Today, we’re introducing two new Amazon Titan multimodal foundation models (FMs): Amazon Titan Image Generator (preview) and Amazon Titan Multimodal Embeddings. I’m also happy to share that Amazon Titan Text Lite and Amazon Titan Text Express are now generally available in Amazon Bedrock. You can now choose from three available Amazon Titan Text FMs, including Amazon Titan Text Embeddings.
Amazon Titan models incorporate 25 years of artificial intelligence (AI) and machine learning (ML) innovation at Amazon and offer a range of high-performing image, multimodal, and text model options through a fully managed API. AWS pre-trained these models on large datasets, making them powerful, general-purpose models built to support a variety of use cases while also supporting the responsible use of AI.
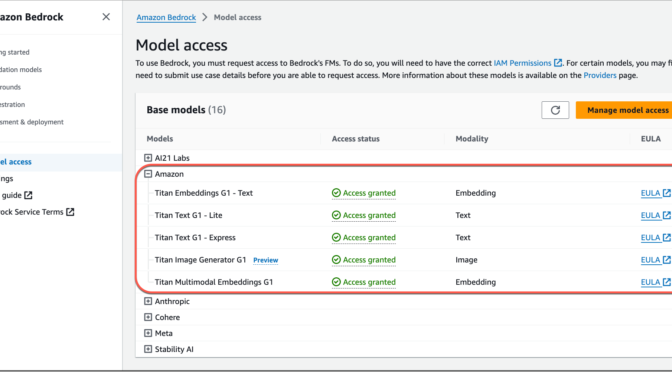
You can use the base models as is, or you can privately customize them with your own data. To enable access to Amazon Titan FMs, navigate to the Amazon Bedrock console and select Model access on the bottom left menu. On the model access overview page, choose Manage model access and enable access to the Amazon Titan FMs.
Let me give you a quick tour of the new models.
Amazon Titan Image Generator (preview)
As a content creator, you can now use Amazon Titan Image Generator to quickly create and refine images using English natural language prompts. This helps companies in advertising, e-commerce, and media and entertainment to create studio-quality, realistic images in large volumes and at low cost. The model makes it easy to iterate on image concepts by generating multiple image options based on the text descriptions. The model can understand complex prompts with multiple objects and generates relevant images. It is trained on high-quality, diverse data to create more accurate outputs, such as realistic images with inclusive attributes and limited distortions.
Titan Image Generator’s image editing features include the ability to automatically edit an image with a text prompt using a built-in segmentation model. The model supports inpainting with an image mask and outpainting to extend or change the background of an image. You can also configure image dimensions and specify the number of image variations you want the model to generate.
In addition, you can customize the model with proprietary data to generate images consistent with your brand guidelines or to generate images in a specific style, for example, by fine-tuning the model with images from a previous marketing campaign. Titan Image Generator also mitigates harmful content generation to support the responsible use of AI. All images generated by Amazon Titan contain an invisible watermark, by default, designed to help reduce the spread of misinformation by providing a discreet mechanism to identify AI-generated images.
Amazon Titan Image Generator in action
You can start using the model in the Amazon Bedrock console by submitting either an English natural language prompt to generate images or by uploading an image for editing. In the following example, I show you how to generate an image with Amazon Titan Image Generator using the AWS SDK for Python (Boto3).
First, let’s have a look at the configuration options for image generation that you can specify in the body of the inference request. For task type, I choose TEXT_IMAGE to create an image from a natural language prompt.
import boto3
import json
bedrock = boto3.client(service_name="bedrock")
bedrock_runtime = boto3.client(service_name="bedrock-runtime")
# ImageGenerationConfig Options:
# numberOfImages: Number of images to be generated
# quality: Quality of generated images, can be standard or premium
# height: Height of output image(s)
# width: Width of output image(s)
# cfgScale: Scale for classifier-free guidance
# seed: The seed to use for reproducibility
body = json.dumps(
{
"taskType": "TEXT_IMAGE",
"textToImageParams": {
"text": "green iguana", # Required
# "negativeText": "<text>" # Optional
},
"imageGenerationConfig": {
"numberOfImages": 1, # Range: 1 to 5
"quality": "premium", # Options: standard or premium
"height": 768, # Supported height list in the docs
"width": 1280, # Supported width list in the docs
"cfgScale": 7.5, # Range: 1.0 (exclusive) to 10.0
"seed": 42 # Range: 0 to 214783647
}
}
)Next, specify the model ID for Amazon Titan Image Generator and use the InvokeModel API to send the inference request.
response = bedrock_runtime.invoke_model(
body=body,
modelId="amazon.titan-image-generator-v1"
accept="application/json",
contentType="application/json"
)Then, parse the response and decode the base64-encoded image.
import base64
from PIL import Image
from io import BytesIO
response_body = json.loads(response.get("body").read())
images = [Image.open(BytesIO(base64.b64decode(base64_image))) for base64_image in response_body.get("images")]
for img in images:
display(img)Et voilà, here’s the green iguana (one of my favorite animals, actually):

To learn more about all the Amazon Titan Image Generator features, visit the Amazon Titan product page. (You’ll see more of the iguana over there.)
Next, let’s use this image with the new Amazon Titan Multimodal Embeddings model.
Amazon Titan Multimodal Embeddings
Amazon Titan Multimodal Embeddings helps you build more accurate and contextually relevant multimodal search and recommendation experiences for end users. Multimodal refers to a system’s ability to process and generate information using distinct types of data (modalities). With Titan Multimodal Embeddings, you can submit text, image, or a combination of the two as input.
