Today, we are introducing Amazon SageMaker HyperPod, which helps reducing time to train foundation models (FMs) by providing a purpose-built infrastructure for distributed training at scale. You can now use SageMaker HyperPod to train FMs for weeks or even months while SageMaker actively monitors the cluster health and provides automated node and job resiliency by replacing faulty nodes and resuming model training from a checkpoint.
The clusters come preconfigured with SageMaker’s distributed training libraries that help you split your training data and model across all the nodes to process them in parallel and fully utilize the cluster’s compute and network infrastructure. You can further customize your training environment by installing additional frameworks, debugging tools, and optimization libraries.
Let me show you how to get started with SageMaker HyperPod. In the following demo, I create a SageMaker HyperPod and show you how to train a Llama 2 7B model using the example shared in the AWS ML Training Reference Architectures GitHub repository.
Create and manage clusters
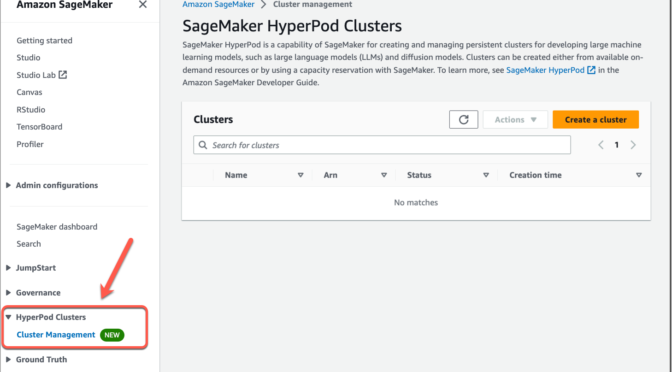
As the SageMaker HyperPod admin, you can create and manage clusters using the AWS Management Console or AWS Command Line Interface (AWS CLI). In the console, navigate to Amazon SageMaker, select Cluster management under HyperPod Clusters in the left menu, then choose Create a cluster.
In the setup that follows, provide a cluster name and configure instance groups with your instance types of choice and the number of instances to allocate to each instance group.
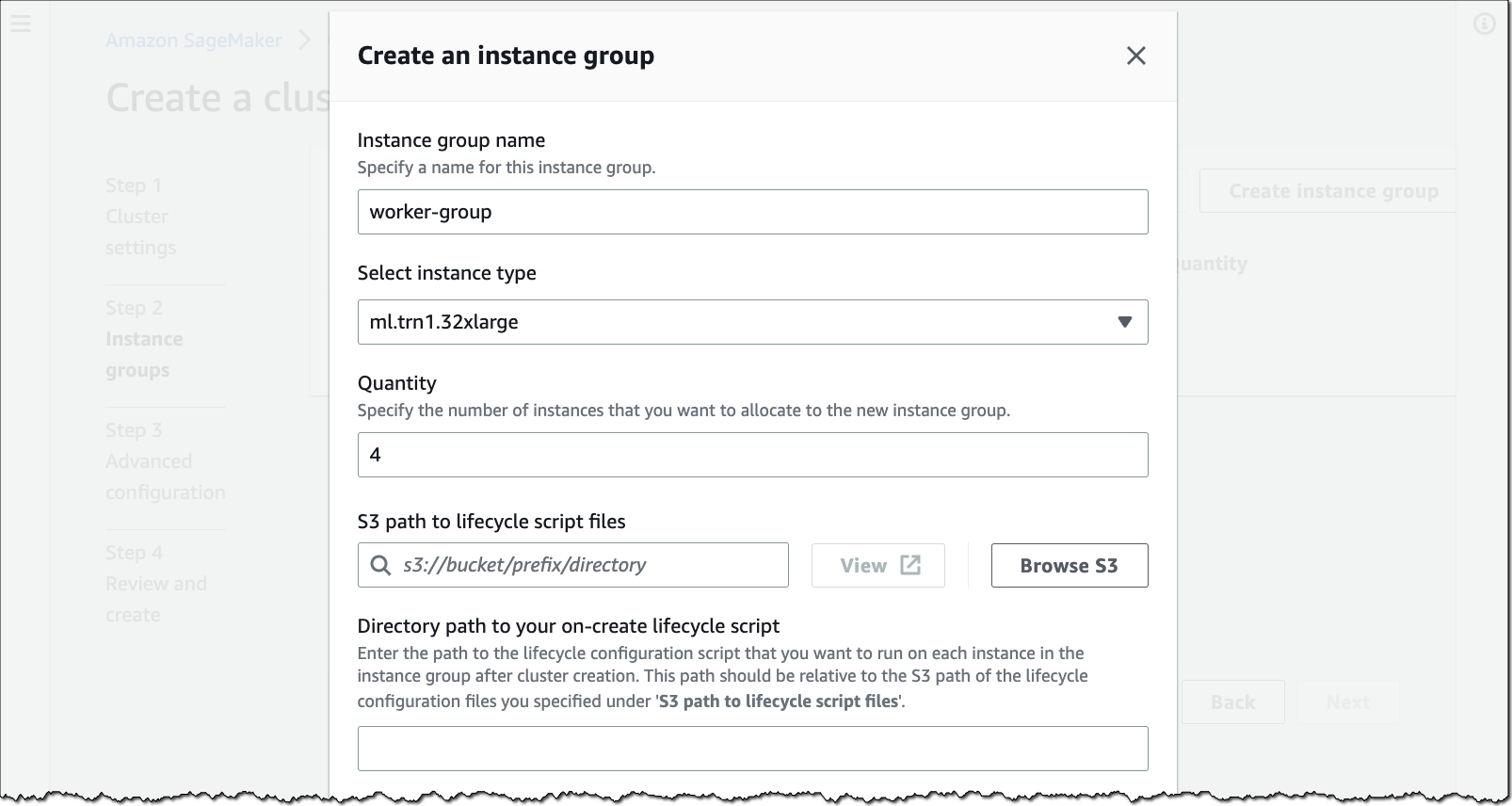
You also need to prepare and upload one or more lifecycle scripts to your Amazon Simple Storage Service (Amazon S3) bucket to run in each instance group during cluster creation. With lifecycle scripts, you can customize your cluster environment and install required libraries and packages. You can find example lifecycle scripts for SageMaker HyperPod in the GitHub repo.
