This
post was originally published on
this siteIf you manage TLS certificates for your applications, you know the challenge: certificates expire, and when they do, your customers see errors or your service goes down. As certificate validity periods get shorter (the Certification Authority (CA)/Browser Forum mandates reduced maximum validity to 100 days starting March 2027, and to 47 days by 2029), manual renewal processes become untenable. You need automation.
Automatic Certificate Management Environment (ACME) is an open protocol for requesting, renewing, and revoking TLS certificates without human intervention. It’s the same protocol behind Let’s Encrypt, and it’s supported by dozens of clients across every platform.
Today we’re announcing ACME support for public certificates in AWS Certificate Manager (ACM). ACM now provides a fully managed ACME server endpoint that works with any ACMEv2-compatible client, such as Certbot, cert-manager for Kubernetes, acme.sh, or any other client you already use. You can issue public TLS certificates from Amazon Trust Services through the standard ACME protocol.
Before today, if you wanted automated certificate management using the ACME protocol, you relied on external certificate authorities alongside ACM, leading to a fragmented visibility experience. Some certificates lived in ACM, others were managed externally with no central dashboard. PKI administrators had limited ability to control who could request certificates or which domains were allowed.
With ACME support in ACM, you can now set up one or more managed ACME endpoint that allows you to centrally manage and monitor ACME certificate usage across your organization.
As a PKI administrator, you get centralized controls that go beyond basic certificate issuance. You can bind IAM roles to ACME accounts for fine-grained access control over which domains each client can request. You can define domain scopes at the endpoint level to enforce organization-wide policies. And you get centralized monitoring and visibility in the same place: AWS CloudTrail logs every certificate request for auditability, Amazon CloudWatch tracks operational metrics, and ACM sends expiry notifications when certificates are approaching renewal. Using ACM, your PKI team can search all certificates, whether issued through the ACM console, an API call, or ACME.
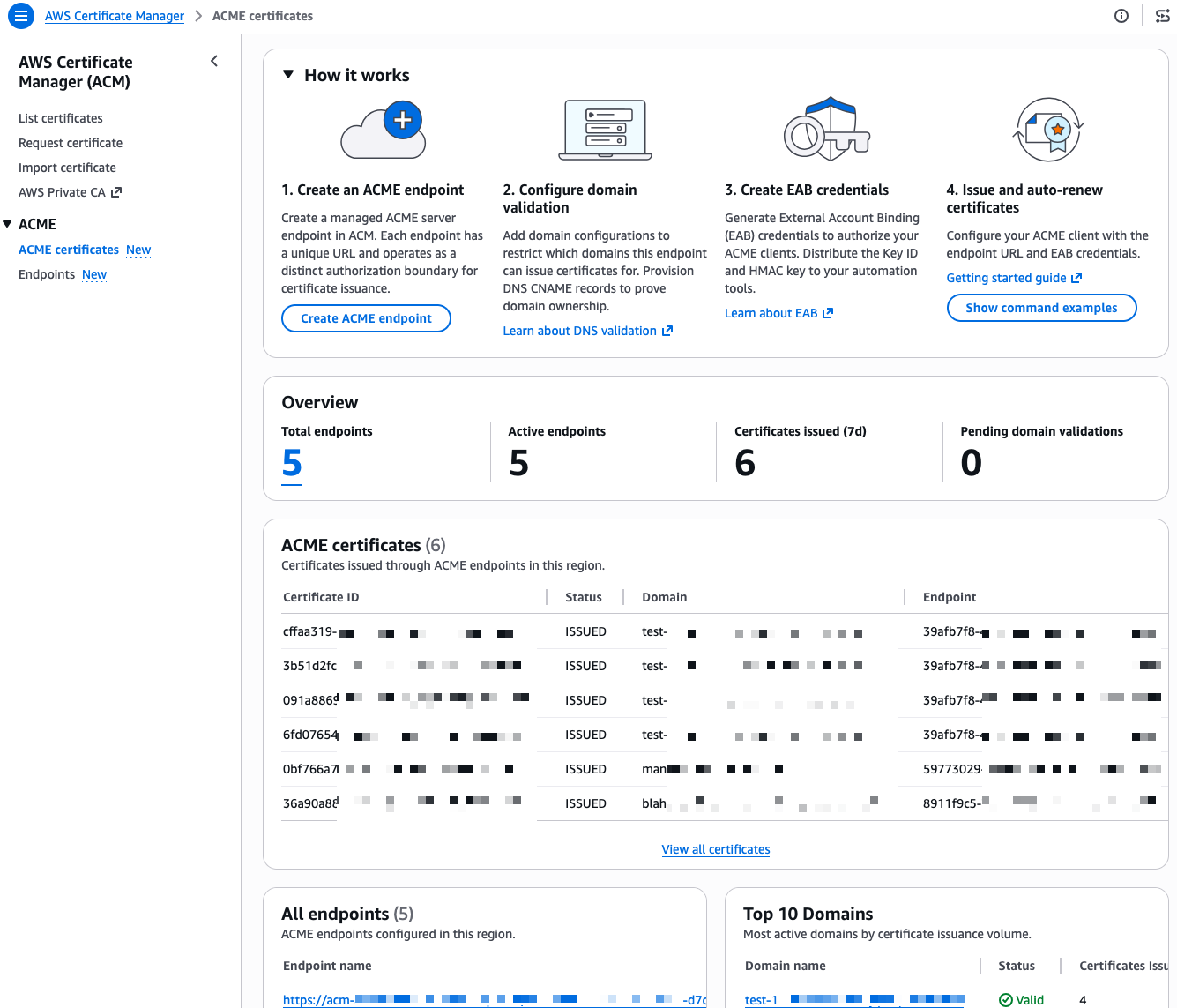
How it works
To get started, you first set up a dedicated ACME endpoint, configure authorization controls using External Account Binding (EAB), validate which domains the endpoint can issue certificates for, and point your existing ACME clients to the new endpoint.
The domain validation step is important: it separates who can set up certificate issuance from who can request certificates. The PKI administrator validates domains once at the endpoint level, using DNS credentials that stay with the admin. Application owners who need certificates never touch DNS. They register with an EAB credential, and the endpoint enforces which domains and scopes they’re allowed to request. This means you can distribute certificate automation broadly across your organization without distributing DNS keys along with it.
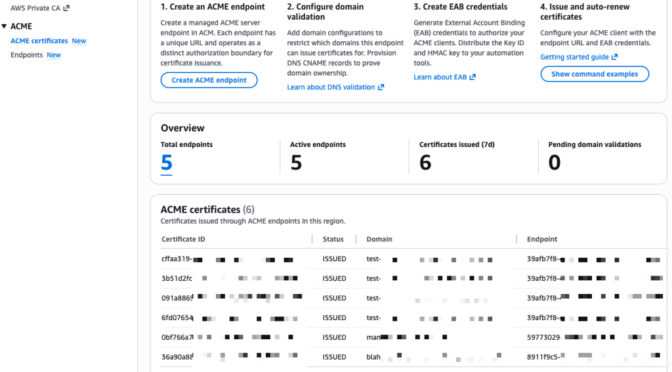
I start this demo from the ACME certificates page in the AWS Certificate Manager console.
