Today, we’re announcing the general availability of cross-account safeguards in Amazon Bedrock Guardrails, a new capability that enables centralized enforcement and management of safety controls across multiple AWS accounts within an organization.
With this new capability, you can specify a guardrail in a new Amazon Bedrock policy within the management account of your organization that automatically enforces configured safeguards across all member entities for every model invocation with Amazon Bedrock. This organization-wide implementation supports uniform protection across all accounts and generative AI applications with centralized control and management. This capability also offers flexibility to apply account-level and application-specific controls depending on use case requirements in addition to organizational safeguards.
- Organization-level enforcements apply a single guardrail from your organization’s management account to all entities within the organization through policy settings. This guardrail automatically enforces filters across all member entities, including organizational units (OUs) and individual accounts, for all Amazon Bedrock model invocations.
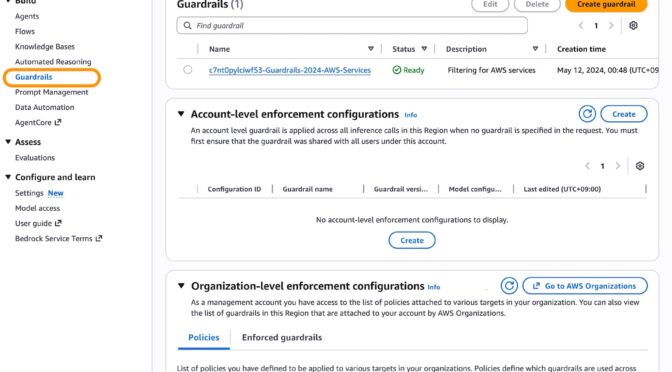
- Account-level enforcement enables automatic enforcement of configured safeguards across all Amazon Bedrock model invocations in your AWS account. The configured safeguards in the account-level guardrail apply to all inference API calls.
You can now establish and centrally manage dependable, comprehensive protection through a single, unified approach. This supports consistent adherence to corporate responsible AI requirements while significantly reducing the administrative burden of monitoring individual accounts and applications. Your security team no longer needs to oversee and verify configurations or compliance for each account independently.
Getting started with centralized enforcement in Amazon Bedrock Guardrails
You can get started with account-level and organization-level enforcement configuration in the Amazon Bedrock Guardrails console. Before the enforcement configuration, you need to create a guardrail with a particular version to support the guardrail configuration remains immutable and cannot be modified by member accounts and complete prerequisites for using the new capability such as resource-based policies for guardrails.
