The new Amazon S3 Express One Zone storage class is designed to deliver up to 10x better performance than the S3 Standard storage class while handling hundreds of thousands of requests per second with consistent single-digit millisecond latency, making it a great fit for your most frequently accessed data and your most demanding applications. Objects are stored and replicated on purpose built hardware within a single AWS Availability Zone, allowing you to co-locate storage and compute (Amazon EC2, Amazon ECS, and Amazon EKS) resources to further reduce latency.
Amazon S3 Express One Zone
With very low latency between compute and storage, the Amazon S3 Express One Zone storage class can help to deliver a significant reduction in runtime for data-intensive applications, especially those that use hundreds or thousands of parallel compute nodes to process large amounts of data for AI/ML training, financial modeling, media processing, real-time ad placement, high performance computing, and so forth. These applications typically keep the data around for a relatively short period of time, but access it very frequently during that time.
This new storage class can handle objects of any size, but is especially awesome for smaller objects. This is because for smaller objects the time to first byte is very close to the time for last byte. In all storage systems, larger objects take longer to stream because there is more data to download during the transfer, and therefore the storage latency has less impact on the total time to read the object. As a result, smaller objects receive an outsized benefit from lower storage latency compared to large objects. Because of S3 Express One Zone’s consistent very low latency, small objects can be read up to 10x faster compared to S3 Standard.
The extremely low latency provided by Amazon S3 Express One Zone, combined with request costs that are 50% lower than for the S3 Standard storage class, means that your Spot and On-Demand compute resources are used more efficiently and can be shut down earlier, leading to an overall reduction in processing costs.
Each Amazon S3 Express One Zone directory bucket exists in a single Availability Zone that you choose, and can be accessed using the usual set of S3 API functions: CreateBucket, PutObject, GetObject, ListObjectsV2, and so forth. The buckets also support a carefully chosen set of S3 features including byte-range fetches, multi-part upload, multi-part copy, presigned URLs, and Access Analyzer for S3. You can upload objects directly, write code that uses CopyObject, or use S3 Batch Operations,
In order to reduce latency and to make this storage class as efficient & scalable as possible, we are introducing a new bucket type, a new authentication model, and a bucket naming convention:
New bucket type – The new directory buckets are specific to this storage class, and support hundreds of thousands of requests per second. They have a hierarchical namespace and store object key names in a directory-like manner. The path delimiter must be “/“, and any prefixes that you supply to ListObjectsV2 must end with a delimiter. Also, list operations return results without first sorting them, so you cannot do a “start after” retrieval.
New authentication model – The new CreateSession function returns a session token that grants access to a specific bucket for five minutes. You must include this token in the requests that you make to other S3 API functions that operate on the bucket or the objects in it, with the exception of CopyObject, which requires IAM credentials. The newest versions of the AWS SDKs handle session creation automatically.
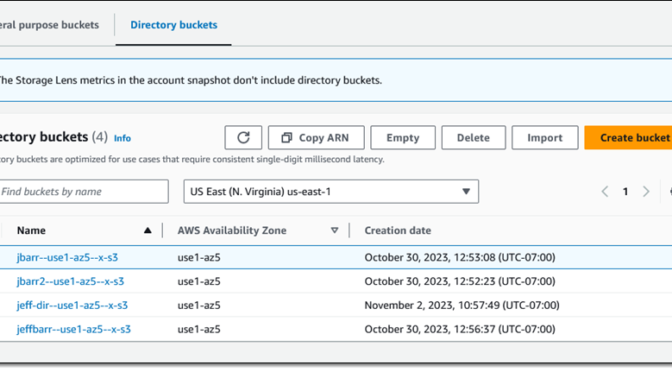
Bucket naming – Directory bucket names must be unique within their AWS Region, and must specify an Availability Zone ID in a specially formed suffix. If my base bucket name is jbarr and it exists in Availability Zone use1-az5 (Availability Zone 5 in the US East (N. Virginia) Region) the name that I supply to CreateBucket would be jbarr--use1-az5--x-s3. Although the bucket exists within a specific Availability Zone, it is accessible from the other zones in the region, and there are no data transfer charges for requests from compute resources in one Availability Zone to directory buckets in another one in the same region.