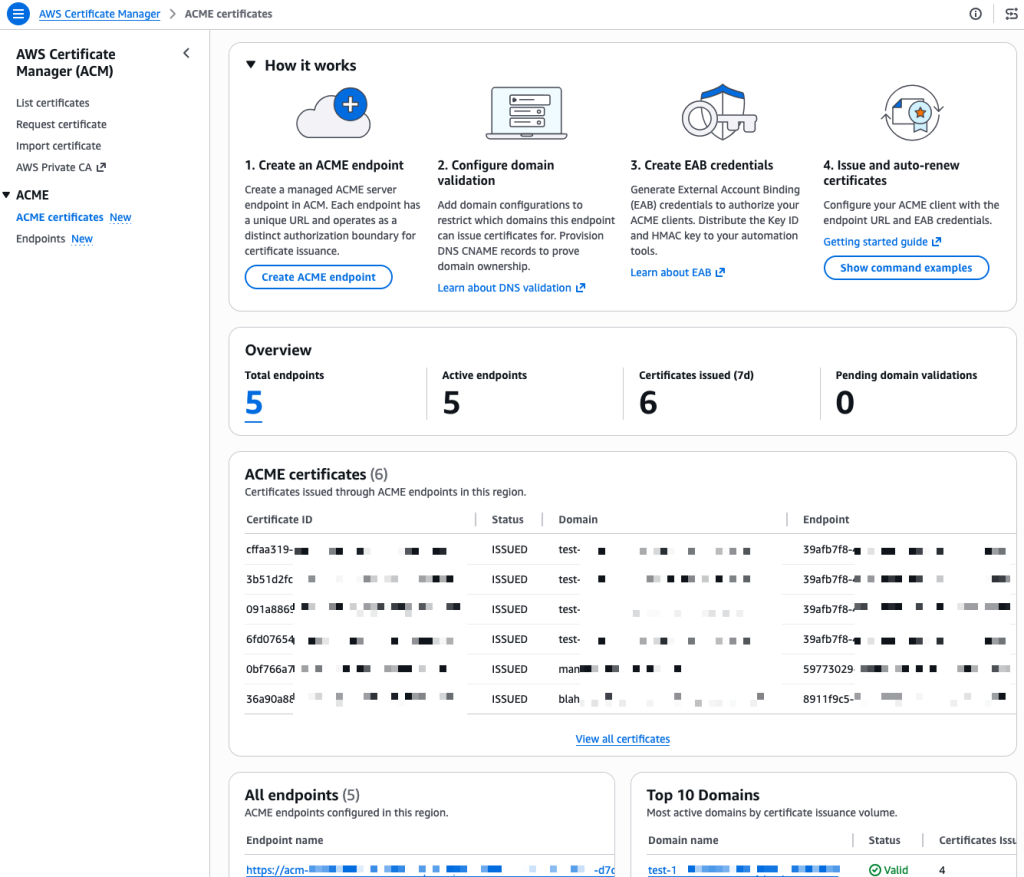
I already have a few endpoints and certificates in this account, I walk you through creating a new one from scratch. First, I select Create ACME endpoint.
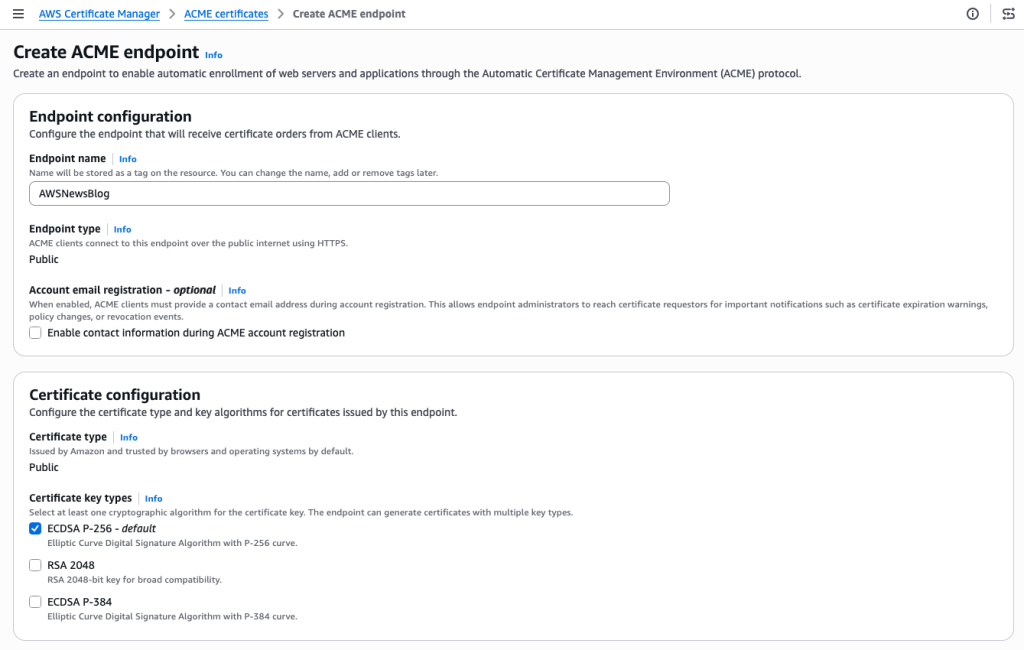
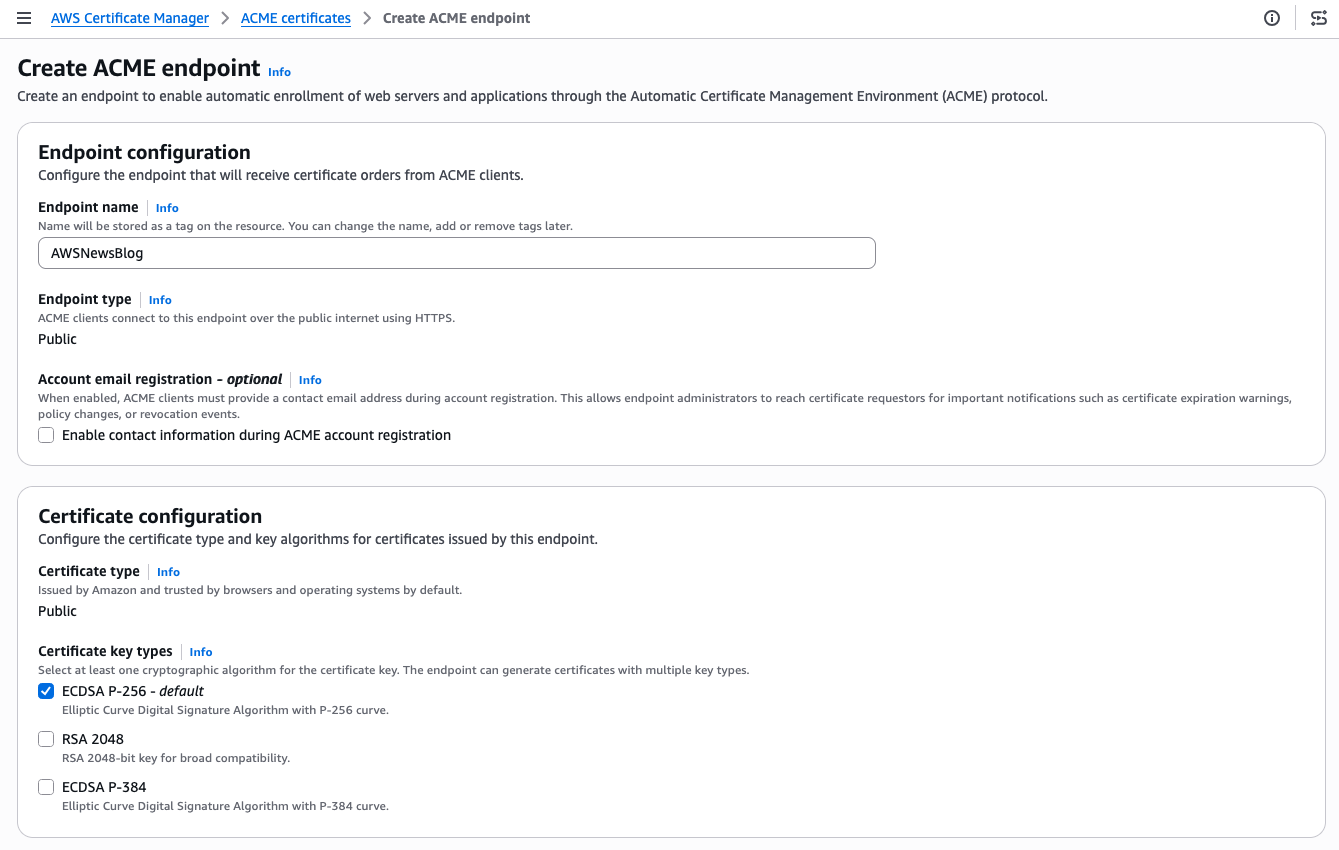
I give my endpoint a name. The Endpoint type is Public. ACME clients will connect over the public internet. The Certificate type is Public. The certificate will be issued by Amazon Trust Services and trusted by browsers and operating systems by default. For the certificate key type, I keep the default ECDSA P-256. RSA 2048 and ECDSA P-384 are also available if your clients require them.
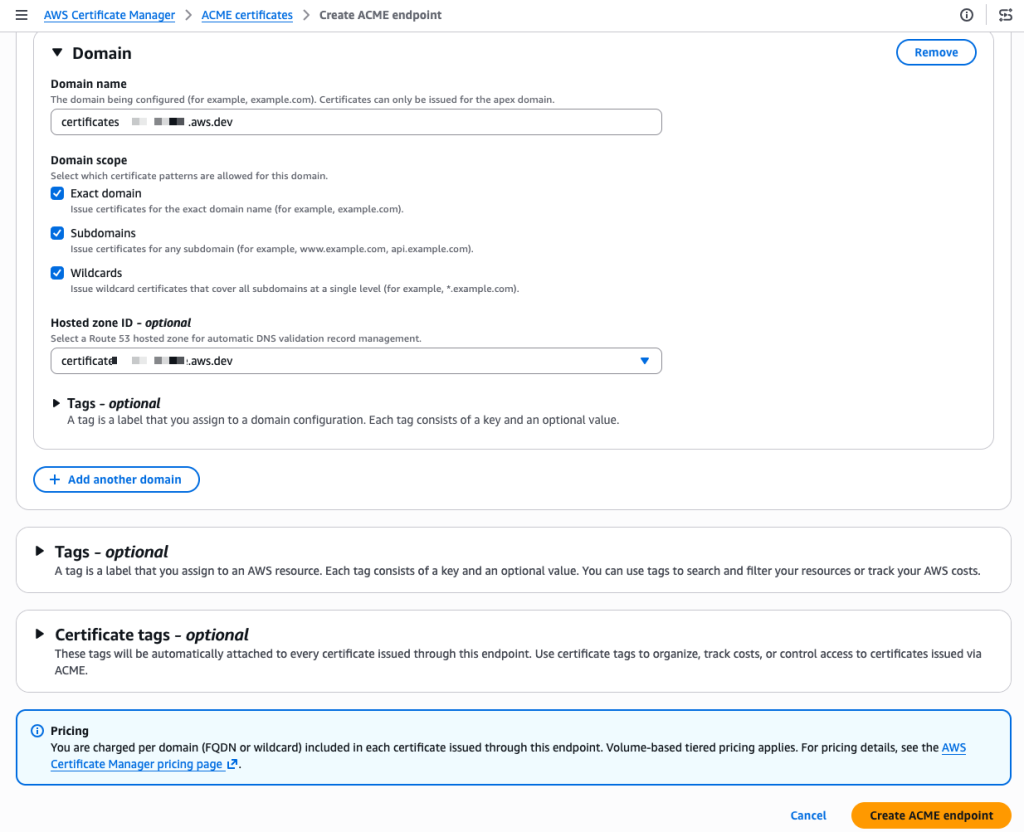
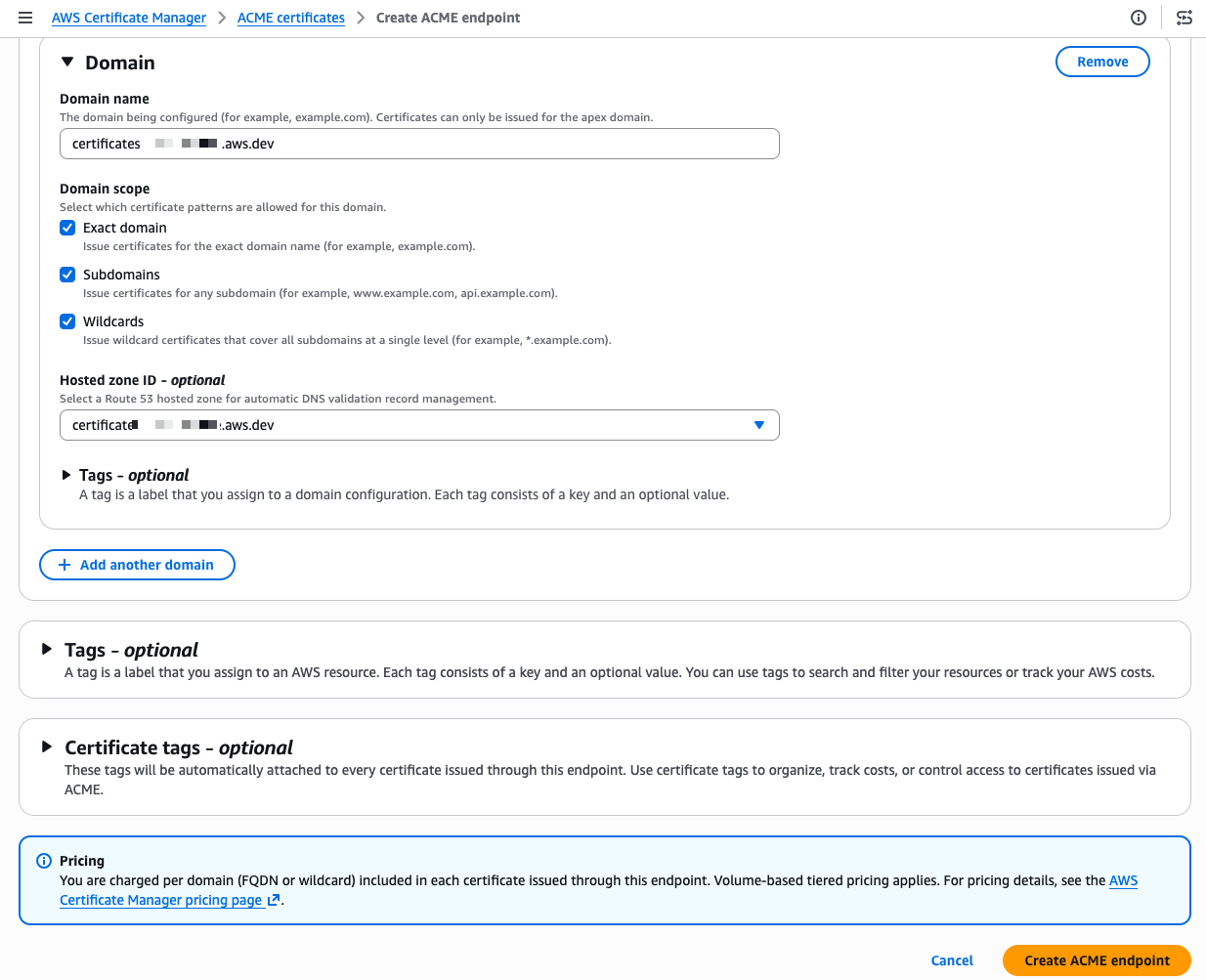
