
 Over the past week, we passed Laba festival, a traditional marker in the Chinese calendar that signals the final stretch leading up to the Lunar New Year. For many in China, it’s a moment associated with reflection and preparation, wrapping up what the year has carried, and turning attention toward what lies ahead.
Over the past week, we passed Laba festival, a traditional marker in the Chinese calendar that signals the final stretch leading up to the Lunar New Year. For many in China, it’s a moment associated with reflection and preparation, wrapping up what the year has carried, and turning attention toward what lies ahead.
Looking forward, next week also brings Lichun, the beginning of spring and the first of the 24 solar terms. In Chinese tradition, spring is often seen as the season when growth begins and new cycles take shape. There’s a common saying that “a year’s plans begin in spring,” capturing the idea that this is a time to set one’s direction and start fresh.
Last week’s launches
Here are the launches that got my attention this week:
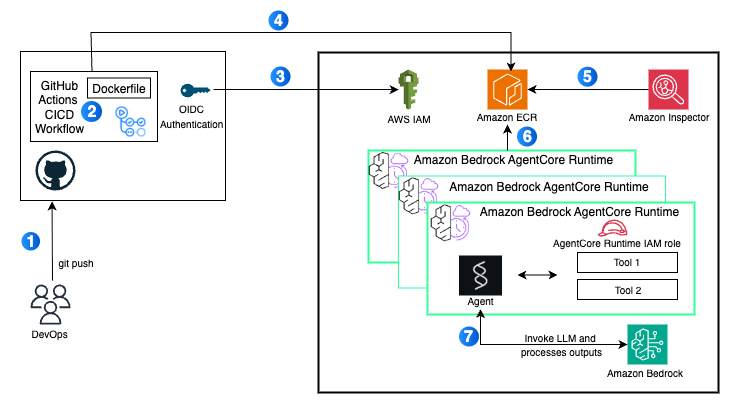
- Amazon Bedrock enhances support for agent workflows with server-side tools and extended prompt caching – Amazon Bedrock introduced two updates that improve how developers build and operate AI agents. The Responses API now supports server-side tool use, so agents can perform actions such as web search, code execution, and database updates within AWS security boundaries. Bedrock also adds a 1-hour time-to-live (TTL) option for prompt caching, which helps improve performance and reduce the cost for long-running, multi-turn agent workflows. Server-side tools are available with OpenAI GPT OSS 20B and 120B models, and the 1-hour prompt caching TTL is generally available for select Claude models by Anthropic in Amazon Bedrock.
- Amazon SageMaker Unified Studio adds private VPC connectivity with AWS PrivateLink – Amazon SageMaker Unified Studio now supports AWS PrivateLink, providing private connectivity between your VPC and SageMaker Unified Studio without routing customer data over the public internet. With SageMaker service endpoints onboarded into a VPC, data traffic remains within the AWS network and is governed by IAM policies, supporting stricter security and compliance requirements.
- Amazon S3 adds support for changing object encryption without data movement – Amazon S3 now supports changing the server-side encryption type of existing encrypted objects without moving or re-uploading data. Using the
UpdateObjectEncryptionAPI, you can switch from SSE-S3 to SSE-KMS, rotate customer -managed AWS Key Management Service (AWS KMS) keys, or standardize encryption across buckets at scale with S3 Batch Operations while preserving object properties and lifecycle eligibility. - Amazon Keyspaces introduces table pre-warming for predictable high-throughput workloads – Amazon Keyspaces (for Apache Cassandra) now supports table pre-warming, which helps you proactively set warm throughput levels so tables can handle high read and write traffic instantly without cold-start delays. Pre-warming helps reduce throttling during sudden traffic spikes, such as product launches or sales events, and works with both on-demand and provisioned capacity modes, including multi-Region tables. The feature supports consistent, low-latency performance while giving you more control over throughput readiness.
- Amazon DynamoDB MRSC global tables integrate with AWS Fault Injection Service – Amazon DynamoDB multi-Region strong consistency (MRSC) global tables now integrate with AWS Fault Injection Service. With this integration, you can simulate Regional failures, test replication behavior, and validate application resiliency for strongly consistent, multi-Region workloads.
Additional updates
Here are some additional projects, blog posts, and news items that I found interesting:
- Building zero-trust access across multi-account AWS environments with AWS Verified Access – This post walks through how to implement AWS Verified Access in a centralized, shared-services architecture. It shows how to integrate with AWS IAM Identity Center and AWS Resource Access Manager (AWS RAM) to apply zero trust access controls at the application layer and reduce operational overhead across multi-account AWS environments.
