Numbers are often used in passwords to add complexity. Passwords submitted to honeypots are also often found within pre-existing passwords lists, containing compromised credentials. What numbers are most commonly used?
First, unique passwords were extracted using 'jq'.
# read cowrie JSON files
# cat /logs/cowrie.json*
# select any values with the password key present
# jq 'select(.password)'
# get password values without quotes (raw)
# jq -r .password
# get unique values and save them to a text file
# sort | uniq > 2024-01-07_unique_passwords.txt
cat /logs/cowrie.json* | jq 'select(.password)' | jq -r .password | sort | uniq > 2024-01-07_unique_passwords.txt
Date range of data: 04/13/2022 – 01/05/2024
Number of unique passwords: 275,811
Python was usued to extract the numbers and chart the most common results.
import re
from collections import Counter
import matplotlib.pyplot as plt
filehandle = open("2024-01-07_unique_passwords.txt", "r", encoding="utf8")
passwords = []
for line in filehandle.readlines():
passwords.append(line.replace("n", ""))
individual_digits = []
contiguous_numbers = []
for each_password in passwords:
individual_digits += re.findall(r'd', each_password)
contiguous_numbers += re.findall(r'd+', each_password)
individual_digit_counts = Counter(individual_digits)
contiguous_number_counts = Counter(contiguous_numbers)
x = []
y = []
for number, frequency in contiguous_number_counts.most_common(10):
x.append(number)
y.append(frequency)
plt.bar(x, y)
plt.title(f"Top {len(x)} Numbers Used in Unique Passwords Submitted to Honeypot")
plt.xlabel("Number")
plt.ylabel("Frequency")
plt.show()
x = []
y = []
for number, frequency in individual_digit_counts.items():
x.append(number)
y.append(frequency)
plt.bar(x, y)
plt.title(f"Numbers Used in Unique Passwords Submitted to Honeypot")
plt.xlabel("Number")
plt.ylabel("Frequency")
plt.show()
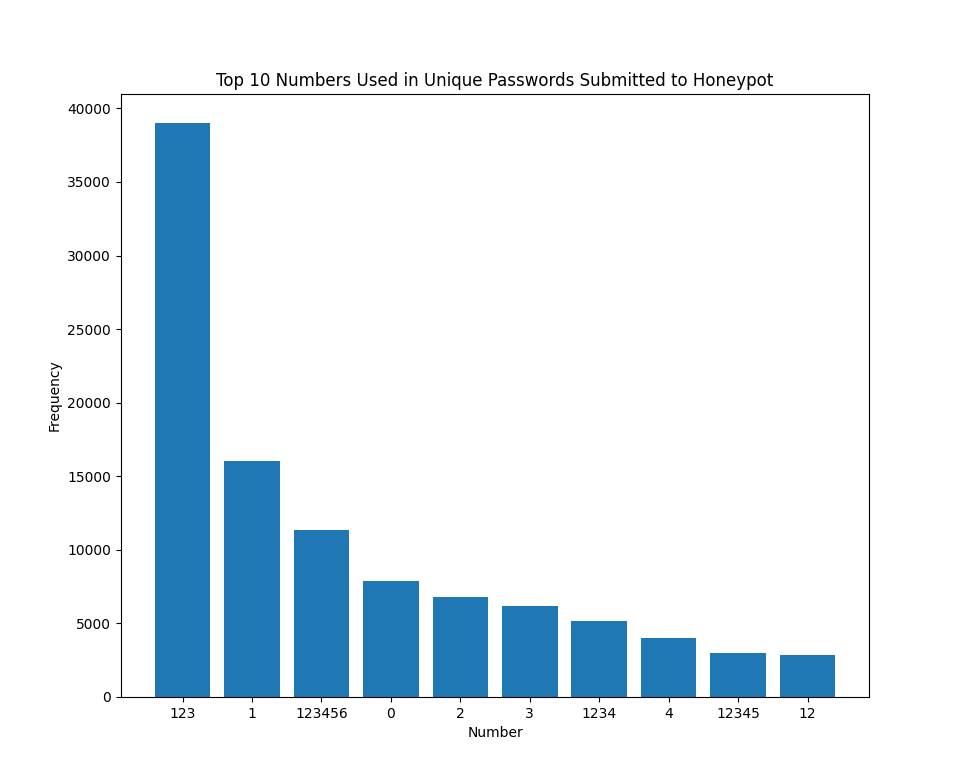
Figure 1: Top 10 contiguous numbers used in passwords submitted to a honeypot
The most commonly used number within passwords submitted to one of my honeypots was "123". Of the contiguous numbers submitted, they are either the individual digits between 1 and 4 or numbers added sequentially to 1, such as "12", "123", or "1234".