To enable account-level enforcement, choose Create in the section of Account-level enforcement configurations.
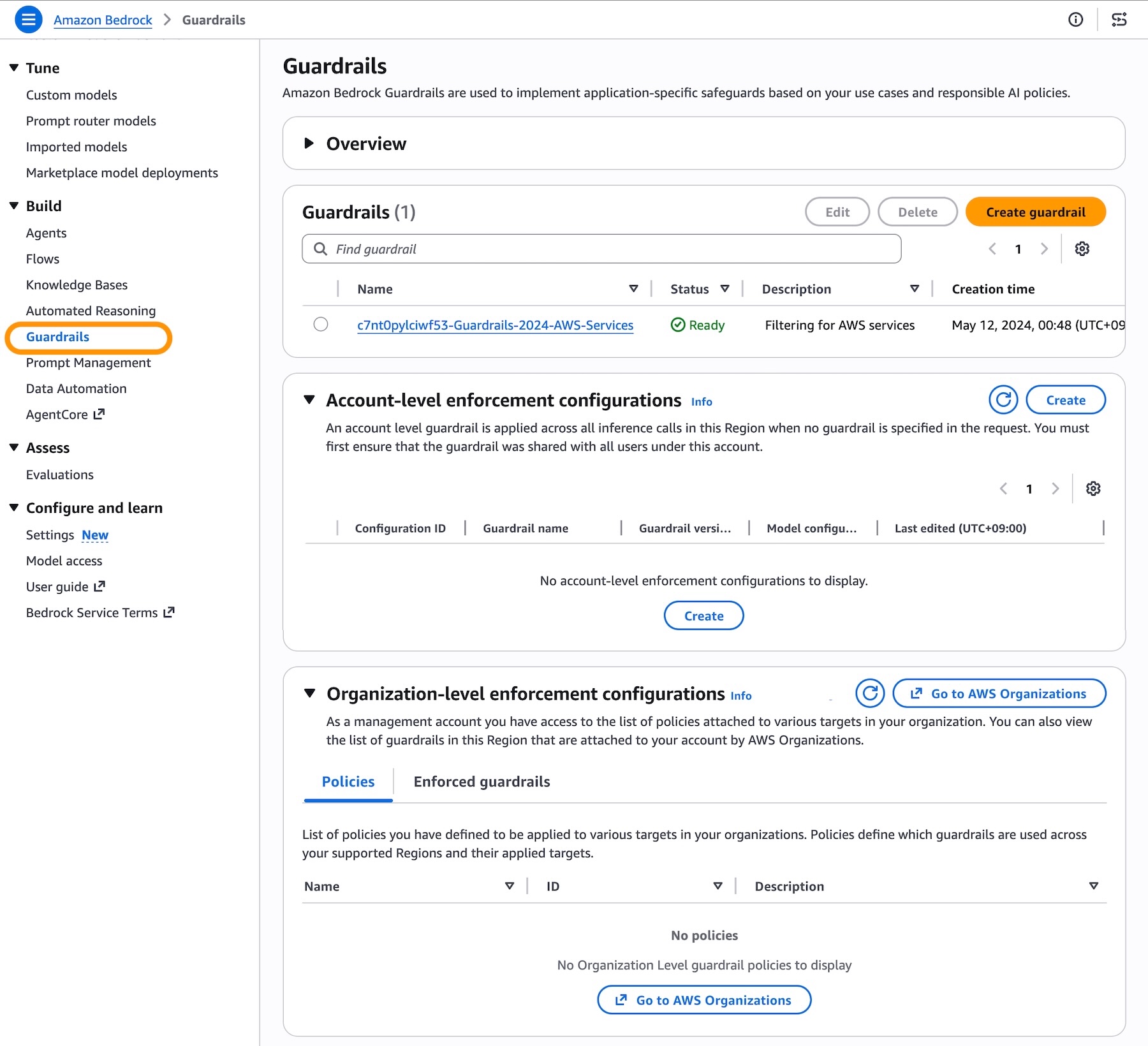
You can choose the guardrail and version to automatically apply to all Bedrock inference calls from this account in this Region. With general availability, we introduce the new feature defining which models will be affected by the enforcement with either Include or Exclude behavior.
You can also configure selective content guarding controls for system prompts and user prompts with either Comprehensive or Selective.
- Use Comprehensive when you want to enforce guardrails on everything, regardless of what the caller tags. This is the safer default when you don’t want to rely on callers to correctly identify sensitive content.
- Use Selective when you trust callers to tag the right content and want to reduce unnecessary guardrail processing. This is useful when callers handle a mix of pre-validated and user-generated content, and only need guardrails applied to specific portions.