Using the AWS CLI
You can also use the AWS CLI to create and manage clusters. For my demo, I specify my cluster configuration in a JSON file. I choose to create two instance groups, one for the cluster controller node(s) that I call “controller-group,” and one for the cluster worker nodes that I call “worker-group.” For the worker nodes that will perform model training, I specify Amazon EC2 Trn1 instances powered by AWS Trainium chips.
// demo-cluster.json
{
"InstanceGroups": [
{
"InstanceGroupName": "controller-group",
"InstanceType": "ml.m5.xlarge",
"InstanceCount": 1,
"lifecycleConfig": {
"SourceS3Uri": "s3://<your-s3-bucket>/<lifecycle-script-directory>/",
"OnCreate": "on_create.sh"
},
"ExecutionRole": "arn:aws:iam::111122223333:role/my-role-for-cluster",
"ThreadsPerCore": 1
},
{
"InstanceGroupName": "worker-group",
"InstanceType": "trn1.32xlarge",
"InstanceCount": 4,
"lifecycleConfig": {
"SourceS3Uri": "s3://<your-s3-bucket>/<lifecycle-script-directory>/",
"OnCreate": "on_create.sh"
},
"ExecutionRole": "arn:aws:iam::111122223333:role/my-role-for-cluster",
"ThreadsPerCore": 1
}
]
}To create the cluster, I run the following AWS CLI command:
aws sagemaker create-cluster
--cluster-name antje-demo-cluster
--instance-groups file://demo-cluster.jsonUpon creation, you can use aws sagemaker describe-cluster and aws sagemaker list-cluster-nodes to view your cluster and node details. Note down the cluster ID and instance ID of your controller node. You need that information to connect to your cluster.
You also have the option to attach a shared file system, such as Amazon FSx for Lustre. To use FSx for Lustre, you need to set up your cluster with an Amazon Virtual Private Cloud (Amazon VPC) configuration. Here’s an AWS CloudFormation template that shows how to create a SageMaker VPC and how to deploy FSx for Lustre.
