Today, we’re announcing a new feature of Amazon Simple Storage Service (Amazon S3) you can use to create general purpose buckets in your own account regional namespace simplifying bucket creation and management as your data storage needs grow in size and scope. You can create general purpose bucket names across multiple AWS Regions with assurance that your desired bucket names will always be available for you to use.
With this feature, you can predictably name and create general purpose buckets in your own account regional namespace by appending your account’s unique suffix in your requested bucket name. For example, I can create the bucket mybucket-123456789012-us-east-1-an in my account regional namespace. mybucket is the bucket name prefix that I specified, then I add my account regional suffix to the requested bucket name: -123456789012-us-east-1-an. If another account tries to create buckets using my account’s suffix, their requests will be automatically rejected.
Your security teams can use AWS Identity and Access Management (AWS IAM) policies and AWS Organizations service control policies to enforce that your employees only create buckets in their account regional namespace using the new s3:x-amz-bucket-namespace condition key, helping teams adopt the account regional namespace across your organization.
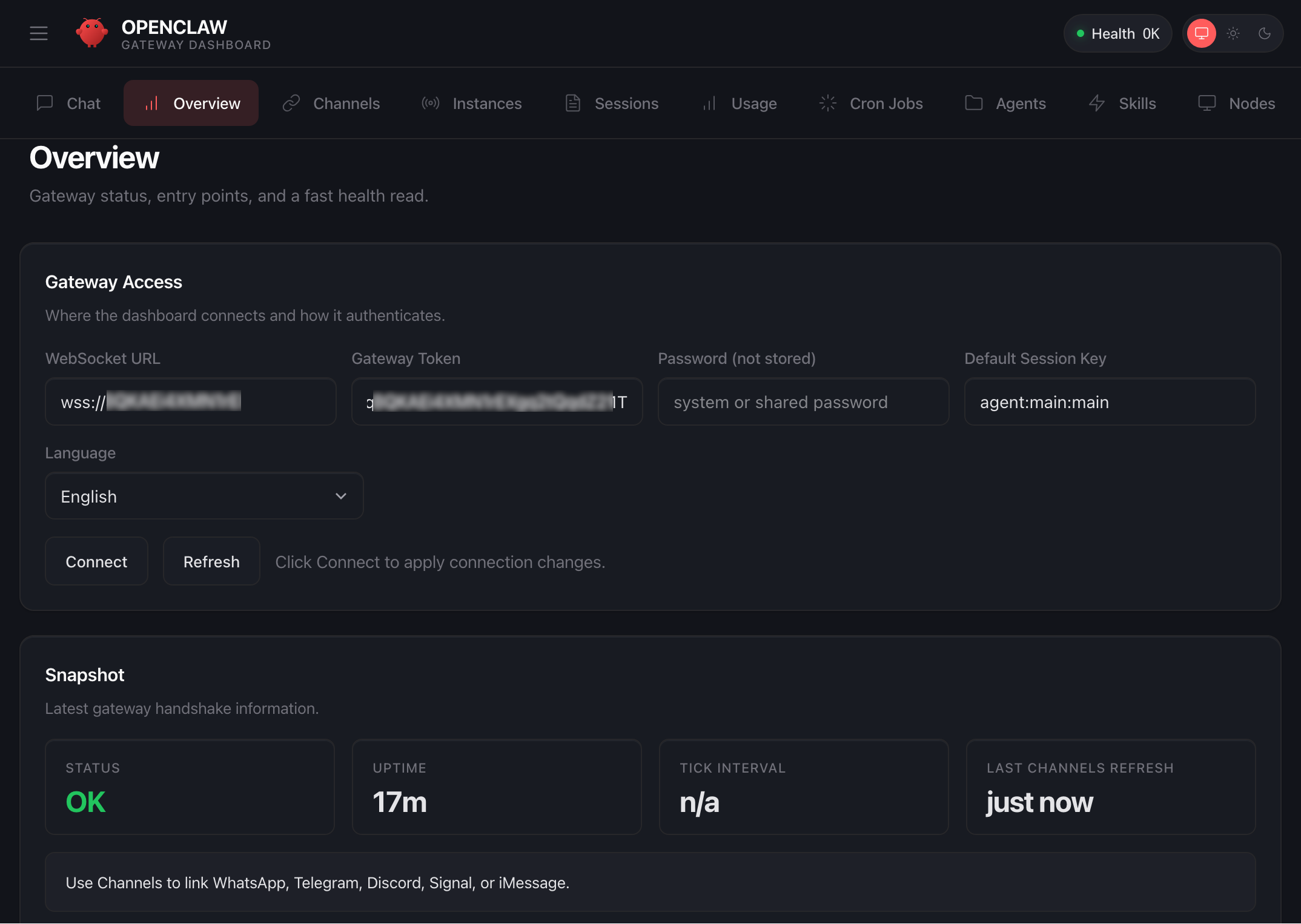
Create your S3 bucket with account regional namespace in action
To get started, choose Create bucket in the Amazon S3 console. To create your bucket in your account regional namespace, choose Account regional namespace. If you choose this option, you can create your bucket with any name that is unique to your account and region.