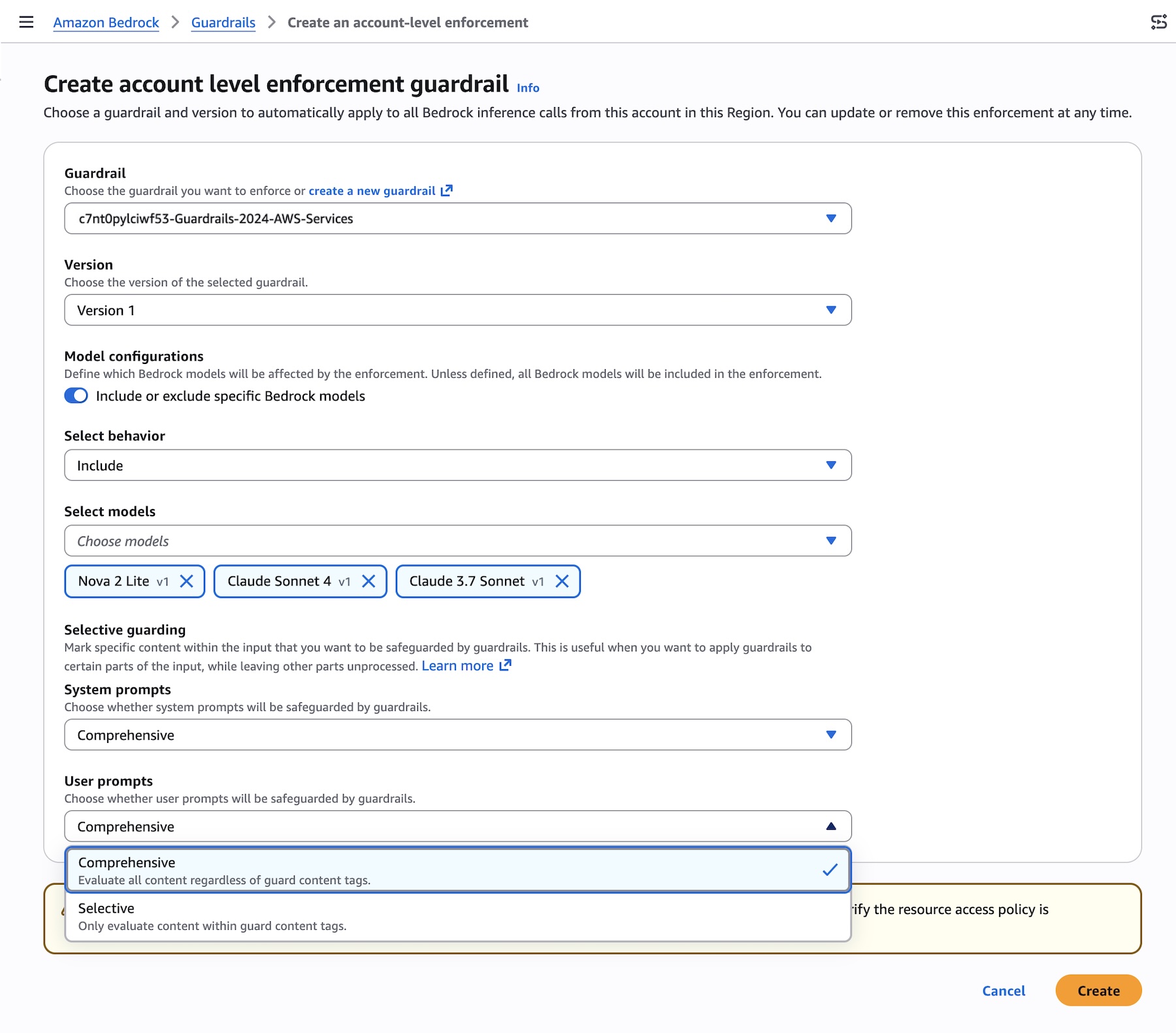
After creating the enforcement, you can test and verify enforcement using a role in your account. The account-enforced guardrail should automatically apply to both prompts and outputs.
Check the response for guardrail assessment information. The guardrail response will include enforced guardrail information. You can also test by making a Bedrock inference call using InvokeModel, InvokeModelWithResponseStream, Converse, or ConverseStream APIs.
To enable organization-level enforcement, go to AWS Organizations console and choose Policies menu. You can enable the Bedrock policies in the console.
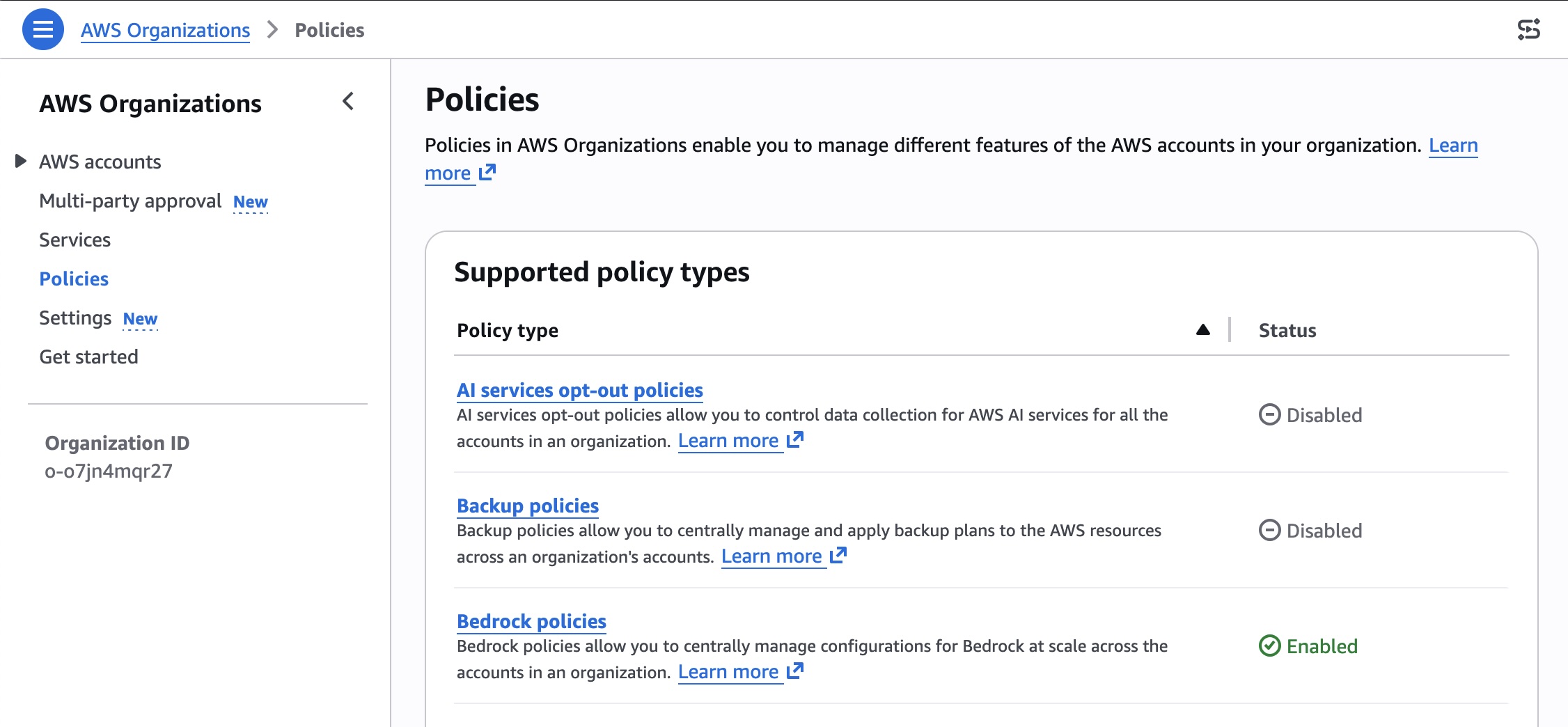
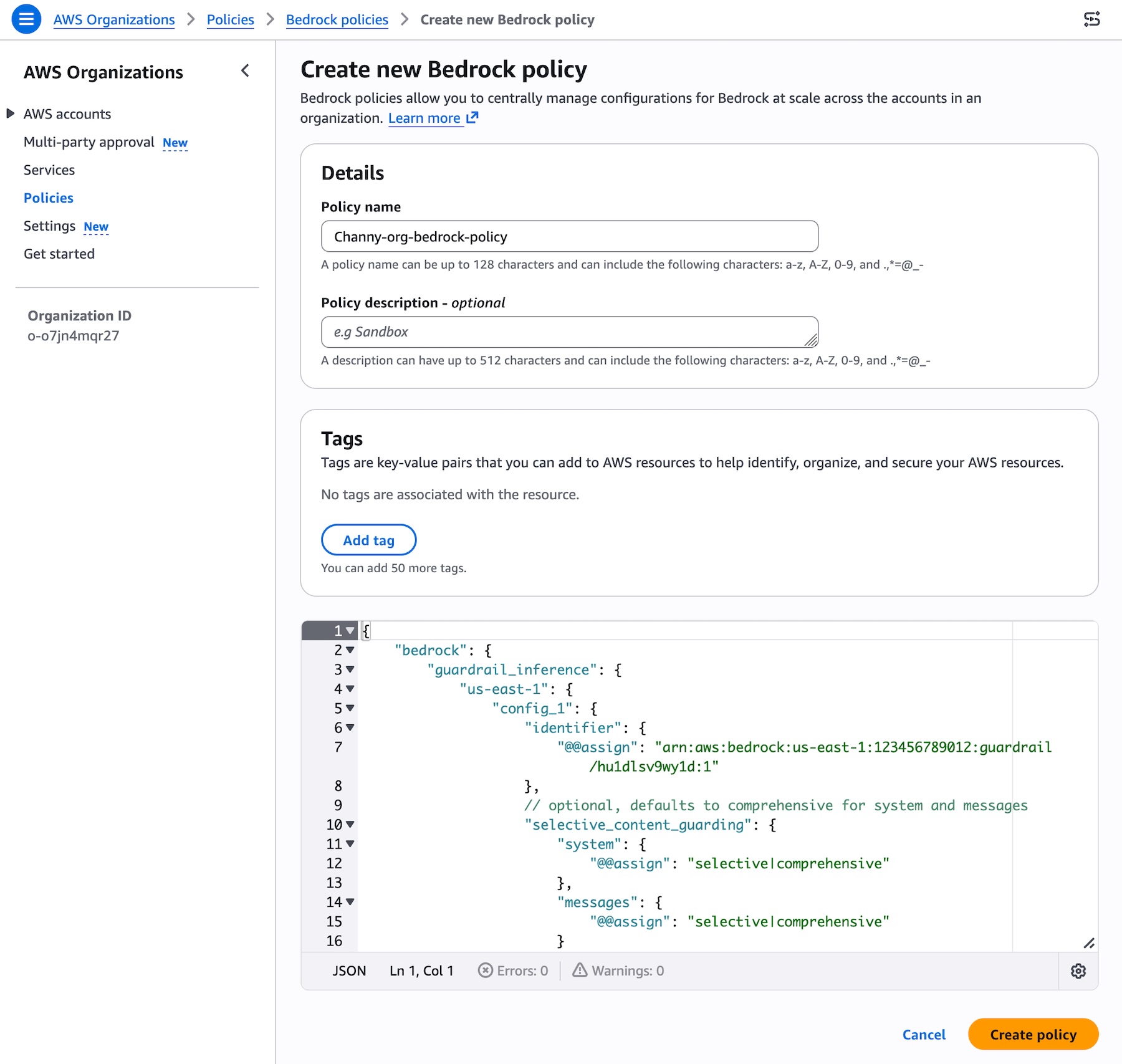
You can create a Bedrock policy that specifies your guardrail and attach it to your target accounts or OUs. Choose Bedrock policies enabled and Create policy. Specify your guardrail ARN and version and configure the input tags setting for in the AWS Organizations. To learn more, visit Amazon Bedrock policies in AWS Organizations and Amazon Bedrock policy syntax and examples.