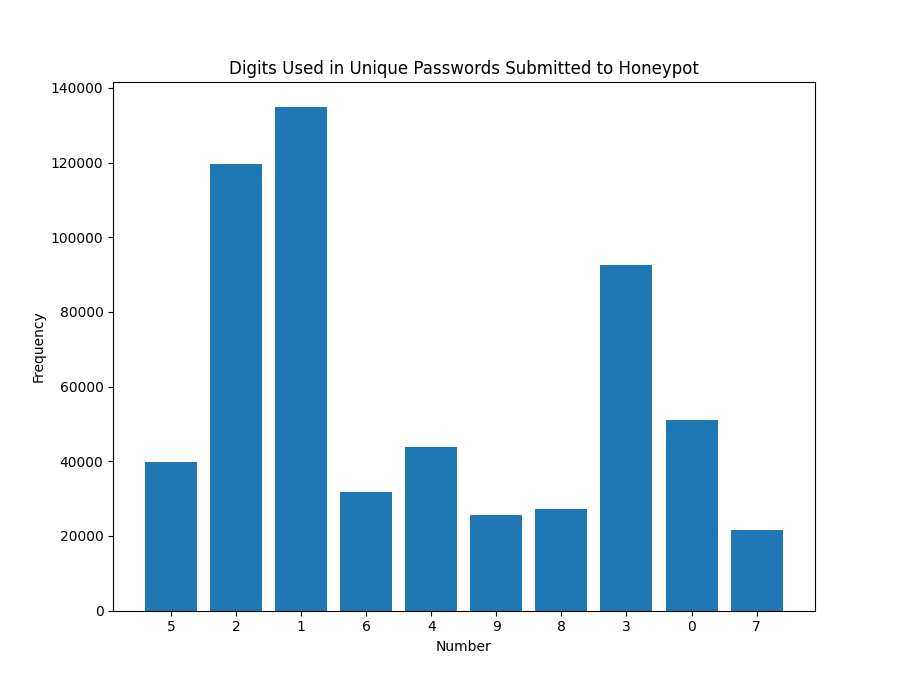
Figure 2: Top 10 digits used most often within passwords submitted to a honeypot
Of the individual digits used, whether alone or within a larger number, the most commonly used in order are 1, 2 and 3. Generally, the lower the number, the more frequently it is used. 0 is a bit of an outlier. This may mean that most of the time, passwords may be used with incrementing numbers when changed, or simply appended with the next highest number. This isn't too surprising, but interesting to see within the data.
What about years? Well, the same method was used, but looking for contiguous numbers of length 4.