Amazon S3 Express One Zone in action
Let’s put this new storage class to use. I will focus on the command line, but AWS Management Console and API access are also available.
My EC2 instance is running in my us-east-1f Availability Zone. I use jq to map this value to an Availability Zone Id:
I create a bucket configuration (s3express-bucket-config.json) and include the Id:
After installing the newest version of the AWS Command Line Interface (AWS CLI), I create my directory bucket:
Then I can use the directory bucket as the destination for other CLI commands as usual (the second aws is the directory where I unzipped the AWS CLI):
When I list the directory bucket’s contents, I see that the StorageClass is EXPRESS_ONEZONE:
The Management Console for S3 shows General purpose buckets and Directory buckets on separate tabs:
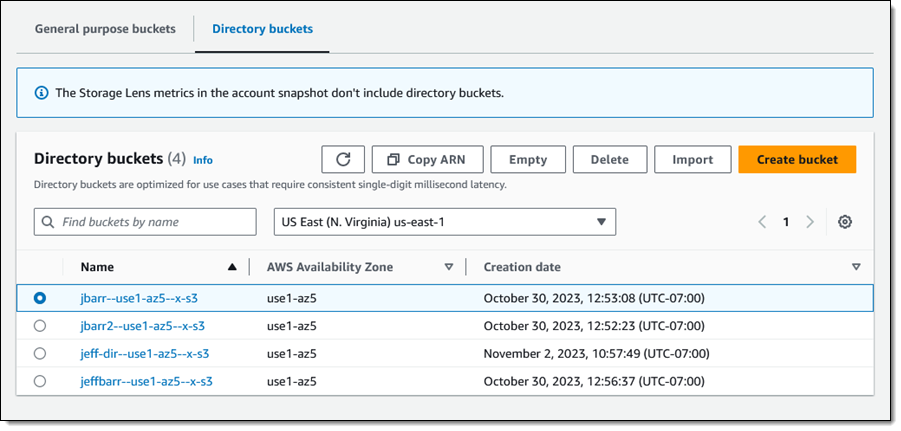
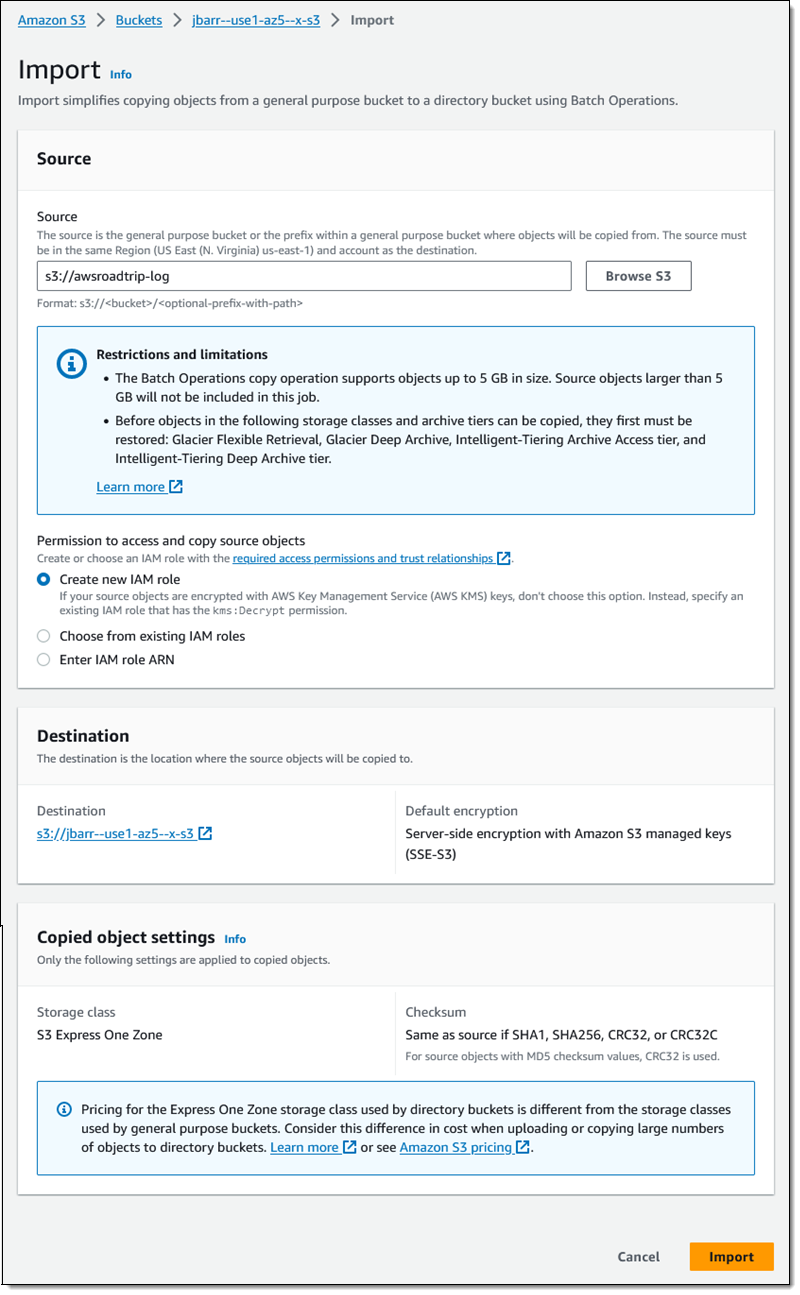
I can import the contents of an existing bucket (or a prefixed subset of the contents) into a directory bucket using the Import button, as seen above. I select a source bucket, click Import, and enter the parameters that will be used to generate an inventory of the source bucket and to create and an S3 Batch Operations job.
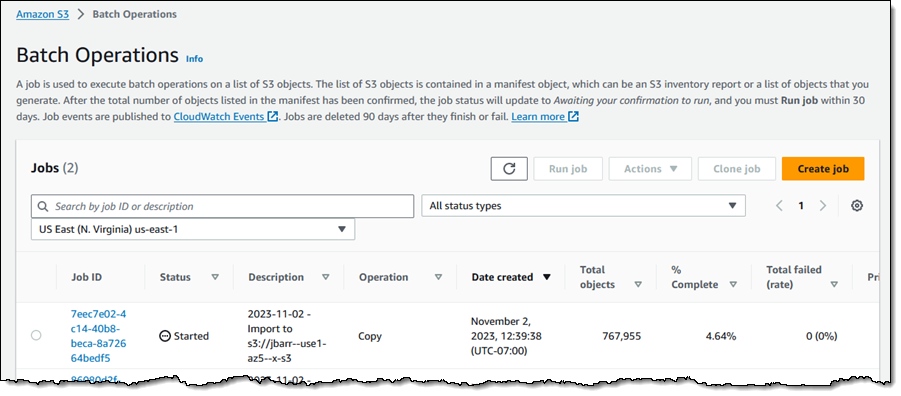
The job is created and begins to execute:
Things to know
Here are some important things to know about this new S3 storage class:
Regions – Amazon S3 Express One Zone is available in the US East (N. Virginia), US West (Oregon), Asia Pacific (Tokyo), and Europe (Stockholm) Regions, with plans to expand to others over time.