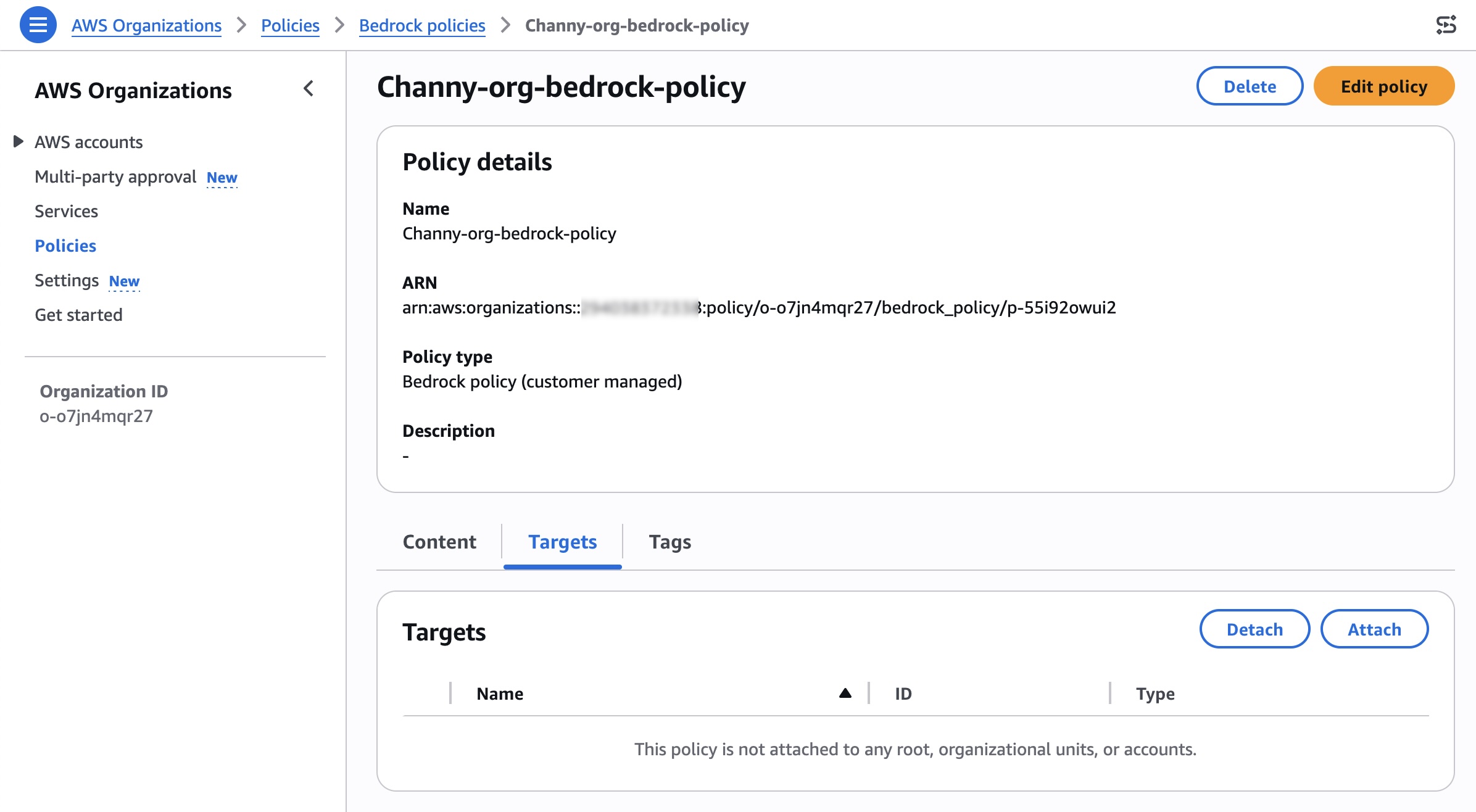
After creating the policy, you can attach the policy to your desired organizational units, accounts, root in the Targets tab.
