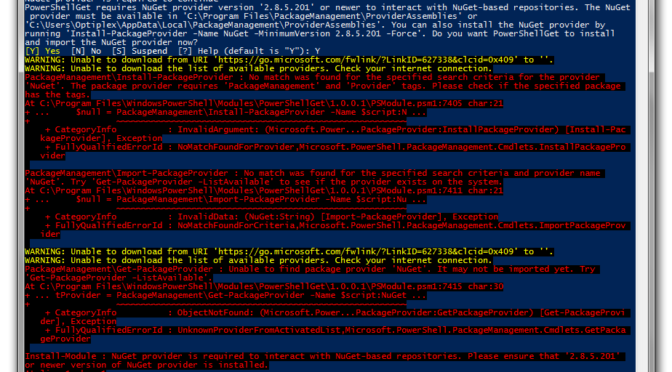
Recently there’s been a number of users who have encountered a particular bug with PowerShellGet 1.0.0.1 in Windows PowerShell.
This bug occurs when you try to to use a PowerShellGet cmdlet that is dependent on PackageManagement,
including cmdlets such as Find-Module, Install-Module, Save-Module, etc. Running any of these cmdlets will prompt you to install
the NuGet provider that both PowerShellGet and PackageManagement are dependent on. Even though the prompt offers two ways to
install the provider– you can run ‘Y’ to have PowerShellGet automatically install the provider, or you can run
‘Install-PackageProvider’ yourself– both of these suggestions fail.
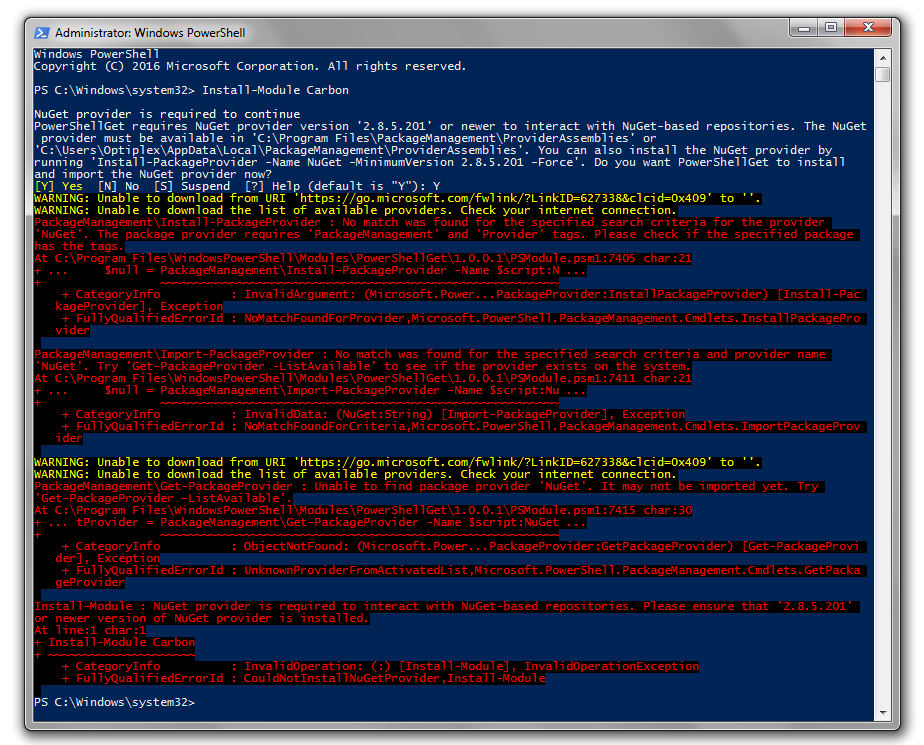
But, again, even when attempting to explicitly install the package provider, the process command fails.
