
Today, we’re announcing the general availability of an additional 18 fully managed open weight models in Amazon Bedrock from Google, MiniMax AI, Mistral AI, Moonshot AI, NVIDIA, OpenAI, and Qwen, including the new Mistral Large 3 and Ministral 3 3B, 8B, and 14B models.
With this launch, Amazon Bedrock now provides nearly 100 serverless models, offering a broad and deep range of models from leading AI companies, so customers can choose the precise capabilities that best serve their unique needs. By closely monitoring both customer needs and technological advancements, we regularly expand our curated selection of models based on customer needs and technological advancements to include promising new models alongside established industry favorites.

This ongoing expansion of high-performing and differentiated model offerings helps customers stay at the forefront of AI innovation. You can access these models on Amazon Bedrock through the unified API, evaluate, switch, and adopt new models without rewriting applications or changing infrastructure.
New Mistral AI models
These four Mistral AI models are now available first on Amazon Bedrock, each optimized for different performance and cost requirements:
- Mistral Large 3 – This open weight model is optimized for long-context, multimodal, and instruction reliability. It excels in long document understanding, agentic and tool use workflows, enterprise knowledge work, coding assistance, advanced workloads such as math and coding tasks, multilingual analysis and processing, and multimodal reasoning with vision.
- Ministral 3 3B – The smallest in the Ministral 3 family is edge-optimized for single GPU deployment with strong language and vision capabilities. It shows robust performance in image captioning, text classification, real-time translation, data extraction, short content generation, and lightweight real-time applications on edge or low-resource devices.
- Ministral 3 8B – The best-in-class Ministral 3 model for text and vision is edge-optimized for single GPU deployment with high performance and minimal footprint. This model is ideal for chat interfaces in constrained environments, image and document description and understanding, specialized agentic use cases, and balanced performance for local or embedded systems.
- Ministral 3 14B – The most capable Ministral 3 model delivers state-of the-art text and vision performance optimized for single GPU deployment. You can use advanced local agentic use cases and private AI deployments where advanced capabilities meet practical hardware constraints.
More open weight model options
You can use these open weight models for a wide range of use cases across industries:
| Model provider | Model name | Description | Use cases |
| Gemma 3 4B | Efficient text and image model that runs locally on laptops. Multilingual support for on-device AI applications. | On-device AI for mobile and edge applications, privacy-sensitive local inference, multilingual chat assistants, image captioning and description, and lightweight content generation. | |
| Gemma 3 12B | Balanced text and image model for workstations. Multi-language understanding with local deployment for privacy-sensitive applications. | Workstation-based AI applications; local deployment for enterprises; multilingual document processing, image analysis and Q&A; and privacy-compliant AI assistants. | |
| Gemma 3 27B | Powerful text and image model for enterprise applications. Multi-language support with local deployment for privacy and control. | Enterprise local deployment, high-performance multimodal applications, advanced image understanding, multilingual customer service, and data-sensitive AI workflows. | |
| Moonshot AI | Kimi K2 Thinking | Deep reasoning model that thinks while using tools. Handles research, coding and complex workflows requiring hundreds of sequential actions. | Complex coding projects requiring planning, multistep workflows, data analysis and computation, and long-form content creation with research. |
| MiniMax AI | MiniMax M2 | Built for coding agents and automation. Excels at multi-file edits, terminal operations and executing long tool-calling chains efficiently. | Coding agents and integrated development environment (IDE) integration, multi-file code editing, terminal automation and DevOps, long-chain tool orchestration, and agentic software development. |
| Mistral AI | Magistral Small 1.2 | Excels at math, coding, multilingual tasks, and multimodal reasoning with vision capabilities for efficient local deployment. | Math and coding tasks, multilingual analysis and processing, and multimodal reasoning with vision. |
| Voxtral Mini 1.0 | Advanced audio understanding model with transcription, multilingual support, Q&A, summarization, and function-calling. | Voice-controlled applications, fast speech-to-text conversion, and offline voice assistants. | |
| Voxtral Small 1.0 | Features state-of-the-art audio input with best-in-class text performance; excels at speech transcription, translation, and understanding. | Enterprise speech transcription, multilingual customer service, and audio content summarization. | |
| NVIDIA | NVIDIA Nemotron Nano 2 9B | High efficiency LLM with hybrid transformer Mamba design, excelling in reasoning and agentic tasks. | Reasoning, tool calling, math, coding, and instruction following. |
| NVIDIA Nemotron Nano 2 VL 12B | Advanced multimodal reasoning model for video understanding and document intelligence, powering Retrieval-Augmented Generation (RAG) and multimodal agentic applications. | Multi-image and video understanding, visual Q&A, and summarization. | |
| OpenAI | gpt-oss-safeguard-20b | Content safety model that applies your custom policies. Classifies harmful content with explanations for trust and safety workflows. | Content moderation and safety classification, custom policy enforcement, user-generated content filtering, trust and safety workflows, and automated content triage. |
| gpt-oss-safeguard-120b | Larger content safety model for complex moderation. Applies custom policies with detailed reasoning for enterprise trust and safety teams. | Enterprise content moderation at scale, complex policy interpretation, multilayered safety classification, regulatory compliance checking, high-stakes content review. | |
| Qwen | Qwen3-Next-80B-A3B | Fast inference with hybrid attention for ultra-long documents. Optimized for RAG pipelines, tool use & agentic workflows with quick responses. | RAG pipelines with long documents, agentic workflows with tool calling, code generation and software development, multi-turn conversations with extended context, multilingual content generation. |
| Qwen3-VL-235B-A22B | Understands images and video. Extracts text from documents, converts screenshots to working code, and automates clicking through interfaces. | Extracting text from images and PDFs, converting UI designs or screenshots to working code, automating clicks and navigation in applications, video analysis and understanding, reading charts and diagrams. |
When implementing publicly available models, give careful consideration to data privacy requirements in your production environments, check for bias in output, and monitor your results for data security, responsible AI, and model evaluation.