Other AWS Services – You can use Amazon S3 Express One Zone with other AWS services including Amazon SageMaker Model Training, Amazon Athena, Amazon EMR, and AWS Glue Data Catalog to accelerate your machine learning and analytics workloads. You can also use Mountpoint for Amazon S3 to process your S3 objects in file-oriented fashion.
Pricing – Pricing, like the other S3 storage classes, is on a pay-as-you-go basis. You pay $0.16/GB/month in the US East (N. Virginia) Region, with a one-hour minimum billing time for each object, and additional charges for certain request types. You pay an additional per-GB fee for the portion of any request that exceeds 512 KB. For more information, see the Amazon S3 Pricing page.
Durability – In the unlikely case of the loss or damage to all or part of an AWS Availability Zone, data in a One Zone storage class may be lost. For example, events like fire and water damage could result in data loss. Apart from these types of events, our One Zone storage classes use similar engineering designs as our Regional storage classes to protect objects from independent disk, host, and rack-level failures, and each are designed to deliver 99.999999999% data durability.
SLA – Amazon S3 Express One Zone is designed to deliver 99.95% availability with an availability SLA of 99.9%; for information see the Amazon S3 Service Level Agreement page.
This new storage class is available now and you can start using it today!
Learn more
Amazon S3 Express One Zone
— Jeff;