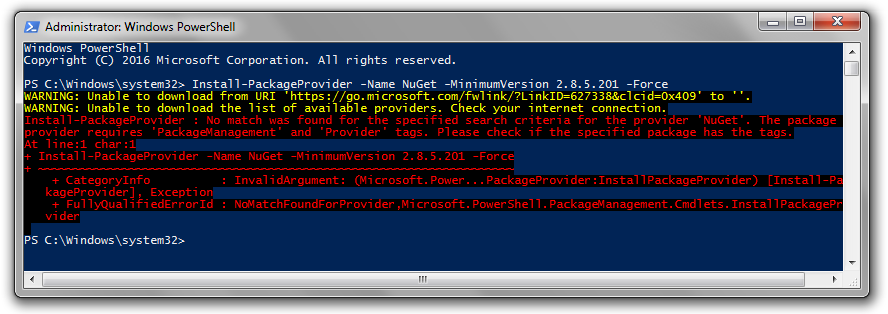
The earliest version of PackageManagement (version 1.0.0.1) did not ship with the NuGet provider, so any use of PowerShellGet also required that the NuGet provider be bootstrapped or explicitly installed. Understandably, it can be a source of deep frustration when the tool you use to install packages is dependent on a package that it cannot install.
The underlying issue here is that the remote endpoint used to bootstrap the provider requires TLS 1.2 and the client may not have it enabled. The two options below should help you resolve any issues encountered when attempting to install the NuGet provider and get back up and running again with PowerShellGet!
How to find the versions you’re using
You can find out what version of PowerShellGet and PackageManagement you’re using by running:
Get-Module PowerShellGet, PackageManagement -ListAvailableThe output will be order by priority, so if multiple paths are displayed, the top first path will be the one that gets referenced during an import.
If the version of PackageManagement you’re using is 1.0.0.1 then this issue will likely apply to you.
Option 1: Change your TLS version to 1.2
The easiest thing to do here is to update the TLS version on your machine. It’s highly recommended to use this option, but if necessary you can manually install PackageManagement as outlined under Option 2.
If you only want to update the current PowerShell session you can run:
[Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::Tls12After running this command you can run
[Net.ServicePointManager]::SecurityProtocolTo validate that TLS12 is being used.
Once TLS 1.2 is enabled, you can successfully run the original command.
If you prefer to update your client so that you don’t need to run the command above in every PowerShell session, you can follow the instructions laid out here.
Option 2: Manually update PackageManagement
You can also update PackageManagement to a version that ships with the NuGet provider– that is PackageManagement 1.1.0.0 or later.
Simply go to the PackageManagement package page on the PowerShell Gallery and under “Installation Options”, click on the “Manual Download” tab and then “Download the raw nupkg file”.
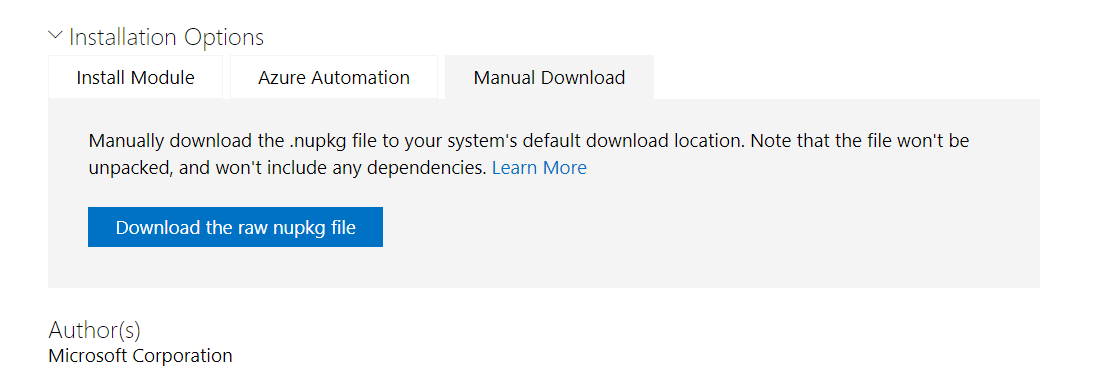
You can then go to your downloads folder and unzip the .nupkg.
You can then move the folder into your modules path. To find out what this specific path is, follow the steps specified in “How to find the versions you’re using” above. Use the first path listed.
Create a folder under the PackageManagement directory listed here. This new folder should have the same name as the PackageManagement version that was downloaded. For example, in the case above, under “C:Program FilesWindowsPowerShellModulePackageManagement” you would create a directory named “1.1.0.0”. You can then place the contents of the unzipped nupkg into this newly created version directory.
After doing this, start a fresh session of PowerShell or run:
Import-Module PackageManagement -ForceYou’re good to go
After completing either option 1 or 2 you should find your issue resolved. If not feel free to reach out via GitHub or Twitter.
The post When PowerShellGet v1 fails to install the NuGet Provider appeared first on PowerShell Team.