Scrolling down, I configure the domain. I enter my domain name and select the domain scope. The scope controls exactly what certificate patterns your ACME clients are allowed to request for this domain. If I check only Exact domain, clients can only request certificates for that specific domain name. Adding Subdomains allows certificates for any subdomain (for example, api.example.com or dev.example.com). Adding Wildcards allows wildcard certificates (*.example.com). By leaving a scope unchecked, you prevent any client using this endpoint from requesting that type of certificate, even if their ACME request is otherwise valid. For a production endpoint, you might enable only Exact domain and Subdomains while leaving Wildcards unchecked to enforce a stricter security posture.
I also select my Amazon Route 53 hosted zone from the drop down menu. ACM then automatically creates the DNS CNAME records needed for domain validation, so I don’t have to do it manually. When my domain is hosted outside of Route 53, I manually create the provided CNAME record at my DNS provider instead. This is a meaningful difference from typical ACME setups where each client handles its own domain verification independently.
These centralized controls give PKI administrators a single place to authenticate domains, restrict which certificate types (ECDSA or RSA) clients can request, and further limit wildcard issuance. Having these governance capabilities built in means you don’t need to purchase a separate certificate lifecycle management product or invest in building a custom policy layer yourself, both of which come at significant cost and operational overhead.
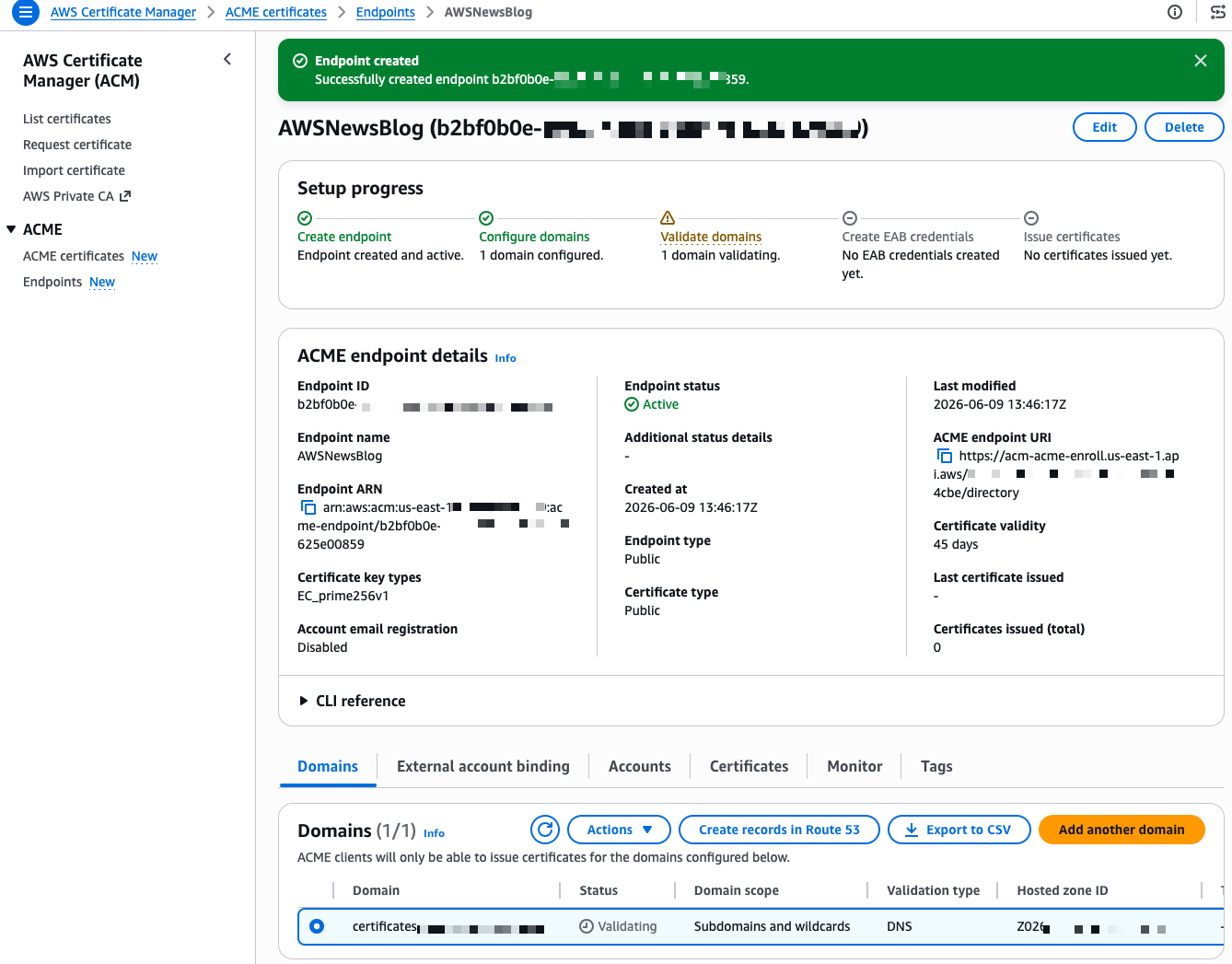
I select Create ACME endpoint
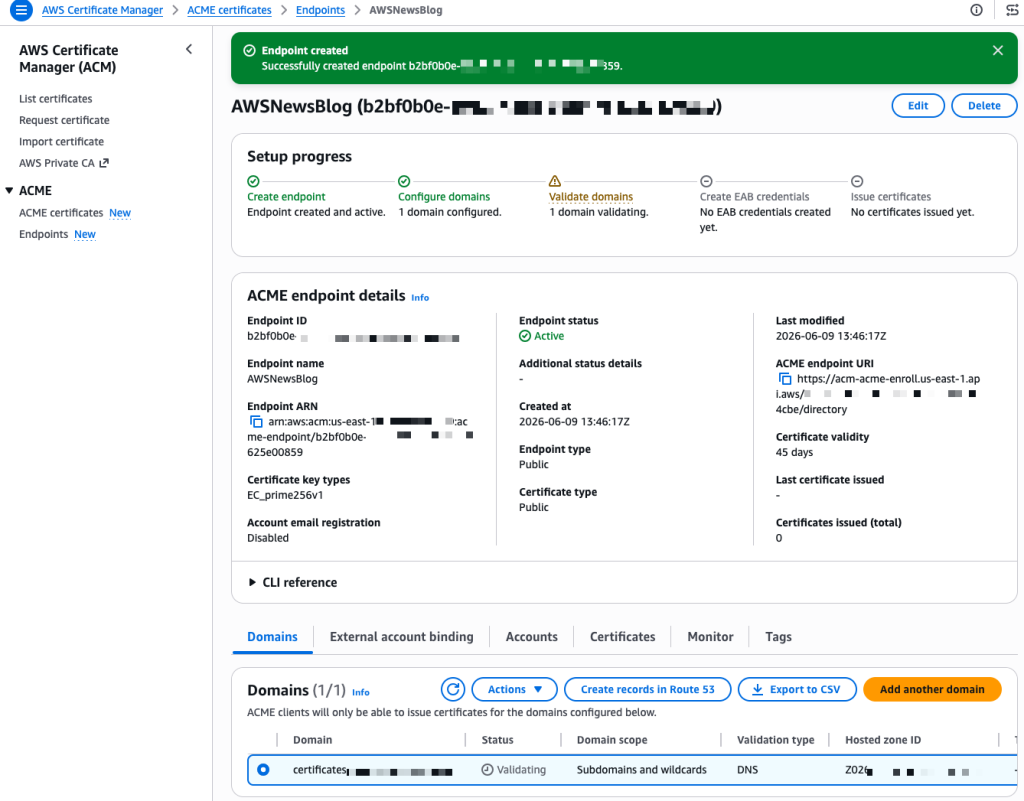
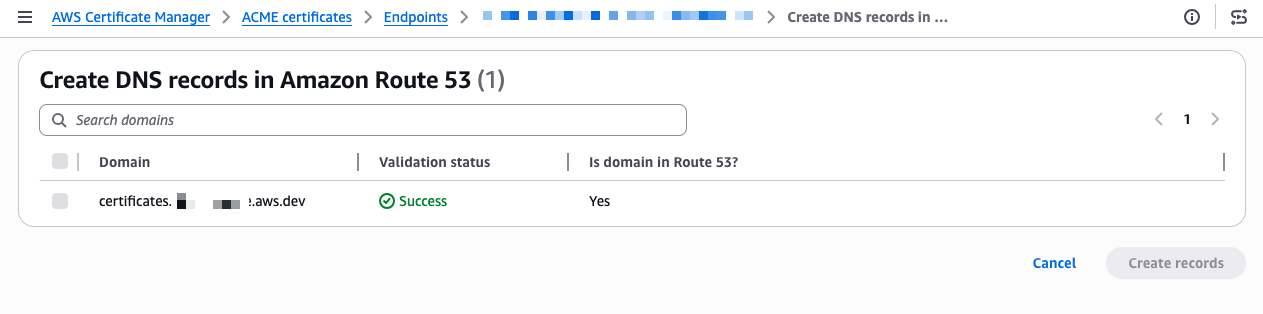
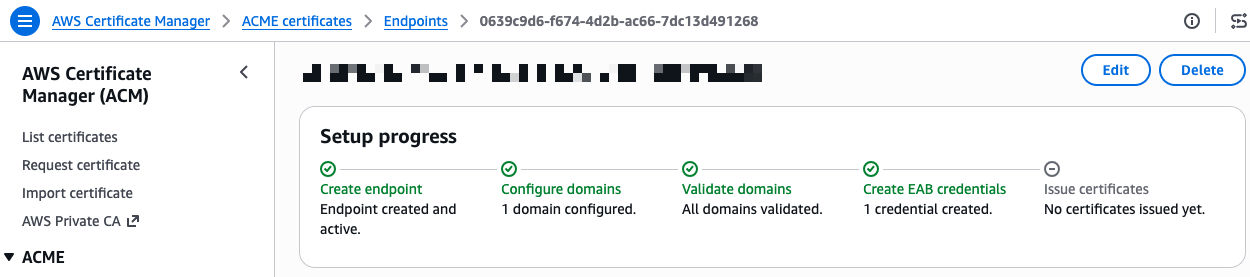
After a few seconds, the endpoint is created. The console shows a Setup progress tracker with the next steps. My domain shows a “Validating” status. The validation method is DNS validation, where ACM verifies that you control the domain by checking for a specific CNAME record. Because I selected my Route 53 hosted zone during creation, I select Create records in Route 53 to let ACM handle the DNS validation automatically.