The model converts images and short English text up to 128 tokens into embeddings, which capture semantic meaning and relationships between your data. You can also fine-tune the model on image-caption pairs. For example, you can combine text and images to describe company-specific manufacturing parts to understand and identify parts more effectively.
By default, Titan Multimodal Embeddings generates vectors of 1,024 dimensions, which you can use to build search experiences that offer a high degree of accuracy and speed. You can also configure smaller vector dimensions to optimize for speed and price performance. The model provides an asynchronous batch API, and the Amazon OpenSearch Service will soon offer a connector that adds Titan Multimodal Embeddings support for neural search.
Amazon Titan Multimodal Embeddings in action
For this demo, I create a combined image and text embedding. First, I base64-encode my image, and then I specify either inputText, inputImage, or both in the body of the inference request.
# Maximum image size supported is 2048 x 2048 pixels
with open("iguana.png", "rb") as image_file:
input_image = base64.b64encode(image_file.read()).decode('utf8')
# You can specify either text or image or both
body = json.dumps(
{
"inputText": "Green iguana on tree branch",
"inputImage": input_image
}
)Next, specify the model ID for Amazon Titan Multimodal Embeddings and use the InvokeModel API to send the inference request.
response = bedrock_runtime.invoke_model(
body=body,
modelId="amazon.titan-embed-image-v1",
accept="application/json",
contentType="application/json"
)Let’s see the response.
response_body = json.loads(response.get("body").read())
print(response_body.get("embedding"))
[-0.015633494, -0.011953583, -0.022617092, -0.012395329, 0.03954641, 0.010079376, 0.08505301, -0.022064181, -0.0037248489, ...]I redacted the output for brevity. The distance between multimodal embedding vectors, measured with metrics like cosine similarity or euclidean distance, shows how similar or different the represented information is across modalities. Smaller distances mean more similarity, while larger distances mean more dissimilarity.
As a next step, you could build an image database by storing and indexing the multimodal embeddings in a vector store or vector database. To implement text-to-image search, query the database with inputText. For image-to-image search, query the database with inputImage. For image+text-to-image search, query the database with both inputImage and inputText.
Amazon Titan Text
Amazon Titan Text Lite and Amazon Titan Text Express are large language models (LLMs) that support a wide range of text-related tasks, including summarization, translation, and conversational chatbot systems. They can also generate code and are optimized to support popular programming languages and text formats like JSON and CSV.
Titan Text Express – Titan Text Express has a maximum context length of 8,192 tokens and is ideal for a wide range of tasks, such as open-ended text generation and conversational chat, and support within Retrieval Augmented Generation (RAG) workflows.
Titan Text Lite – Titan Text Lite has a maximum context length of 4,096 tokens and is a price-performant version that is ideal for English-language tasks. The model is highly customizable and can be fine-tuned for tasks such as article summarization and copywriting.
Amazon Titan Text in action
For this demo, I ask Titan Text to write an email to my team members suggesting they organize a live stream: “Compose a short email from Antje, Principal Developer Advocate, encouraging colleagues in the developer relations team to organize a live stream to demo our new Amazon Titan V1 models.”
body = json.dumps({
"inputText": prompt,
"textGenerationConfig":{
"maxTokenCount":512,
"stopSequences":[],
"temperature":0,
"topP":0.9
}
})Titan Text FMs support temperature and topP inference parameters to control the randomness and diversity of the response, as well as maxTokenCount and stopSequences to control the length of the response.
Next, choose the model ID for one of the Titan Text models and use the InvokeModel API to send the inference request.
response = bedrock_runtime.invoke_model(
body=body,
# Choose modelID
# Titan Text Express: "amazon.titan-text-express-v1"
# Titan Text Lite: "amazon.titan-text-lite-v1"
modelID="amazon.titan-text-express-v1"
accept="application/json",
contentType="application/json"
)Let’s have a look at the response.
response_body = json.loads(response.get('body').read())
outputText = response_body.get('results')[0].get('outputText')
text = outputText[outputText.index('n')+1:]
email = text.strip()
print(email)Subject: Demo our new Amazon Titan V1 models live!
Dear colleagues,
I hope this email finds you well. I am excited to announce that we have recently launched our new Amazon Titan V1 models, and I believe it would be a great opportunity for us to showcase their capabilities to the wider developer community.
I suggest that we organize a live stream to demo these models and discuss their features, benefits, and how they can help developers build innovative applications. This live stream could be hosted on our YouTube channel, Twitch, or any other platform that is suitable for our audience.
I believe that showcasing our new models will not only increase our visibility but also help us build stronger relationships with developers. It will also provide an opportunity for us to receive feedback and improve our products based on the developer’s needs.
If you are interested in organizing this live stream, please let me know. I am happy to provide any support or guidance you may need. Together, let’s make this live stream a success and showcase the power of Amazon Titan V1 models to the world!
Best regards,
Antje
Principal Developer Advocate
Nice. I could send this email right away!
Availability and pricing
Amazon Titan Text FMs are available today in AWS Regions US East (N. Virginia), US West (Oregon), Asia Pacific (Singapore, Tokyo), and Europe (Frankfurt). Amazon Titan Multimodal Embeddings is available today in the AWS Regions US East (N. Virginia) and US West (Oregon). Amazon Titan Image Generator is available in public preview in the AWS Regions US East (N. Virginia) and US West (Oregon). For pricing details, see the Amazon Bedrock Pricing page.
Learn more
- Amazon Bedrock product page
- Amazon Titan product page
- Amazon Bedrock User Guide.
Go to the AWS Management Console to start building generative AI applications with Amazon Titan FMs on Amazon Bedrock today!
— Antje