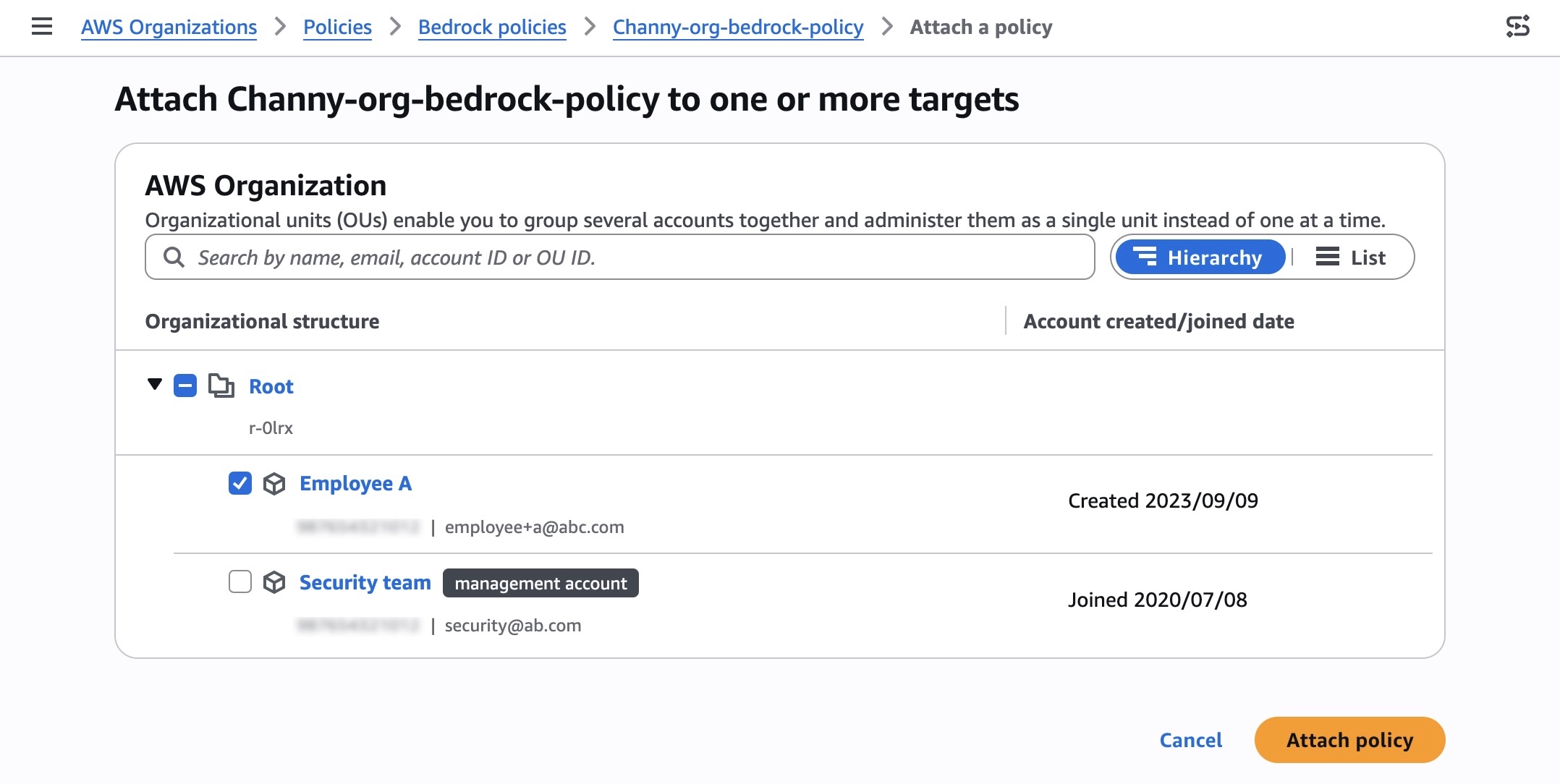
Search and select your organization root, OUs, or individual accounts to attach your policy, and choose Attach policy.
You can test that the guardrail is being enforced on member accounts and verify which guardrail is enforced. From a member account attached, you should see the organization enforced guardrail under the section Organization-level enforcement configurations.