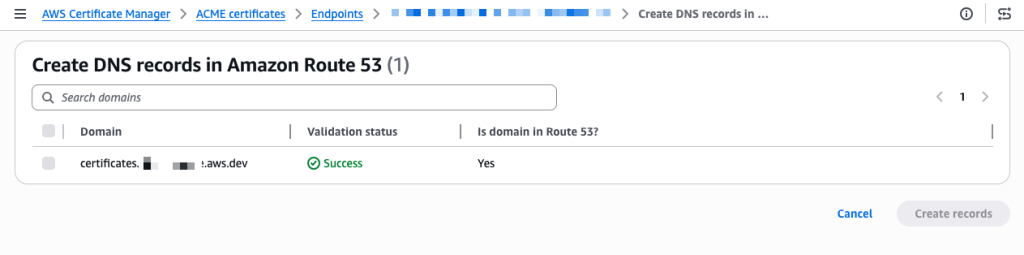 The validation completes in a few seconds and the status changes to Success.
The validation completes in a few seconds and the status changes to Success.
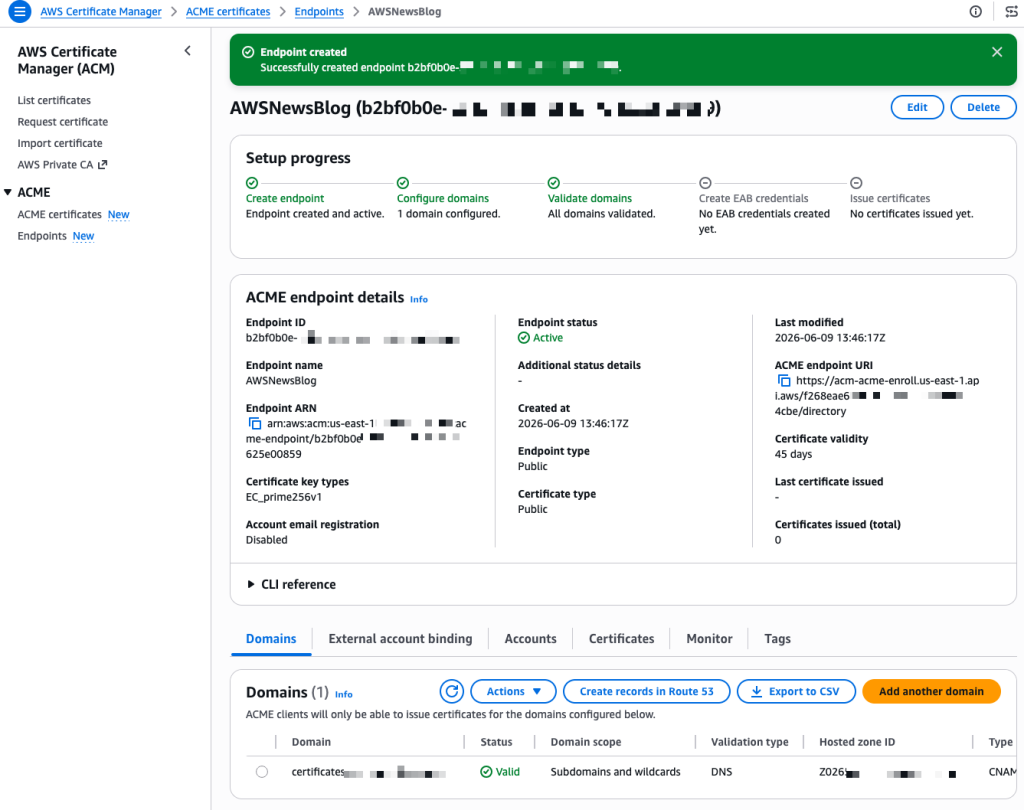
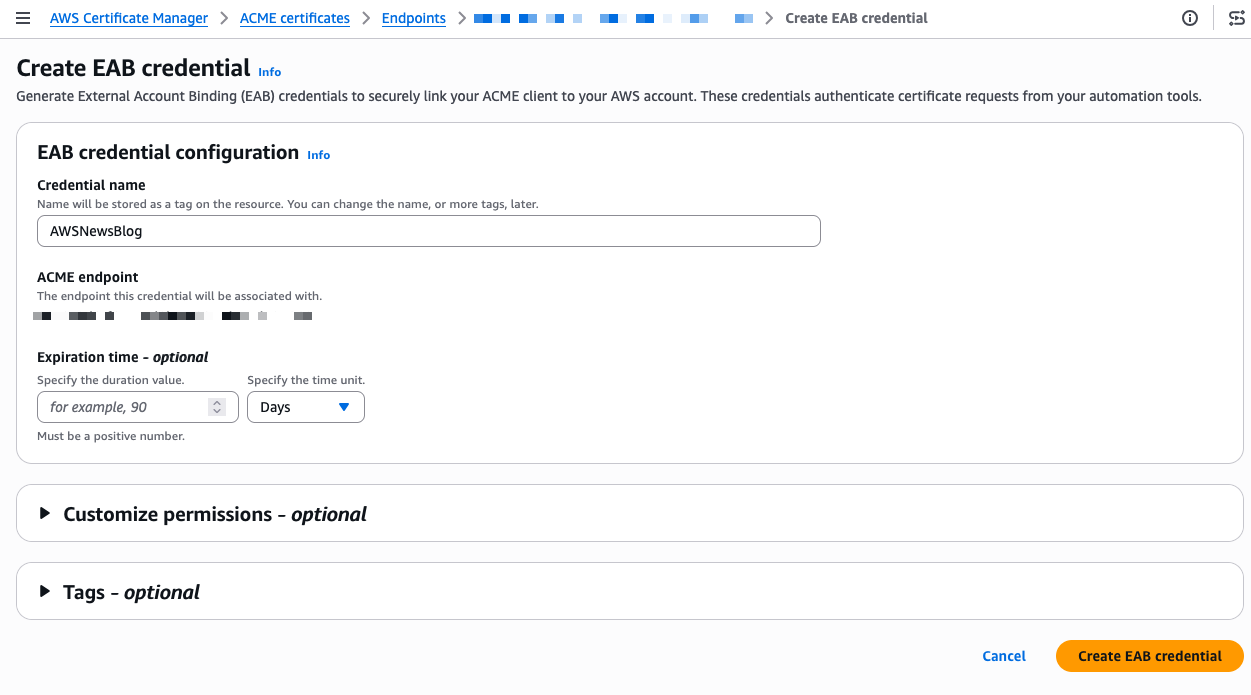
Now I need to create External Account Binding (EAB) credentials. EAB credentials are a key identifier and HMAC key pair that lets your ACME client register an account with the ACME server. Once registered, the client generates its own asymmetric key pair, which is then used to authenticate all subsequent certificate requests. On the endpoint details page, I select the External account binding tab, then select Create EAB. I give the credential a name and optionally set an expiration time, ideally no longer than needed to complete client registration.
