On July 13, 2006, we launched Amazon Simple Queue Service (Amazon SQS) as one of the first three services available to customers, alongside Amazon EC2 and Amazon S3. We had learned firsthand that distributed systems need a reliable way to pass messages between components without creating tight dependencies. If one service called another directly and that service was slow or unavailable, failures cascaded through the entire system. Message queuing solved this by letting services communicate asynchronously: a producer could drop a message into a queue and move on, while a consumer picked it up when ready. This approach kept individual service failures from affecting the rest of the system.
When Amazon SQS launched publicly in July 2006, it made this pattern available to every AWS customer. Twenty years later, that core function, decoupling producers from consumers, remains the reason customers use SQS. The scale, performance, and operational controls around it look very different now though.
Jeff Barr covered the first 15 years of SQS milestones in his 15th anniversary post, from the original 8 KB message limit in 2006 through FIFO queues, server-side encryption, and Lambda integration. Over the last five years, we have continued to scale SQS, added stronger security defaults, and introduced new capabilities that address increasingly complex workload patterns.
Key milestones between 2021 and 2026
High throughput mode for FIFO queues (2021): In May 2021, we launched general availability of high throughput mode for FIFO queues, supporting up to 3,000 transactions per second (TPS) per API action, a tenfold increase over the previous limit. We continued raising this ceiling over the following two years: to 6,000 TPS in October 2022, to 9,000 TPS in August 2023, and to 18,000 TPS in October 2023, before reaching 70,000 TPS per API action in select Regions by November 2023.
