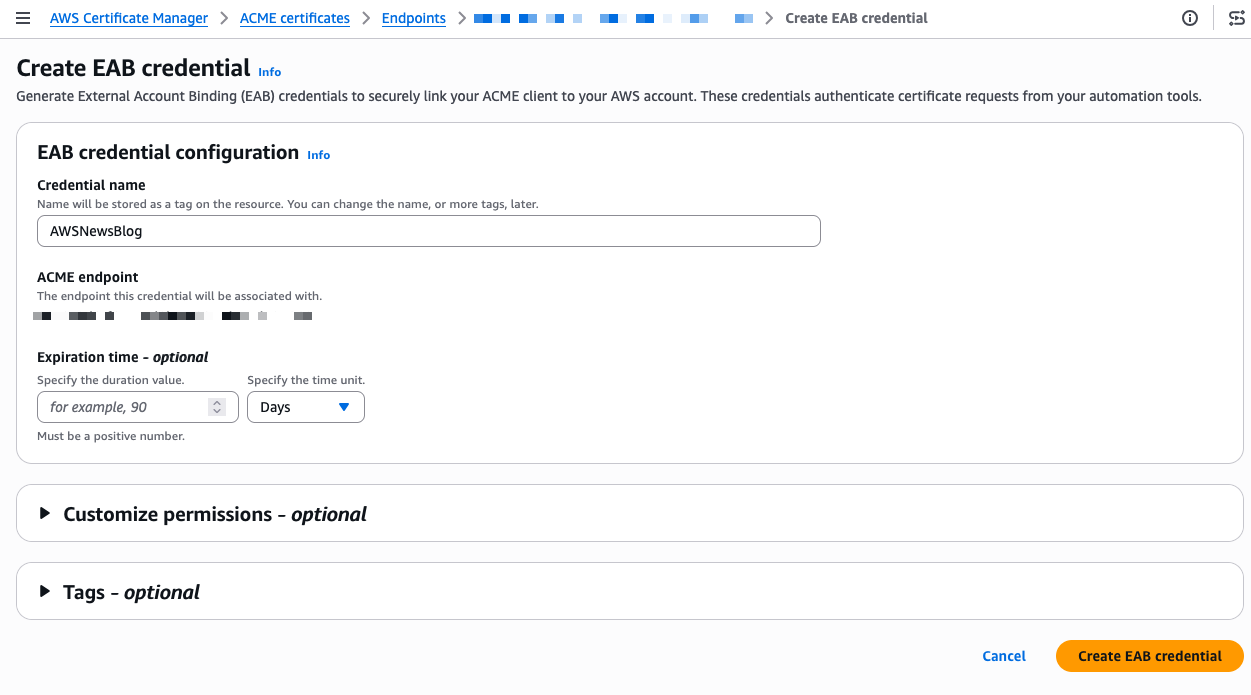
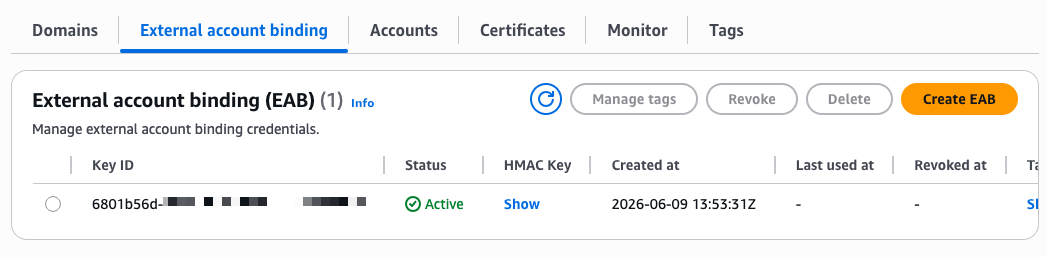
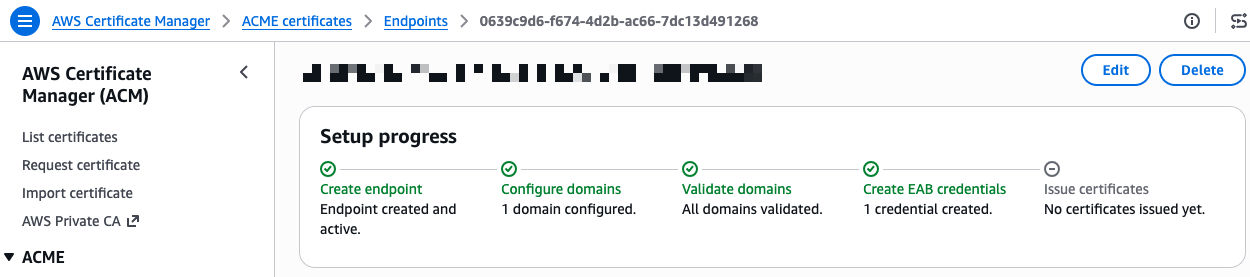
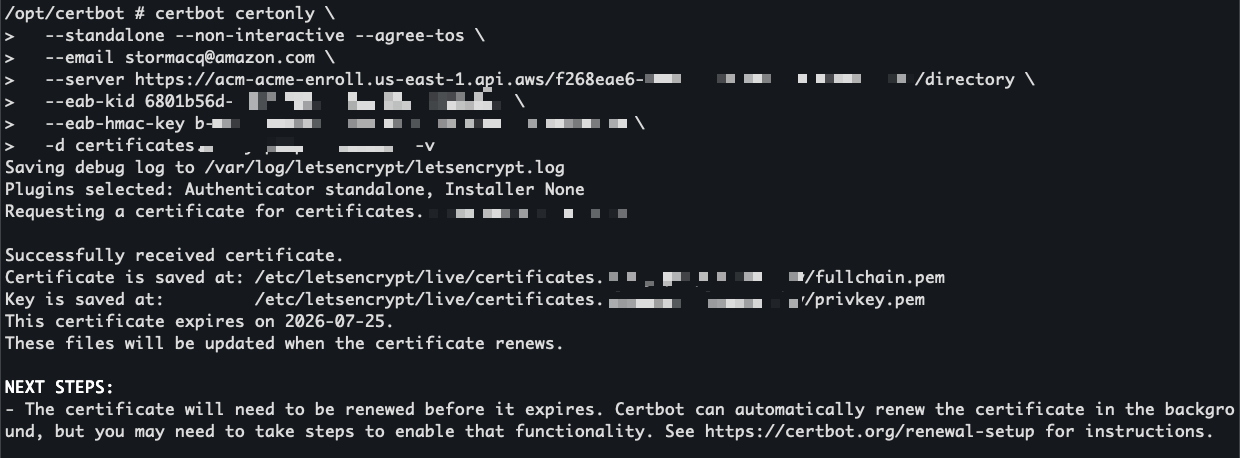
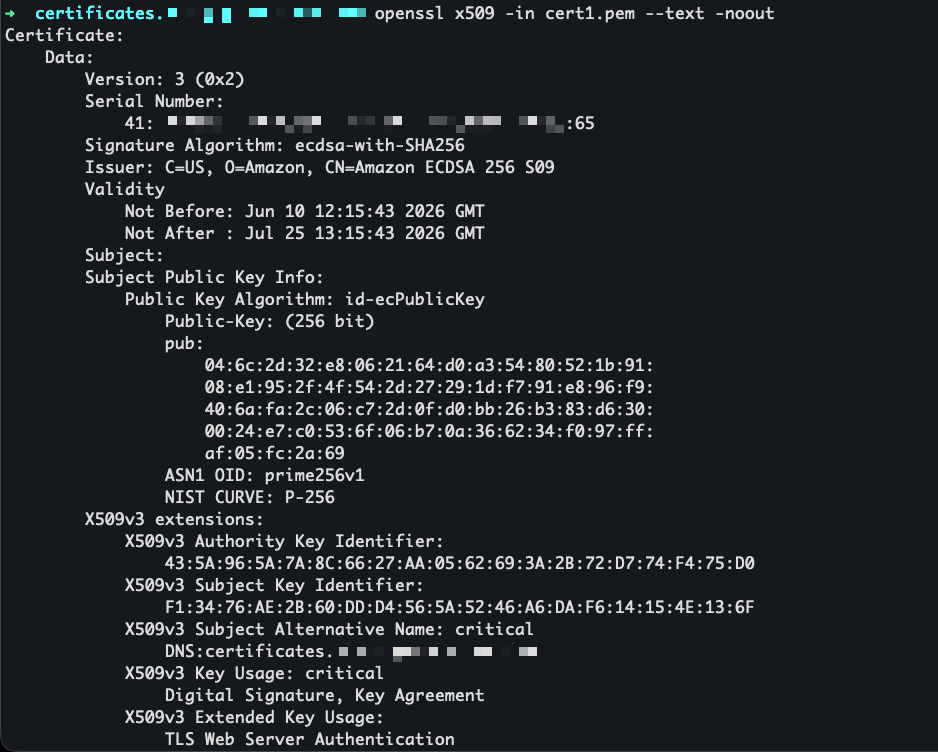
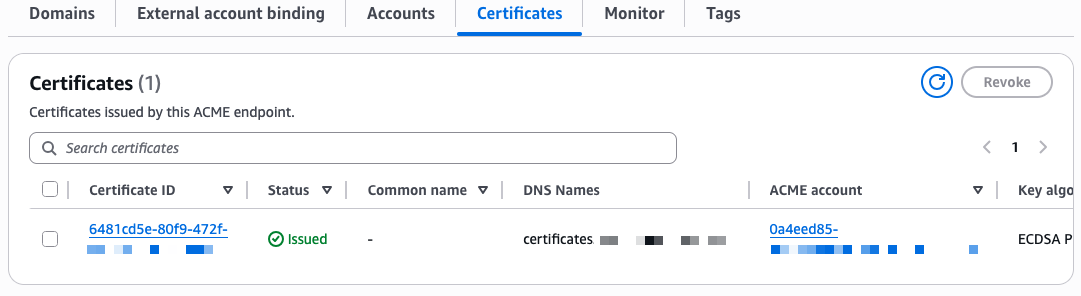
- Automate public TLS certificate issuance with ACME support in AWS Certificate Manager: AWS Certificate Manager now supports the ACME protocol, so you can automate the issuance and renewal of public TLS certificates using standard, widely adopted tooling.