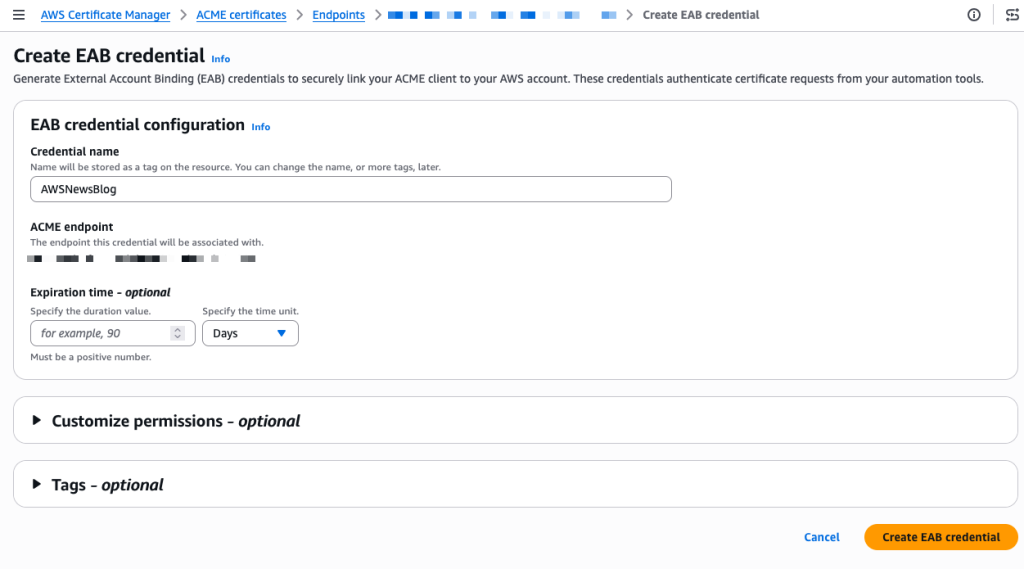
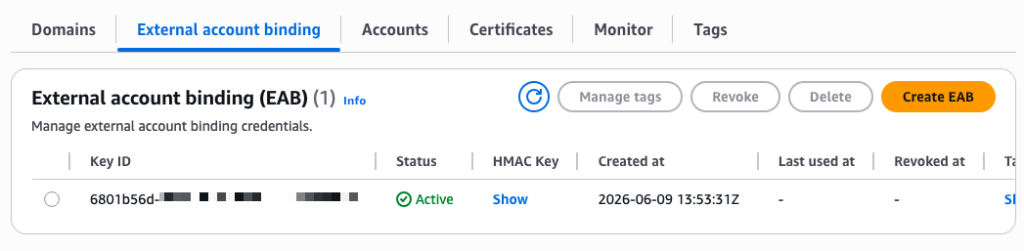
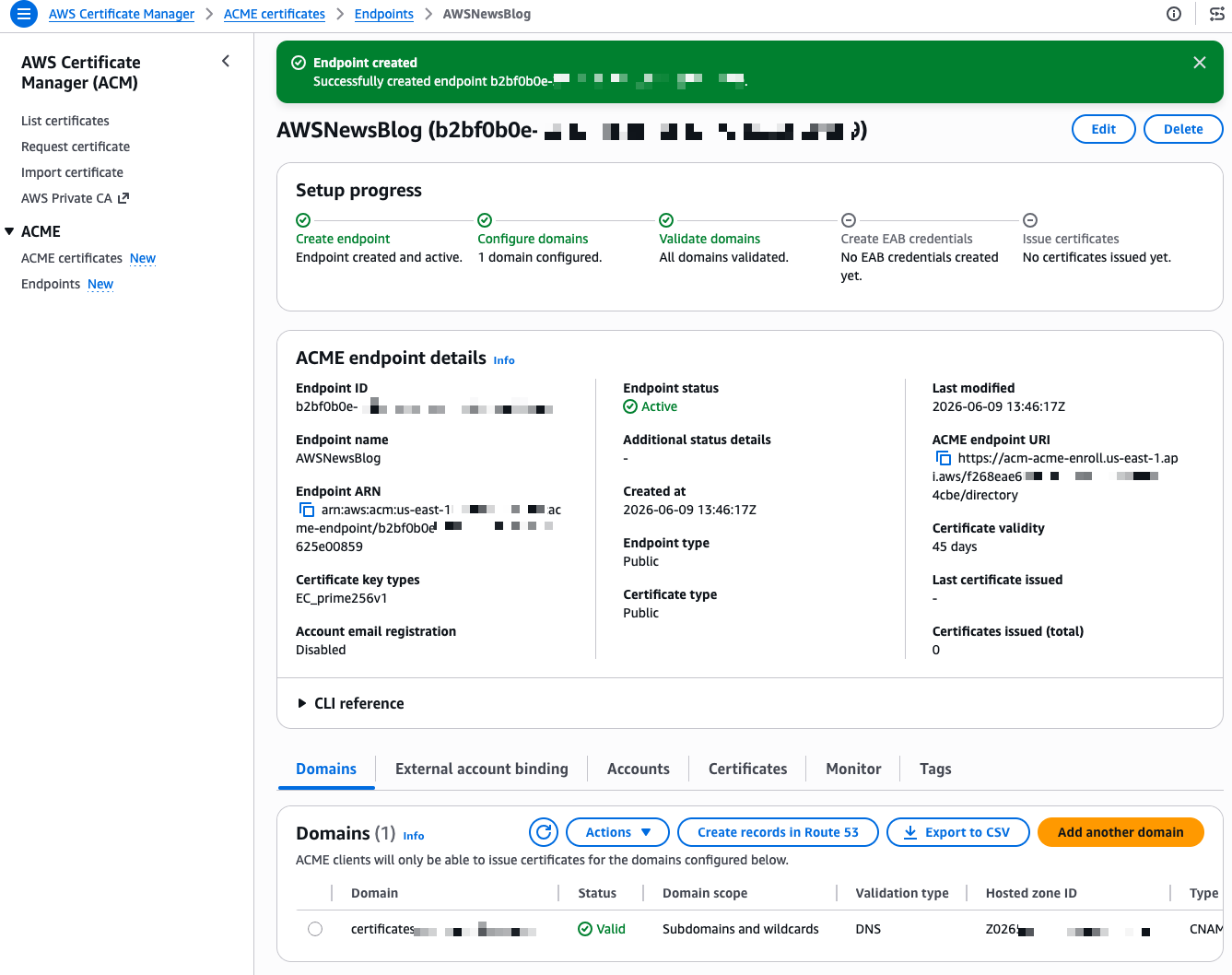
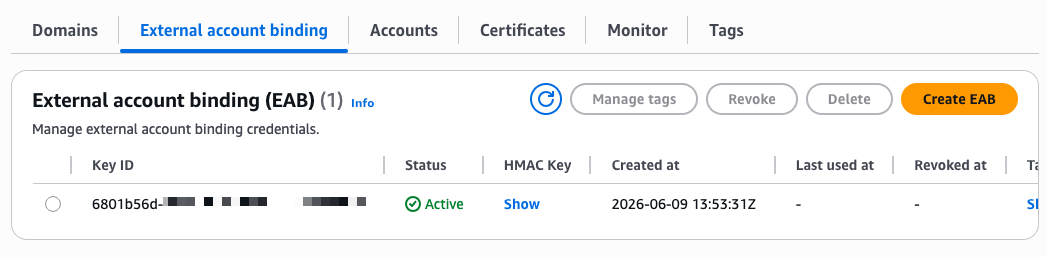
After I select Create EAB credential, the console shows the Key ID and HMAC Key. I note these values because I need them to configure my ACME client. The setup progress now shows four green checkmarks.
