Today we are announcing the general availability of the vector engine for Amazon OpenSearch Serverless with new features. In July 2023, we introduced the preview release of the vector engine for Amazon OpenSearch Serverless, a simple, scalable, and high-performing similarity search capability. The vector engine makes it easy for you to build modern machine learning (ML) augmented search experiences and generative artificial intelligence (generative AI) applications without needing to manage the underlying vector database infrastructure.
You can now store, update, and search billions of vector embeddings with thousands of dimensions in milliseconds. The highly performant similarity search capability of vector engine enables generative AI-powered applications to deliver accurate and reliable results with consistent milliseconds-scale response times.
The vector engine also enables you to optimize and tune results with hybrid search by combining vector search and full-text search in the same query, removing the need to manage and maintain separate data stores or a complex application stack. The vector engine provides a secure, reliable, scalable, and enterprise-ready platform to cost effectively build a prototyping application and then seamlessly scale to production.
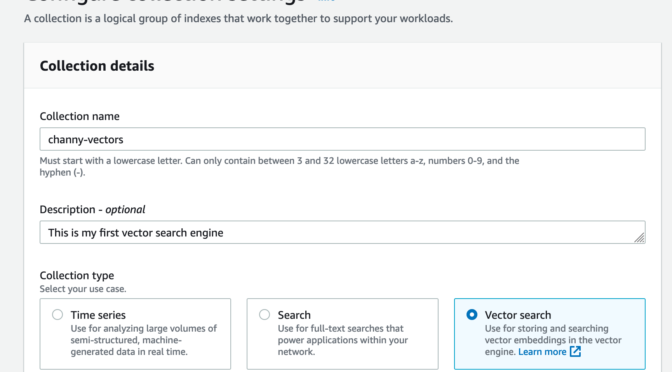
You can now get started in minutes with the vector engine by creating a specialized vector engine–based collection, which is a logical grouping of embeddings that works together to support a workload.
The vector engine uses OpenSearch Compute Units (OCUs), compute capacity unit, to ingest and run similarity search queries. One OCU can handle up to 2 million vectors for 128 dimensions or 500,000 for 768 dimensions at 99 percent recall rate.
The vector engine built on OpenSearch Serverless is a highly available service by default. It requires a minimum of four OCUs (2 OCUs for the ingest, including primary and standby, and 2 OCUs for the search with two active replicas across Availability Zones) for the first collection in an account. All subsequent collections using the same AWS Key Management Service (AWS KMS) key can share those OCUs.
What’s new at GA?
Since the preview, the vector engine for Amazon OpenSearch Serverless became one of the vector database options in the knowledge base of Amazon Bedrock to build generative AI applications using a Retrieval Augmented Generation (RAG) concept.
Here are some new or improved features for this GA release:
Disable redundant replica (development and test focused) option
As we announced in our preview blog post, this feature eliminates the need to have redundant OCUs in another Availability Zone solely for availability purposes. A collection can be deployed with two OCUs – one for indexing and one for search. This cuts the costs in half compared to default deployment with redundant replicas. The reduced cost makes this configuration suitable and economical for development and testing workloads.
With this option, we will still provide durability guarantees since the vector engine persists all the data in Amazon S3, but single-AZ failures would impact your availability.
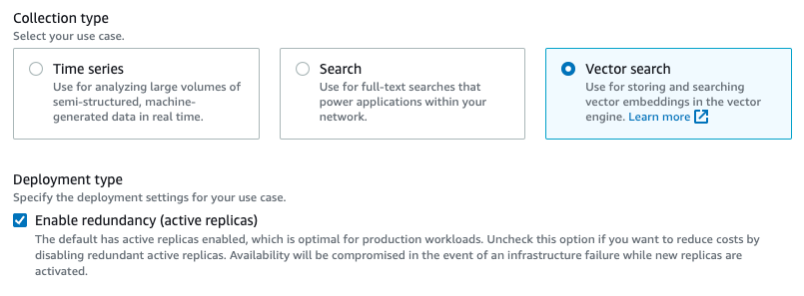
If you want to disable a redundant replica, uncheck Enable redundancy when creating a new vector search
collection.
Fractional OCU for the development and test focused option
Support for fractional OCU billing for development and test focused workloads (that is, no redundant replica option) reduces the floor price for vector search collection. The vector engine will initially deploy smaller 0.5 OCUs while providing the same capabilities at lower scale and will scale up to a full OCU and beyond to meet your workload demand. This option will further reduce the monthly costs when experimenting with using the vector engine.
Automatic scaling for a billion scale
With vector engine’s seamless auto-scaling, you no longer have to reindex for scaling purposes. At preview, we were supporting about 20 million vector embeddings. With the general availability of vector engine, we have raised the limits to support a billion vector scale.
Now available
The vector engine for Amazon OpenSearch Serverless is now available in all AWS Regions where Amazon OpenSearch Serverless is available.
To get started, you can refer to the following resources:
- Introducing the vector engine for Amazon OpenSearch Serverless, now in preview
- Try semantic search with the Amazon OpenSearch Service vector engine
- Amazon OpenSearch Service’s vector database capabilities explained
- Using OpenSearch as a vector database
- Getting started with Amazon OpenSearch Serverless documentation
- Demo video: Amazon OpenSearch Service for vector search
- Demo video: Empowering search: OpenSearch and bulk vector search
Give it a try and send feedback to AWS re:Post for Amazon OpenSearch Service or through your usual AWS support contacts.
— Channy