Here are some launches and updates that caught my attention:
- Claude Sonnet 5 is now available on AWS – Anthropic’s most capable Sonnet model brings top-tier intelligence at Sonnet pricing for coding, agents, and everyday professional work at scale. It navigates large codebases, calls tools precisely, and holds state across long agentic tasks. To learn more, visit the AI Blog post.
- Amazon WorkSpaces for AI agents is now generally available: AI agents can now securely access and operate desktop applications through managed WorkSpaces environments, without requiring application modernization or custom integrations. To learn more. visit the Desktop and Application Streaming Blog post.
- Amazon OpenSearch Service is now optimized for log analytics: This release introduces a new engine purpose-built for log analytics workloads that delivers up to 4x better price-performance on internal benchmarks, while keeping the full-text search capabilities OpenSearch is known for. Teams can now get aggregations and precise text search in one place. To learn more, visit the Big Data Blog post.
- Amazon SageMaker AI cuts generative AI inference scale-out time by up to half: SageMaker Inference now supports container image caching, enabling up to 2x faster end-to-end scaling for generative AI models during scale-out events. To learn more, visit the AI Blog post.
- Amazon CloudWatch supports creating alarms from log queries : You can now create alarms directly on log query results and set thresholds in a single workflow, eliminating the need to first create metric filters or custom metrics as intermediate steps.
For a full list of AWS announcements, be sure to keep an eye on the What’s New with AWS page.
AWS Service Availability Updates
When the availability of an AWS service or feature changes, we provide customers guidance in AWS Product Lifecycle Changes on available alternatives and support for migration so that disruptions to your operations are minimized. The following lifecycle changes were updated on June 30, 2026.
Services moving to Maintenance (no longer accessible to new customers starting July 30, 2026):
- Amazon Bedrock Agents (launched November 2023) is now Amazon Bedrock Agents Classic
- Amazon Cognito Sync
- Amazon Kendra
- Amazon Q Business
- AWS Directory Service – Simple AD
- AWS IoT Device Defender – Detect (feature will no longer be accessible to new customers starting August 31, 2026)
- AWS Mainframe Modernization – Self-Managed Experience
- AWS Management Console – myApplications
- AWS Resource Groups – Group Lifecycle Events
- AWS Service Catalog – Application Registry
- AWS Systems Manager – Application Manager
- Amazon SageMaker AI features: A2I, Clarify, Debugger, GeoSpatial, Ground Truth, Mechanical Turk, Model Monitor, Role Manager, and Studio Lab
Services entering Sunset:
- Amazon WorkSpaces – PCoIP
- Amazon WorkSpaces – Pool
- AWS Managed Services (AMS) Advanced
- AWS re:Post Private
- Amazon Sagemaker AI- Profiler
Services reaching End of Support (as of June 30, 2026):
- Amazon Chime SDK – Carrier Voice Focus
- Amazon SageMaker AI – Ground Truth Plus
We understand that changes in availability can impact your operations. For specific guidance, consult the relevant service documentation or contact AWS Support.
Upcoming AWS events
Check your calendar and sign up for upcoming AWS events:
- AWS Summits – AWS Summits are free events that bring the cloud and AI community together to connect, learn, and explore the latest technologies. Browse the full calendar to find a Summit near you in the second half of 2026.
- AWS Community Days – Community-led conferences where content is planned, sourced, and delivered by community leaders. If you’re in Latin America, don’t miss AWS Community Day Belo Horizonte on August 22. Registration is open at awscommunityday.com.br.
Join the AWS Builder Center to connect with builders, share solutions, and access content that supports your development. Browse here for upcoming AWS-led in-person and virtual events and developer-focused events.
That’s all for this week. Check back next Monday for another Weekly Roundup!
– Daniel Abib
This post is part of our Weekly Roundup series. Check back each week for a quick roundup of interesting news and announcements from AWS!

 It has been a busy stretch on the AWS Summit circuit. At the
It has been a busy stretch on the AWS Summit circuit. At the