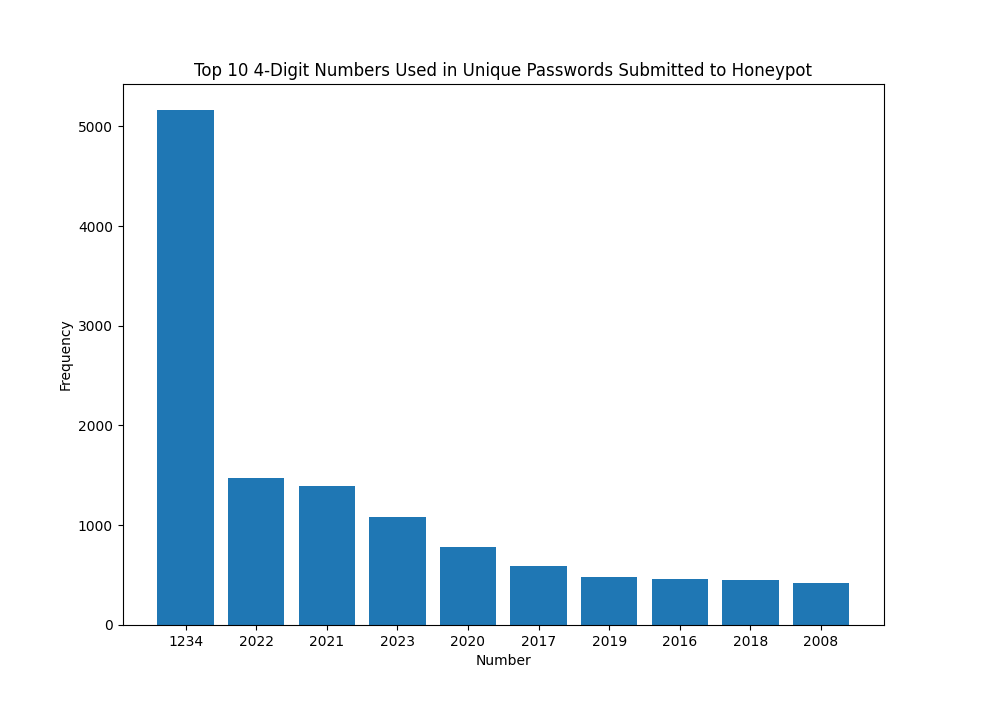
Figure 3: Top 10 numbers used within passwords containing only 4 digits
Outside of "1234", most of the values to appear to be years, with higher numbers generally seen for more recent years. Is there any difference in these values if submitted in a different year? While this could also be done in python, values for specific years were extacted with 'jq'.
# read all cowrie JSON files
# cat /logs/cowrie.json*
# select data with the password key present and with timestamps between 1/1/2022 and 12/31/2022
# jq 'select((.password) and (.timestamp >= "2022-01-01") and (.timestamp <= "2022-12-31"))'
# select password values without