This configuration supports all of the same features as general purpose buckets in the global namespace. The only difference is that only your account can use bucket names with your account’s suffix. The bucket name prefix and the account regional suffix combined must be between 3 and 63 characters long.

Using the AWS Command Line Interface (AWS CLI), you can create a bucket with account regional namespace by specifying the x-amz-bucket-namespace:account-regional request header and providing a compatible bucket name.
$ aws s3api create-bucket --bucket mybucket-123456789012-us-east-1-an
--bucket-namespace account-regional
--region us-east-1You can use the AWS SDK for Python (Boto3) to create a bucket with account regional namespace using CreateBucket API request.
import boto3
class AccountRegionalBucketCreator:
"""Creates S3 buckets using account-regional namespace feature."""
ACCOUNT_REGIONAL_SUFFIX = "-an"
def __init__(self, s3_client, sts_client):
self.s3_client = s3_client
self.sts_client = sts_client
def create_account_regional_bucket(self, prefix):
"""
Creates an account-regional S3 bucket with the specified prefix.
Resolves caller AWS account ID using the STS GetCallerIdentity API.
Format: ---an
"""
account_id = self.sts_client.get_caller_identity()['Account']
region = self.s3_client.meta.region_name
bucket_name = self._generate_account_regional_bucket_name(
prefix, account_id, region
)
params = {
"Bucket": bucket_name,
"BucketNamespace": "account-regional"
}
if region != "us-east-1":
params["CreateBucketConfiguration"] = {
"LocationConstraint": region
}
return self.s3_client.create_bucket(**params)
def _generate_account_regional_bucket_name(self, prefix, account_id, region):
return f"{prefix}-{account_id}-{region}{self.ACCOUNT_REGIONAL_SUFFIX}"
if __name__ == '__main__':
s3_client = boto3.client('s3')
sts_client = boto3.client('sts')
creator = AccountRegionalBucketCreator(s3_client, sts_client)
response = creator.create_account_regional_bucket('test-python-sdk')
print(f"Bucket created: {response}")You can update your infrastructure as code (IaC) tools, such as AWS CloudFormation, to simplify creating buckets in your account regional namespace. AWS CloudFormation offers the pseudo parameters, AWS::AccountId and AWS::Region, making it easy to build CloudFormation templates that create account regional namespace buckets.
The following example demonstrates how you can update your existing CloudFormation templates to start creating buckets in your account regional namespace:
BucketName: !Sub "amzn-s3-demo-bucket-${AWS::AccountId}-${AWS::Region}-an"
BucketNamespace: "account-regional"Alternatively, you can also use the BucketNamePrefix property to update your CloudFormation template. By using the BucketNamePrefix, you can provide only the customer defined portion of the bucket name and then it automatically adds the account regional namespace suffix based on the requesting AWS account and Region specified.
BucketNamePrefix: 'amzn-s3-demo-bucket'
BucketNamespace: "account-regional"
Using these options, you can build a custom CloudFormation template to easily create general purpose buckets in your account regional namespace.
Things to know
You can’t rename your existing global buckets to bucket names with account regional namespace, but you can create new general purpose buckets in your account regional namespace. Also, the account regional namespace is only supported for general purpose buckets. S3 table buckets and vector buckets already exist in an account-level namespace and S3 directory buckets exist in a zonal namespace.
To learn more, visit Namespaces for general purpose buckets in the Amazon S3 User Guide.
Now available
Creating general purpose buckets in your account regional namespace in Amazon S3 is now available in 37 AWS Regions including the AWS China and AWS GovCloud (US) Regions. You can create general purpose buckets in your account regional namespace at no additional cost.
Give it a try in the Amazon S3 console today and send feedback to AWS re:Post for Amazon S3 or through your usual AWS Support contacts.
— Channy