Connect to your cluster
As a cluster user, you need to have access to the cluster provisioned by your cluster admin. With access permissions in place, you can connect to the cluster using SSH to schedule and run jobs. You can use the preinstalled AWS CLI plugin for AWS Systems Manager to connect to the controller node of your cluster.
For my demo, I run the following command specifying my cluster ID and instance ID of the control node as the target.
aws ssm start-session
--target sagemaker-cluster:ntg44z9os8pn_i-05a854e0d4358b59c
--region us-west-2Schedule and run jobs on the cluster using Slurm
At launch, SageMaker HyperPod supports Slurm for workload orchestration. Slurm is a popular an open source cluster management and job scheduling system. You can install and set up Slurm through lifecycle scripts as part of the cluster creation. The example lifecycle scripts show how. Then, you can use the standard Slurm commands to schedule and launch jobs. Check out the Slurm Quick Start User Guide for architecture details and helpful commands.
For this demo, I’m using this example from the AWS ML Training Reference Architectures GitHub repo that shows how to train Llama 2 7B on Slurm with Trn1 instances. My cluster is already setup with Slurm, and I have an FSx for Lustre filesystem mounted.
Note
The Llama 2 model is governed by Meta. You can request access through the Meta request access page.
Set up the cluster environment
SageMaker HyperPod supports training in a range of environments, including Conda, venv, Docker, and enroot. Following the instructions in the README, I build my virtual environment aws_neuron_venv_pytorch and set up the torch_neuronx and neuronx-nemo-megatron libraries for training models on Trn1 instances.
Prepare model, tokenizer, and dataset
I follow the instructions to download the Llama 2 model and tokenizer and convert the model into the Hugging Face format. Then, I download and tokenize the RedPajama dataset. As a final preparation step, I pre-compile the Llama 2 model using ahead-of-time (AOT) compilation to speed up model training.
Launch jobs on the cluster
Now, I’m ready to start my model training job using the sbatch command.
sbatch --nodes 4 --auto-resume=1 run.slurm ./llama_7b.shYou can use the squeue command to view the job queue. Once the training job is running, the SageMaker HyperPod resiliency features are automatically enabled. SageMaker HyperPod will automatically detect hardware failures, replace nodes as needed, and resume training from checkpoints if the auto-resume parameter is set, as shown in the preceding command.
You can view the output of the model training job in the following file:
tail -f slurm-run.slurm-<JOB_ID>.outA sample output indicating that model training has started will look like this:
Epoch 0: 22%|██▏ | 4499/20101 [22:26:14<77:48:37, 17.95s/it, loss=2.43, v_num=5563, reduced_train_loss=2.470, gradient_norm=0.121, parameter_norm=1864.0, global_step=4512.0, consumed_samples=1.16e+6, iteration_time=16.40]
Epoch 0: 22%|██▏ | 4500/20101 [22:26:32<77:48:18, 17.95s/it, loss=2.43, v_num=5563, reduced_train_loss=2.470, gradient_norm=0.121, parameter_norm=1864.0, global_step=4512.0, consumed_samples=1.16e+6, iteration_time=16.40]
Epoch 0: 22%|██▏ | 4500/20101 [22:26:32<77:48:18, 17.95s/it, loss=2.44, v_num=5563, reduced_train_loss=2.450, gradient_norm=0.120, parameter_norm=1864.0, global_step=4512.0, consumed_samples=1.16e+6, iteration_time=16.50]To further monitor and profile your model training jobs, you can use SageMaker hosted TensorBoard or any other tool of your choice.
Now available
SageMaker HyperPod is available today in AWS Regions US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore), Asia Pacific (Sydney), Asia Pacific (Tokyo), Europe (Frankfurt), Europe (Ireland), and Europe (Stockholm).
Learn more:
- See Amazon SageMaker HyperPod for pricing information and a list of supported cluster instance types
- Check out the Developer Guide
- Visit the AWS Management Console to start training your FMs with SageMaker HyperPod
— Antje
PS: Writing a blog post at AWS is always a team effort, even when you see only one name under the post title. In this case, I want to thank Brad Doran, Justin Pirtle, Ben Snyder, Pierre-Yves Aquilanti, Keita Watanabe, and Verdi March for their generous help with example code and sharing their expertise in managing large-scale model training infrastructures, Slurm, and SageMaker HyperPod.