quotes (raw)
# jq -r .password
# get unique password values and save to a file
# sort | uniq > 2022_unique_passwords_submitted.txt
cat /logs/cowrie.json* | jq 'select((.password) and (.timestamp >= "2022-01-01") and (.timestamp <= "2022-12-31"))' | jq -r .password | sort | uniq > 2022_unique_passwords_submitted.txt
cat /logs/cowrie.json* | jq 'select((.password) and (.timestamp >= "2023-01-01") and (.timestamp <= "2023-12-31"))' | jq -r .password | sort | uniq > 2023_unique_passwords_submitted.txt
cat /logs/cowrie.json* | jq 'select((.password) and (.timestamp >= "2024-01-01") and (.timestamp <= "2024-12-31"))' | jq -r .password | sort | uniq > 2024_unique_passwords_submitted.txt
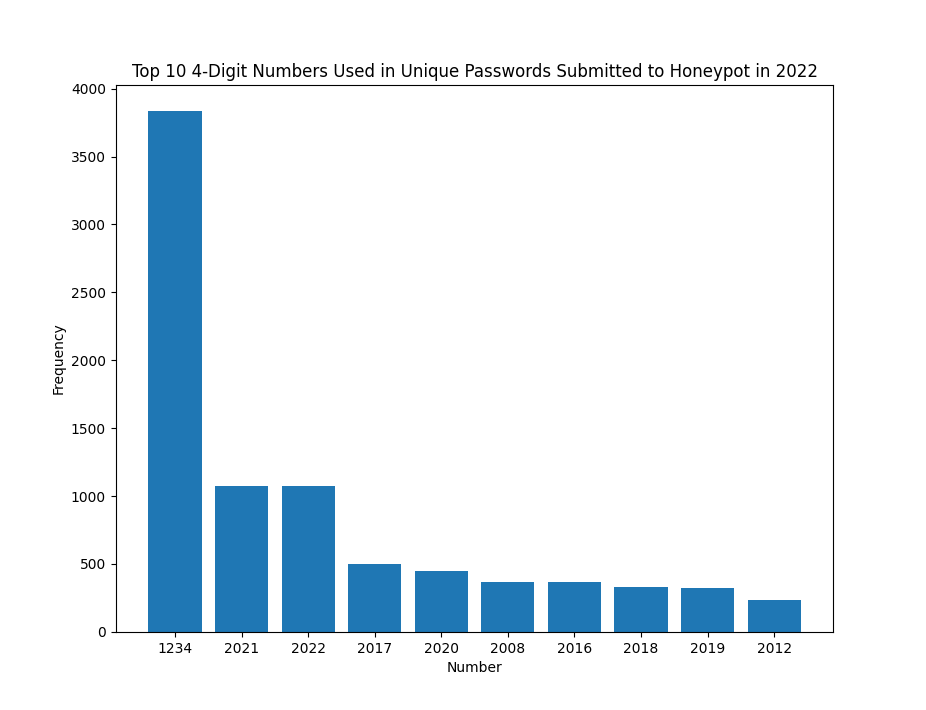
Figure 4: Top 10 4-digit numbers contained in passwords submitted to a honeypot in 2022
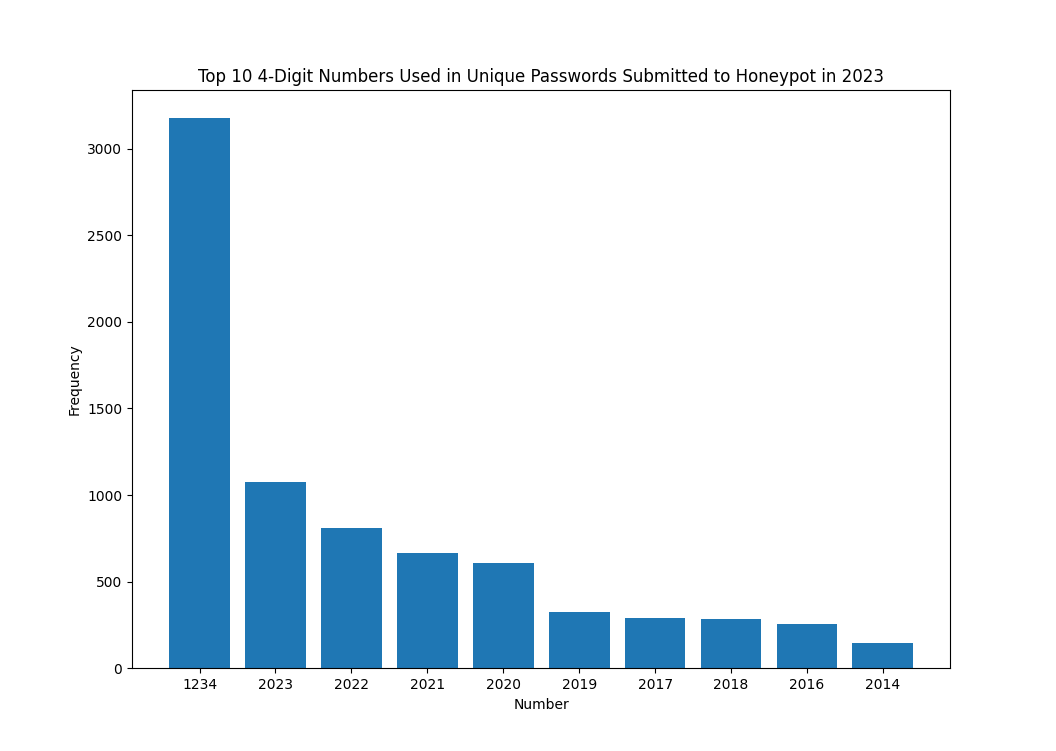
Figure 5: Top 10 4-digit numbers contained in passwords submitted to a honeypot in 2023
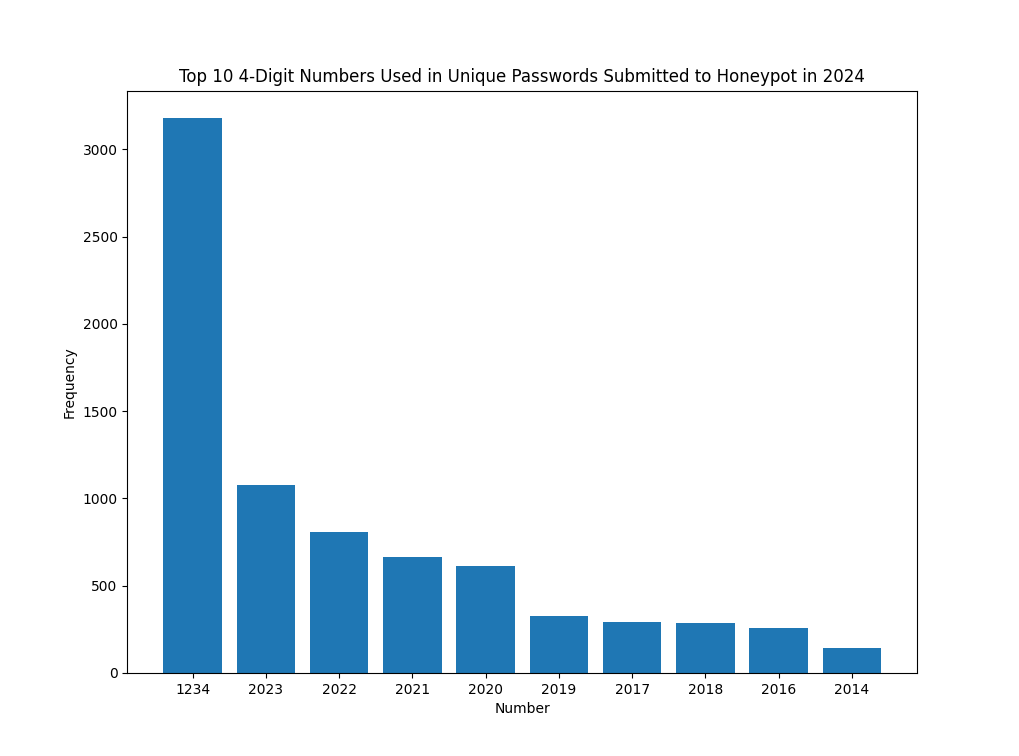
Figure 6: Top 10 4-digit numbers contained in passwords submitted to a honeypot in 2024
Overall, the 4-digit numbers used within passwords submitted appear to be heavily influenced by the year in which they were submitted. The number 2024 is not heavily reflected, but is present in the data, with a total of 9 passwords containing this value. This was as of 1/7/2024.