- Amazon EventBridge increases event payload size to 1 MB – Amazon EventBridge now supports event payloads up to 1 MB, an increase from the previous 256 KB limit. This update helps event-driven architectures carry richer context in a single event, including complex JSON structures, telemetry data, and machine learning (ML) or generative AI outputs, without splitting payloads or relying on external storage.
- AWS MCP Server adds deployment agent SOPs (preview) – AWS introduced deployment standard operating procedures (SOPs) that AI agents can deploy web applications to AWS from a single natural language prompt in MCP -compatible integrated development environments (IDEs) and command line interfaces (CLIs) such as Kiro, Cursor, and Claude Code. The agent generates AWS Cloud Development Kit (AWS CDK) infrastructure, deploys AWS CloudFormation stacks, and sets up continuous integration and continuous delivery (CI/CD) workflows following AWS best practices. The preview supports frameworks including React, Vue.js, Angular, and Next.js.
- AWS Network Firewall adds generation AI traffic visibility with web category filtering – AWS Network Firewall now provides visibility into generative AI application traffic through predefined web categories. You can use these categories directly in firewall rules to govern access to generative AI tools and other web services. When combined with TLS inspection, category-based filtering can be applied at the full URL level.
- AWS Lambda adds enhanced observability for Kafka event source mappings – AWS Lambda introduced enhanced observability for Kafka event source mappings, providing Amazon CloudWatch Logs and metrics to monitor event polling configuration, scaling behavior, and event processing state. The update improves visibility into Kafka-based Lambda workloads, helping teams diagnose configuration issues, permission errors, and function failures more efficiently. The capability supports both Amazon Managed Streaming for Apache Kafka (Amazon MSK) and self-managed Apache Kafka event sources.