You can access the enterprise-grade security features of Amazon Bedrock and implement safeguards customized to your application requirements and responsible AI policies with Amazon Bedrock Guardrails. You can also evaluate and compare models to identify the optimal models for your use cases by using Amazon Bedrock model evaluation tools.
To get started, you can quickly test these models with a few prompts in the playground of the Amazon Bedrock console or use any AWS SDKs to include access to the Bedrock InvokeModel and Converse APIs. You can also use these models with any agentic framework that supports Amazon Bedrock and deploy the agents using Amazon Bedrock AgentCore and Strands Agents. To learn more, visit Code examples for Amazon Bedrock using AWS SDKs in the Amazon Bedrock User Guide.
Now available
Check the full Region list for availability and future updates of new models or search your model name in the AWS CloudFormation resources tab of AWS Capabilities by Region. To learn more, check out the Amazon Bedrock product page and the Amazon Bedrock pricing page.
Give these models a try in the Amazon Bedrock console today and send feedback to AWS re:Post for Amazon Bedrock or through your usual AWS Support contacts.
— Channy
 .
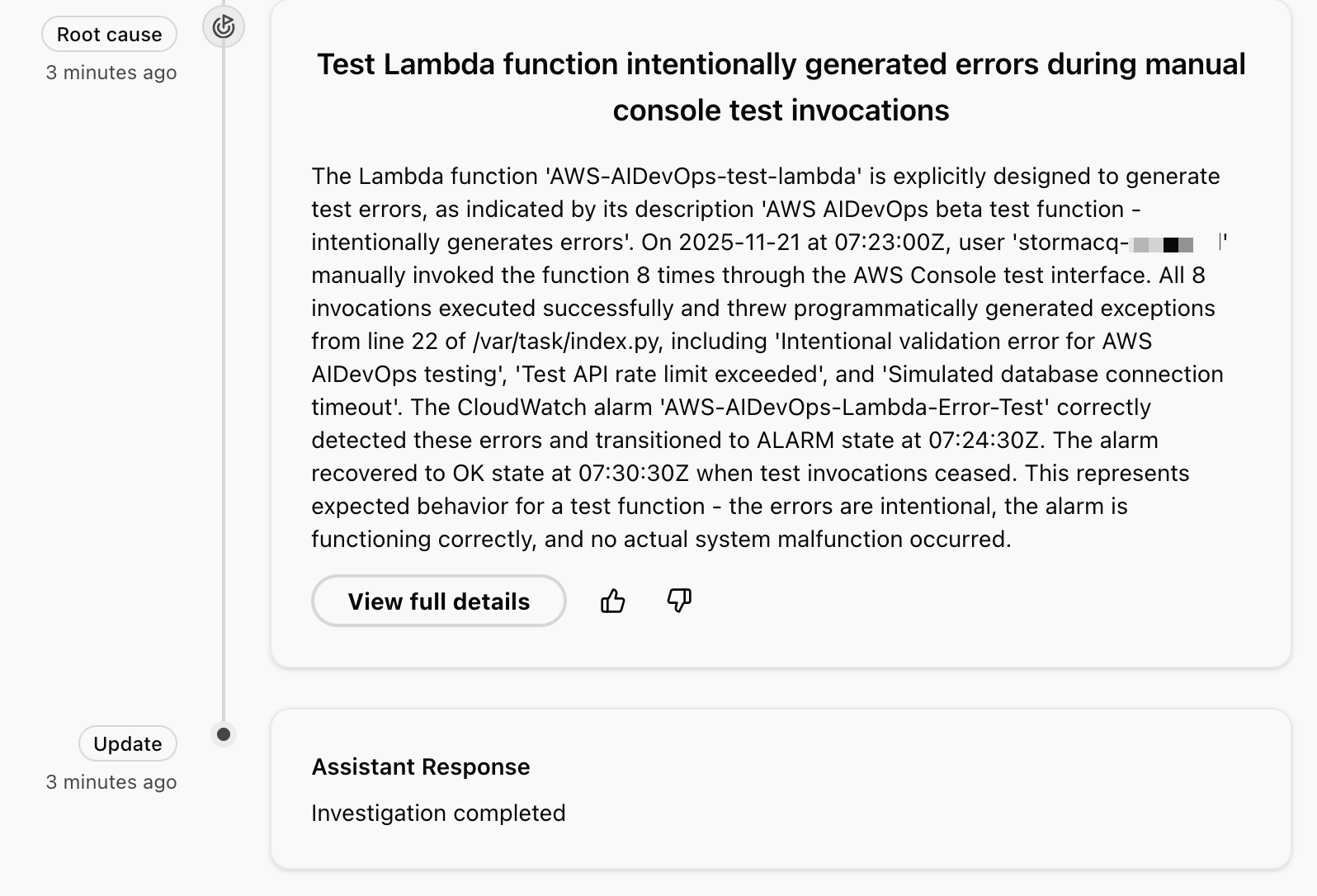
.









{kind=link}