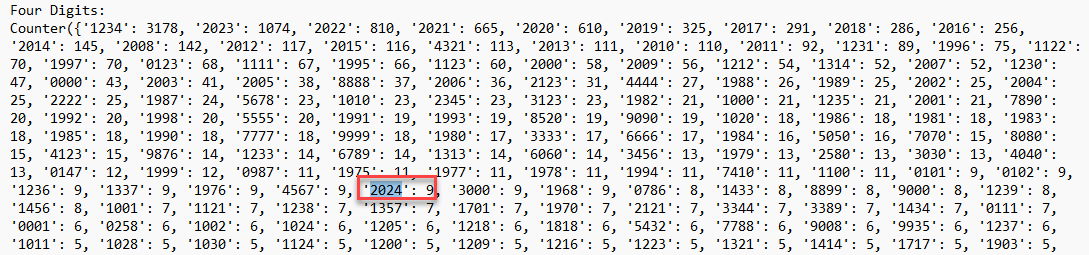
Figure 7: Counts of 4-digit numbers seen within passwords, highlighting "2024" occurences
With some updated data including the last week, I went ahead and graphed when the numbers "2022", "2023" and "2024" were present within a submitted password. Unlike the previous data used, this was not deduplicated since it would truncate the dates identified when these values were submitted.
# read the cowrie JSON logs files
# cat /logs/cowrie.json*
# select data where the password key was present
# jq 'select(.password)'
# select submission timestamp and password
# delimited with " DELIMIT " since passwords may use common delimiting characters
# save passwords and submission timestamps to file
# jq '.timestamp + " DELIMIT " + .password' > 2024-01-13_passwords_submitted.txt
cat /logs/cowrie.json* | jq 'select(.password)' | jq '.timestamp + " DELIMIT " + .password' > 2024-01-13_passwords_submitted.txt
import pandas as pd
import re
import matplotlib.pyplot as plt
def return_matched_timestamps(string_to_match):
incrementer = 0
matched_timestamps = []
while incrementer < len(passwords):
match = 0
#print(passwords[incrementer])
numbers = re.findall(r'd+', passwords[incrementer])
for each_number in numbers:
if str(each_number) == string_to_match:
match = 1
if match == 1:
matched_timestamps.append(timestamps[incrementer])
incrementer += 1
return matched_timestamps
df = pd.read_csv("2024-01-13_passwords_submitted.txt", names=["Date", "Password"], sep=" DELIMIT", engine="python", parse_dates=["Date"], na_filter=False)
timestamps = df['Date'].tolist()
passwords = df['Password'].tolist()
timestamps_2024 = return_matched_timestamps("2024")