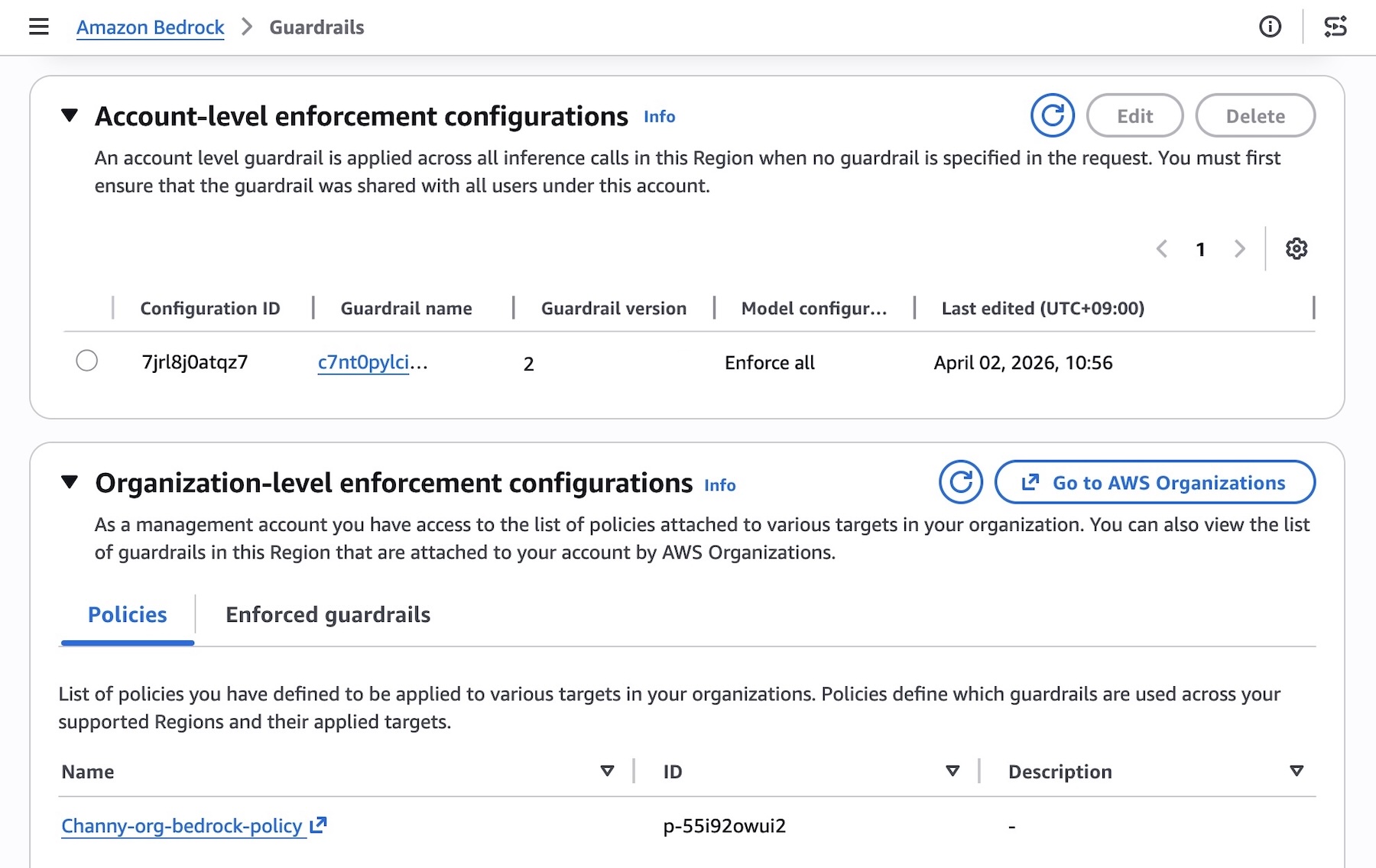
The underlying safeguards within the specified guardrail are then automatically enforced for every model inference request across all member entities, ensuring consistent safety controls. To accommodate varying requirements of individual teams or applications, you can attach different policies with associated guardrails to different member entities through your organization.
Things to know
Here are key considerations to know about GA features:
- You can now choose to include or exclude specific models in Bedrock for inference, enabling centralized enforcement on model invocation calls. You can also choose to safeguard partial or complete system prompts and input prompts. To learn more, visit Apply cross-account safeguards with Amazon Bedrock Guardrails enforcement.
- Ensure you are specifying the accurate guardrail Amazon Resource Names (ARN) in the policy. Specifying an incorrect or invalid ARN will result in policy violations, non-enforcement of safeguards, and the inability to use the models in Amazon Bedrock for inference. To learn more, visit Best practices for using Amazon Bedrock policies.
- Automated Reasoning checks are not supported with this capability.