Server-side encryption with SSE-SQS (2021): In November 2021, we introduced server-side encryption with Amazon SQS-managed encryption keys (SSE-SQS), giving customers an encryption option that required no key management. In October 2022, we made SSE-SQS the default for all newly created queues, so customers no longer needed to explicitly enable it.
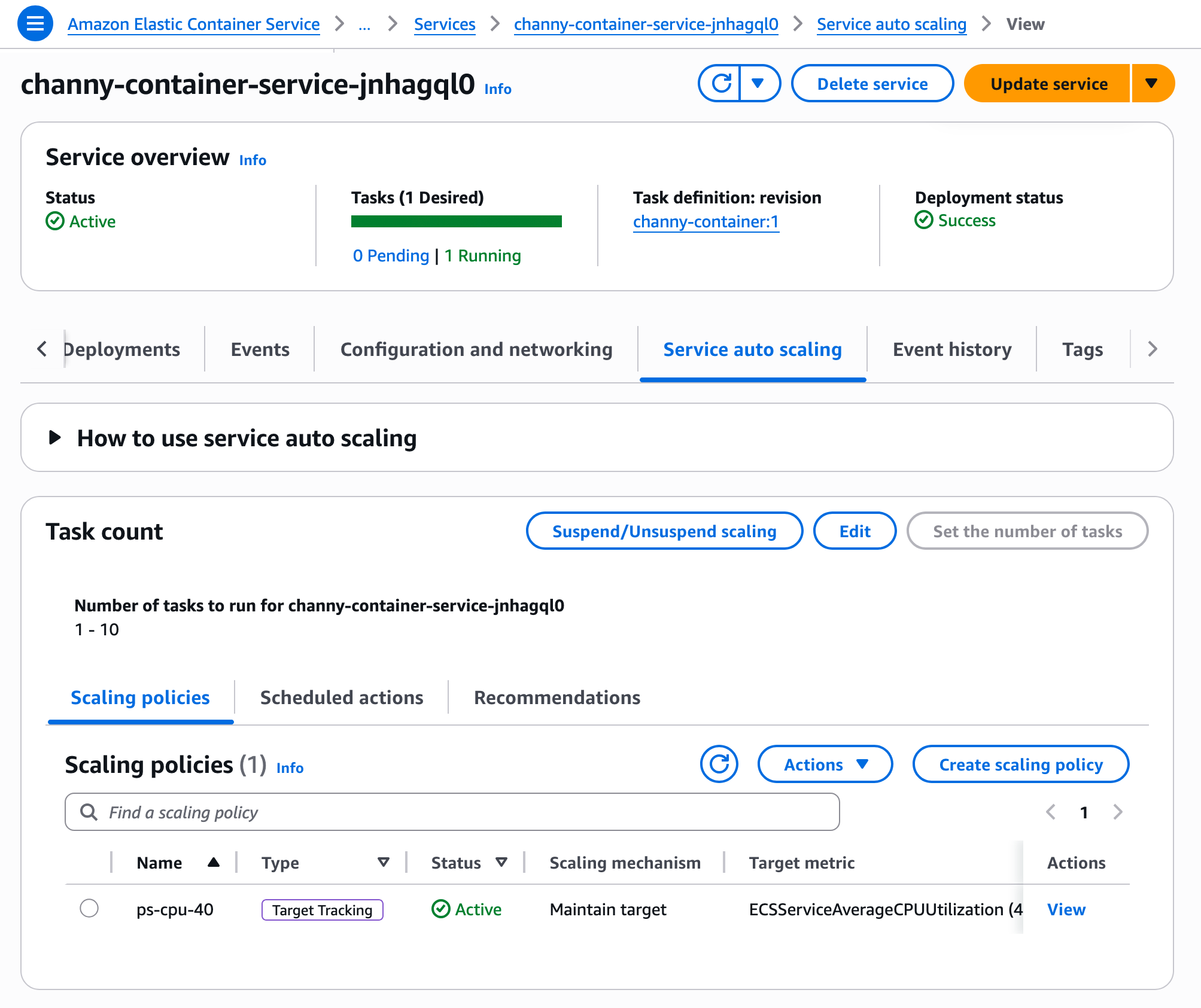
Dead-letter queue redrive enhancements (2021): We progressively expanded how customers recover unconsumed messages from dead-letter queues. In December 2021, we added DLQ redrive to source queue directly in the SQS console. In June 2023, we extended this capability to the AWS SDK and CLI through new APIs, including StartMessageMoveTask, CancelMessageMoveTask, and ListMessageMoveTasks. In November 2023, we added redrive support for FIFO queues.
Attribute-based access control, ABAC (2022): In November 2022, we introduced ABAC, giving customers the ability to configure access permissions based on queue tags rather than maintaining static policies as resources scaled.
JSON protocol support (2023): In November 2023, we added support for the JSON protocol in the AWS SDK, reducing end-to-end message processing latency by up to 23% for a 5 KB payload and lowering client-side CPU and memory usage.
Amazon EventBridge Pipes console integration (2023): We added the ability to connect a queue directly to EventBridge Pipes from the SQS console, routing messages to a broad range of AWS service targets without writing custom integration code.
Extended Client Library for Python (2024): We brought the Extended Client Library, previously available for Java, to Python developers, allowing messages up to 2 GB to be sent through SQS by storing the payload in Amazon S3 and passing a reference through the queue.
FIFO in-flight message limit increase (2024): We increased the in-flight message limit for FIFO queues from 20,000 to 120,000 messages, so consumers can process significantly more messages concurrently without being constrained by the previous ceiling.