timestamps_2023 = return_matched_timestamps("2023")
timestamps_2022 = return_matched_timestamps("2022")
df_2022 = pd.DataFrame(timestamps_2022)
by_month_2022 = pd.to_datetime(df_2022[0]).dt.to_period('M').value_counts().sort_index()
df_month_2022 = by_month_2022.rename_axis('month').reset_index(name='counts')
df_2023 = pd.DataFrame(timestamps_2023)
by_month_2023 = pd.to_datetime(df_2023[0]).dt.to_period('M').value_counts().sort_index()
df_month_2023 = by_month_2023.rename_axis('month').reset_index(name='counts')
df_2024 = pd.DataFrame(timestamps_2024)
by_month_2024 = pd.to_datetime(df_2024[0]).dt.to_period('M').value_counts().sort_index()
df_month_2024 = by_month_2024.rename_axis('month').reset_index(name='counts')
plt.plot_date(df_month_2022['month'], df_month_2022['counts'], 'b-', label="Contains '2022'")
plt.plot_date(df_month_2023['month'], df_month_2023['counts'], 'r-', label="Contains '2023'")
plt.plot_date(df_month_2024['month'], df_month_2024['counts'], 'g-', label="Contains '2024'")
plt.xlabel("Date (broken down by month)")
plt.ylabel("Passwords Submitted")
plt.legend(loc="upper left")
plt.show()
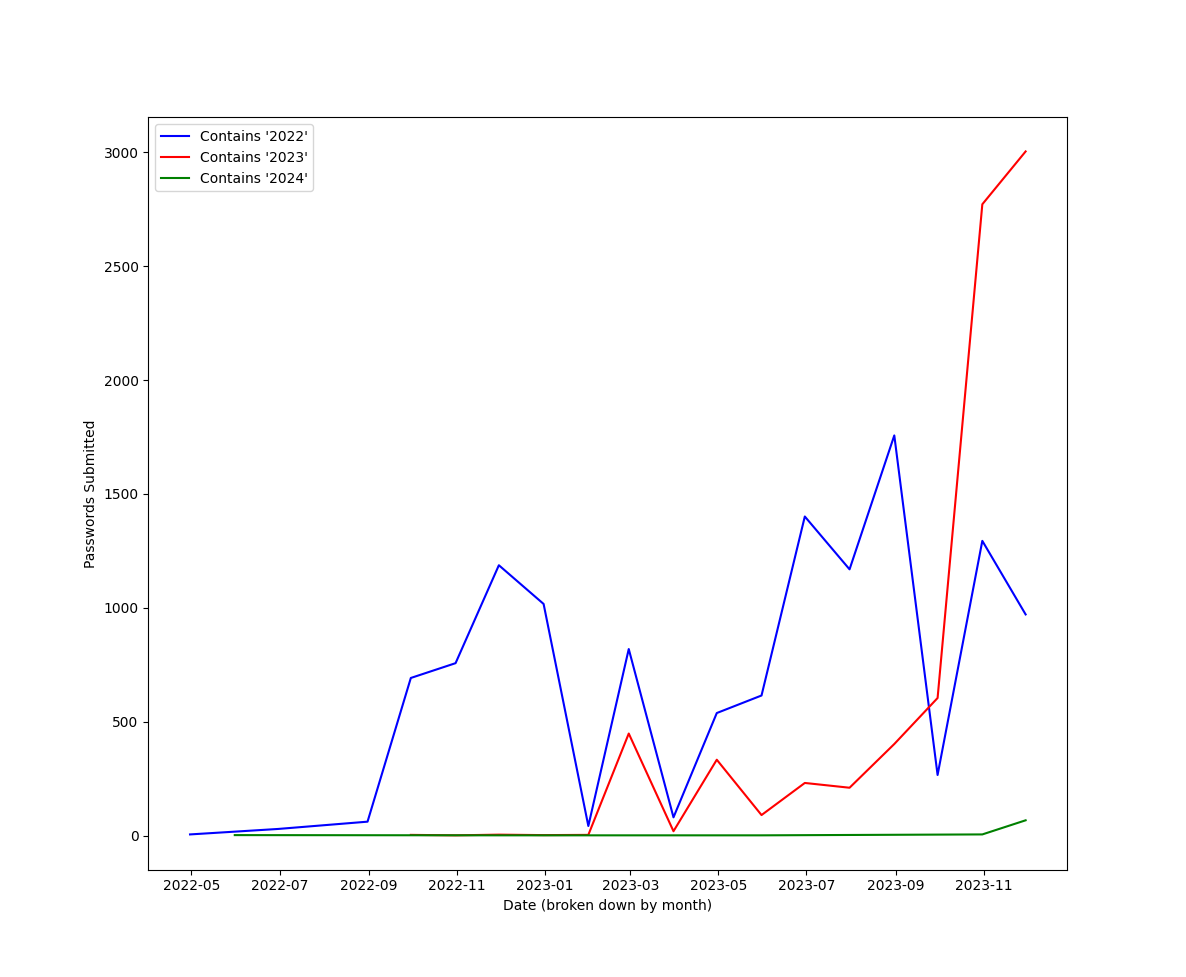
Figure 8: Graph of individual passwords submitted each month including "2022", "2023" or "2024"
The incorporation of "2023" and "2024" increase close to the beginning of that year. These was a steep increase in the use of "2023" seen on this honeypot in November of 2023.
Probably a good idea to avoid using the current year in your password, or any recent year in general.
—
Jesse La Grew
Handler
(c) SANS Internet Storm Center. https://isc.sans.edu Creative Commons Attribution-Noncommercial 3.0 United States License.