Now available
Cross-account safeguards in Amazon Bedrock Guardrails is generally available today in the all AWS commercial and GovCloud Regions where Bedrock Guardrails is available. For Regional availability and a future roadmap, visit the AWS Capabilities by Region. Charges apply to each enforced guardrail according to its configured safeguards. For detailed pricing information on individual safeguards, visit Amazon Bedrock Pricing page.
Give this capability a try in the Amazon Bedrock console and send feedback to AWS re:Post for Amazon Bedrock Guardrails or through your usual AWS Support contacts.
— Channy


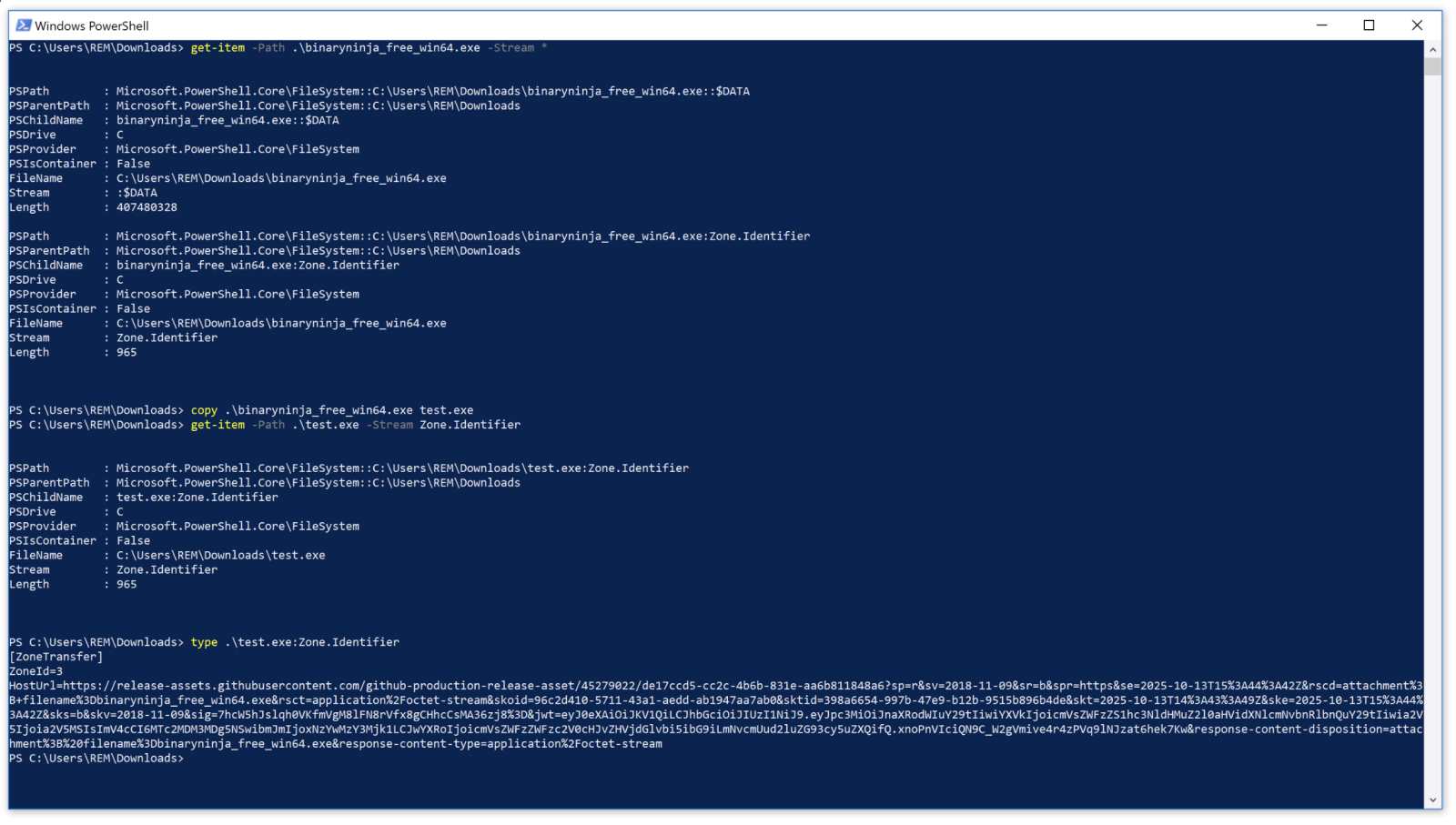 By removing the ADS, the malicious script makes the file look less suspicious if the system is scanned to search for "downloaded" files (a classic operation performed in DFIR investigations).
By removing the ADS, the malicious script makes the file look less suspicious if the system is scanned to search for "downloaded" files (a classic operation performed in DFIR investigations).