- AWS CloudFormation 2025 year in review – This year-in-review post highlights CloudFormation updates delivered throughout 2025, with a focus on early validation, safer deployments, and improved developer workflows. It covers enhancements such as improved troubleshooting, drift-aware change sets, stack refactoring, StackSets updates, and new -IDE and AI -assisted tooling, including the CloudFormation language server and the Infrastructure as Code (IaC) MCP server.
Upcoming AWS events
Check your calendars so that you can sign up for this upcoming event:
AWS Community Day Romania (April 23–24, 2026) – This community-led AWS event brings together developers, architects, entrepreneurs, and students for more than 10 professional sessions delivered by AWS Heroes, Solutions Architects, and industry experts. Attendees can expect expert-led technical talks, insights from speakers with global conference experience, and opportunities to connect during dedicated networking breaks, all hosted at a premium venue designed to support collaboration and community engagement.
If you’re looking for more ways to stay connected beyond this event, join the AWS Builder Center to learn, build, and connect with builders in the AWS community.
Check back next Monday for another Weekly Roundup.









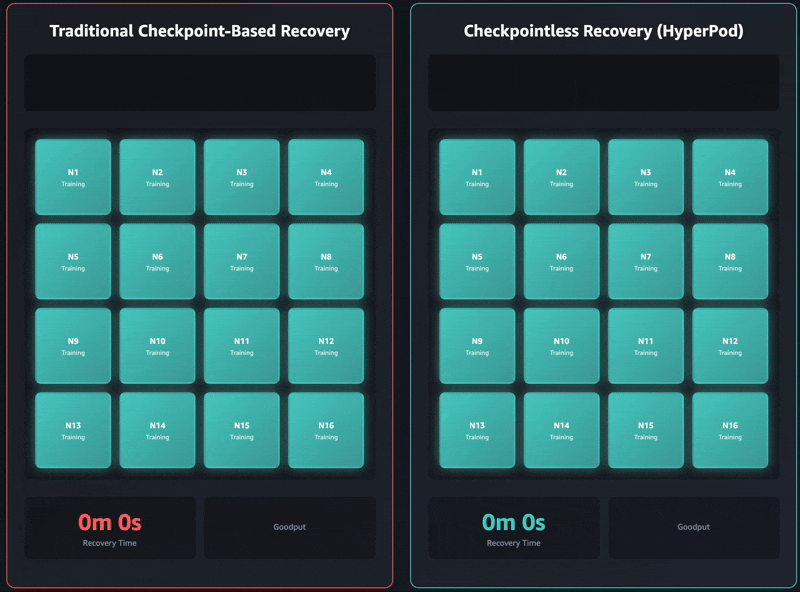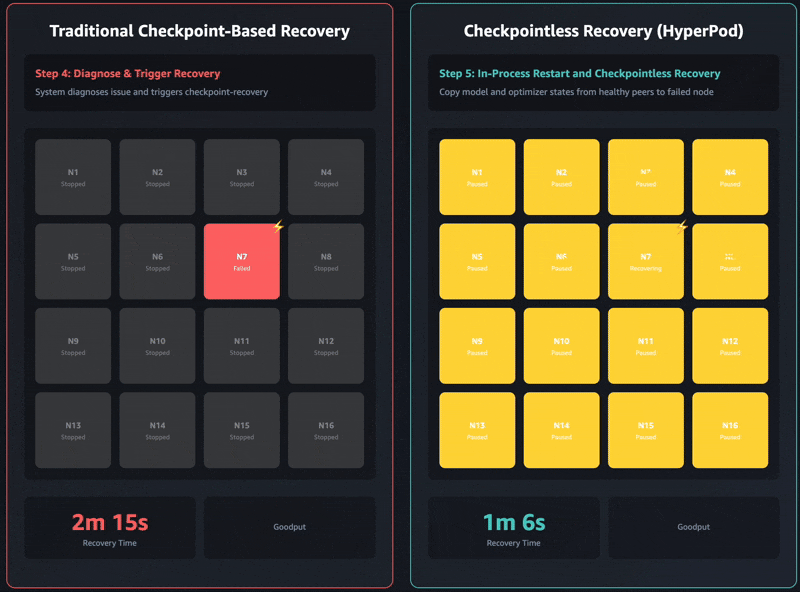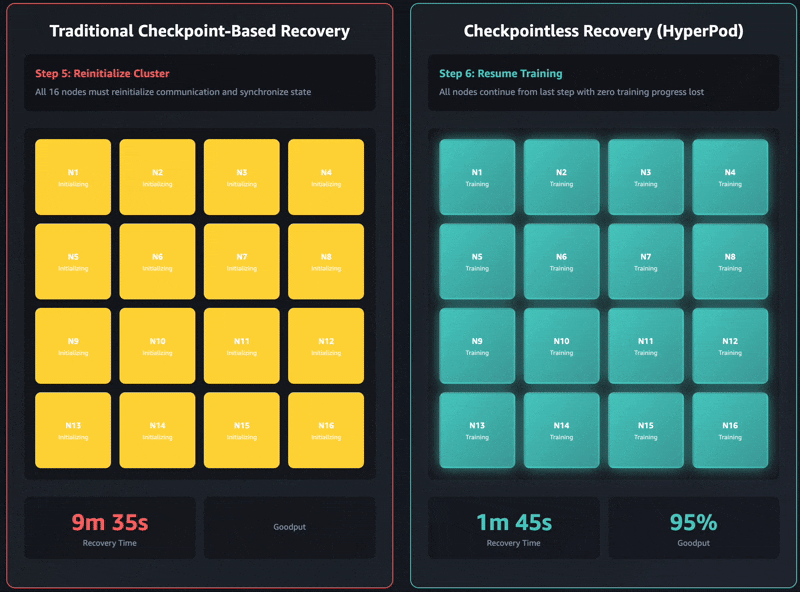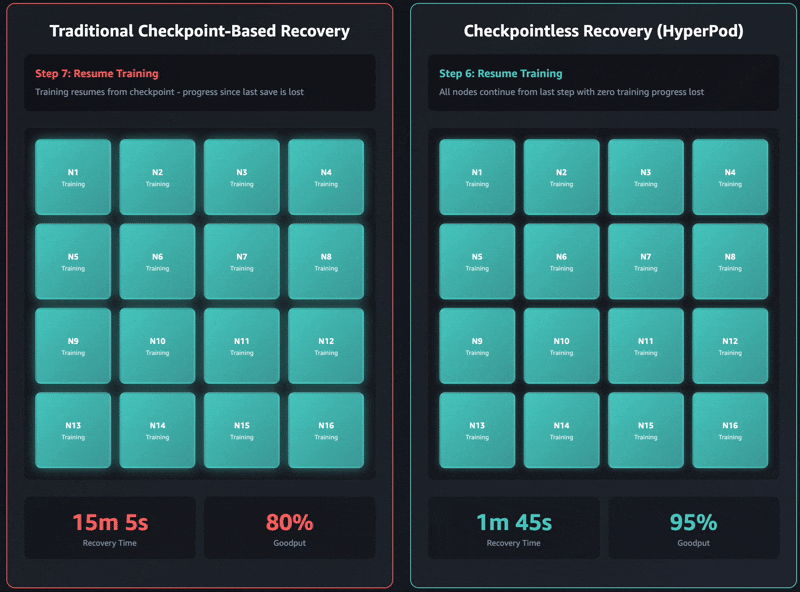
 Elastic training transforms how training workloads interact with cluster resources. Training jobs can automatically scale up to utilize available accelerators and gracefully contract when resources are needed elsewhere, all while maintaining training quality.
Elastic training transforms how training workloads interact with cluster resources. Training jobs can automatically scale up to utilize available accelerators and gracefully contract when resources are needed elsewhere, all while maintaining training quality.