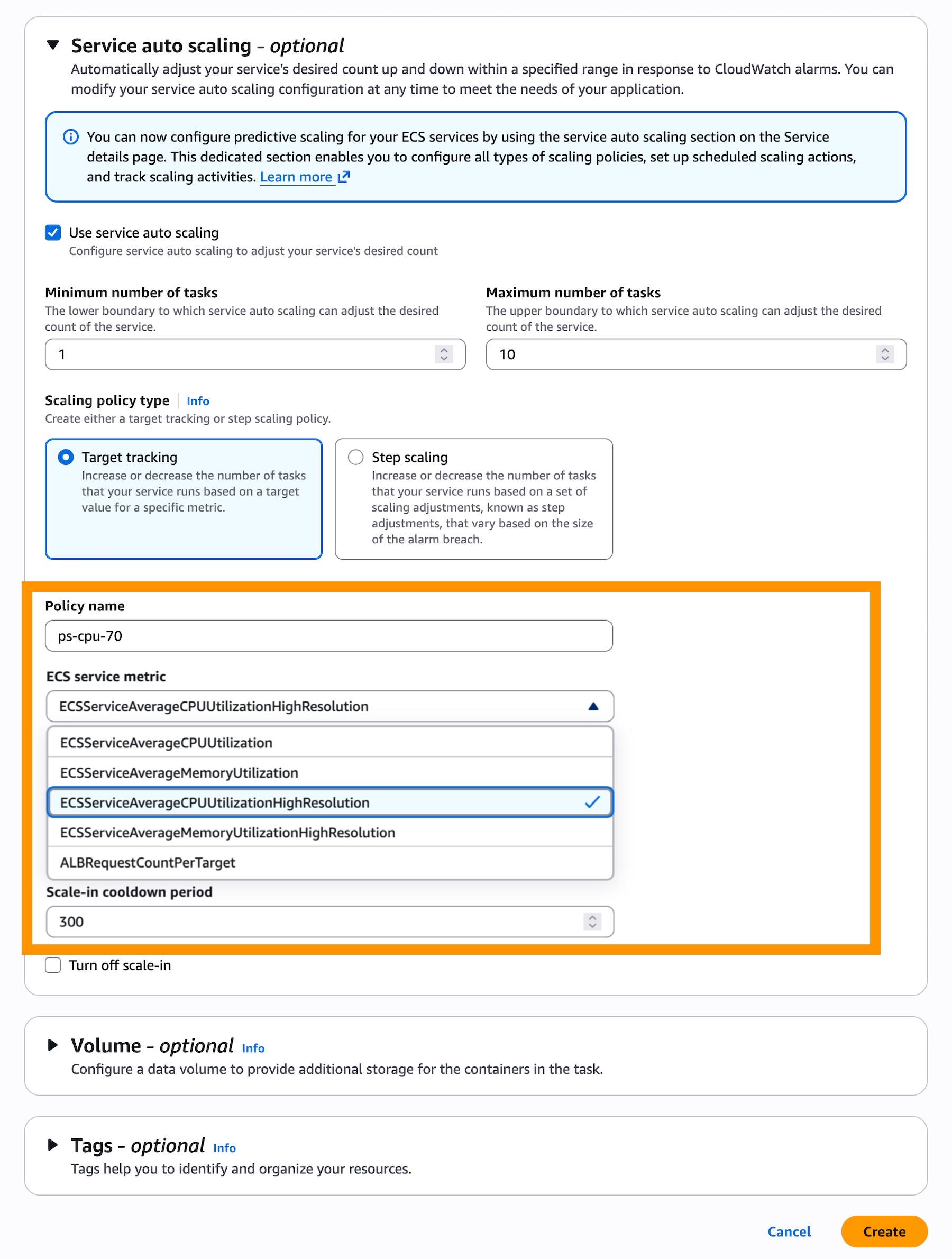
Fair queues for multi-tenant workloads (2025): We introduced fair queues to mitigate the noisy neighbor problem in multi-tenant standard queues. By including a message group ID when sending messages, customers can prevent a single tenant from delaying message delivery for others, without any changes required on the consumer side.
1 MiB maximum message payload size (2025): We increased the maximum message payload from 256 KiB to 1 MiB for both standard and FIFO queues, helping customers send larger messages without offloading data to external storage. AWS Lambda event source mapping for SQS was updated in parallel to support the new payload size.
The constant underneath the change
Despite two decades of feature additions, the fundamental use case for SQS has not shifted. Customers use it to decouple services, buffer bursts of traffic, and build systems that stay resilient when individual components fail. That same pattern now extends to AI workloads. Customers use SQS queues to buffer requests to large language models, manage inference throughput, and coordinate communication between autonomous AI agents operating as independent services. For an example of this architecture in practice, read Creating asynchronous AI agents with Amazon Bedrock.
To learn more about Amazon SQS, visit the Amazon SQS product page, review the developer guide, or explore recent updates on the AWS Blogs.



 It has been a busy stretch on the AWS Summit circuit. At the
It has been a busy stretch on the AWS Summit circuit. At the