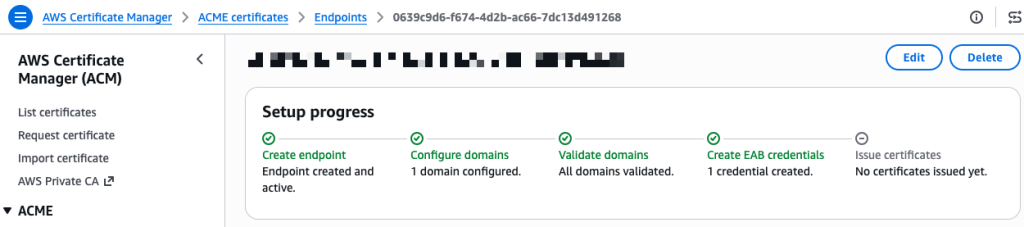
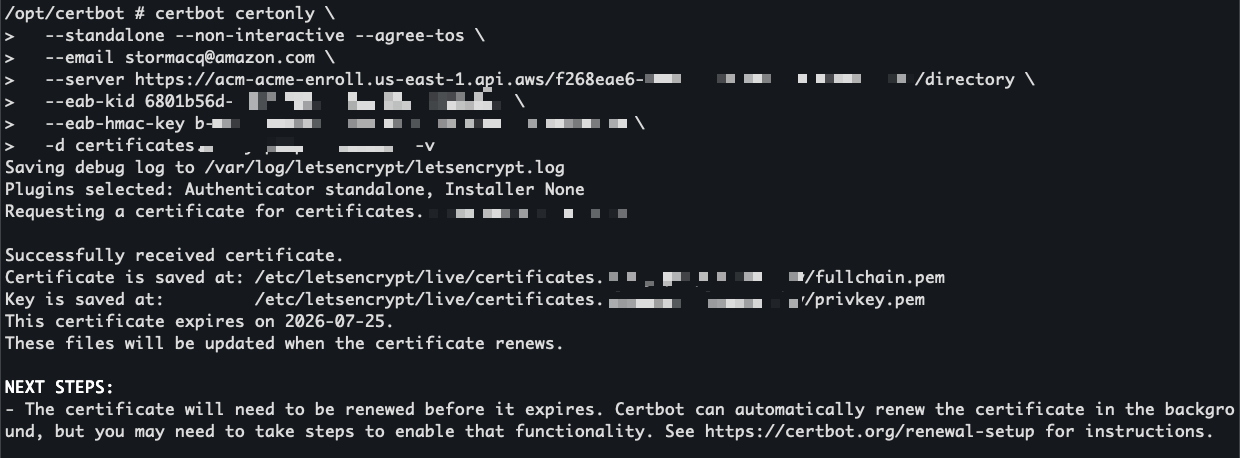
I’m ready to request a certificate. On the endpoint details page, I expand the CLI reference section. The console provides ready-to-use command examples for both Certbot and acme.sh. I copy the Certbot command and run it inside a container using the certbot/certbot image.
certbot certonly --standalone --non-interactive --agree-tos
--email <EMAIL>
--server https://acm-acme-enroll.us-east-1.api.aws/<ENDPOINT_ID>/directory
--eab-kid <EAB_KID>
--eab-hmac-key <EAB_HMAC_KEY>
--issuance-timeout <ISSUANCE_TIMEOUT>
-d <DOMAIN>
I replace the placeholders with my endpoint URL, EAB credentials, and domain name. The --eab-kid and --eab-hmac-key arguments are how Certbot registers with your ACME endpoint using the External Account Binding credentials I generated earlier. Each ACME client has its own syntax for this step, so check your client’s documentation for the exact flags.
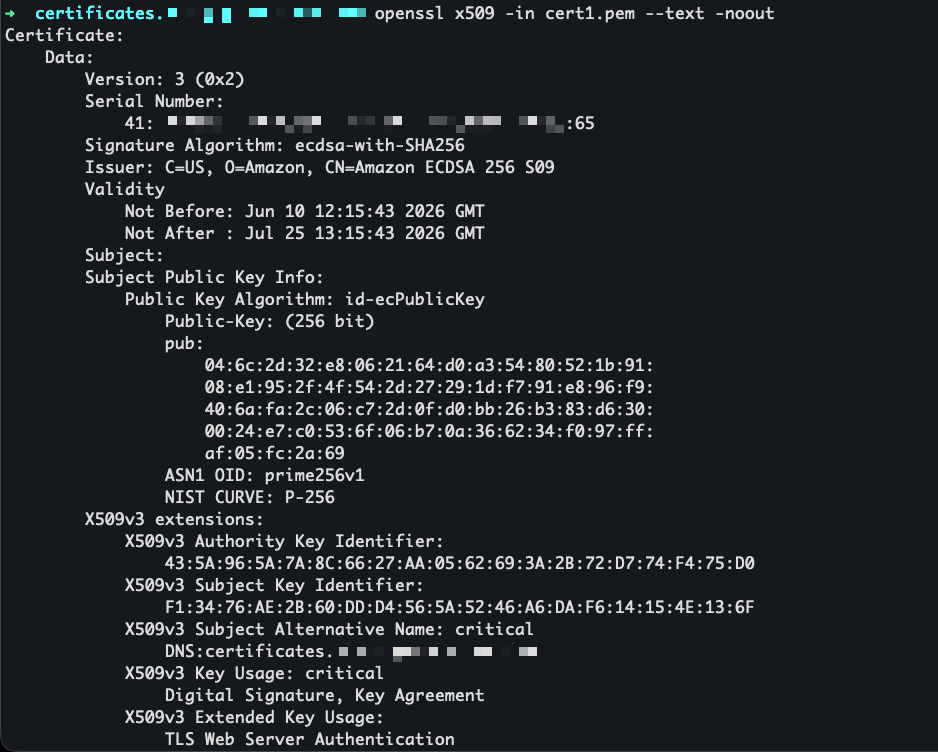
Certbot contacts the ACME endpoint and returns a valid certificate signed by Amazon Trust Services.
I use openssl to view the certificate before installing it.
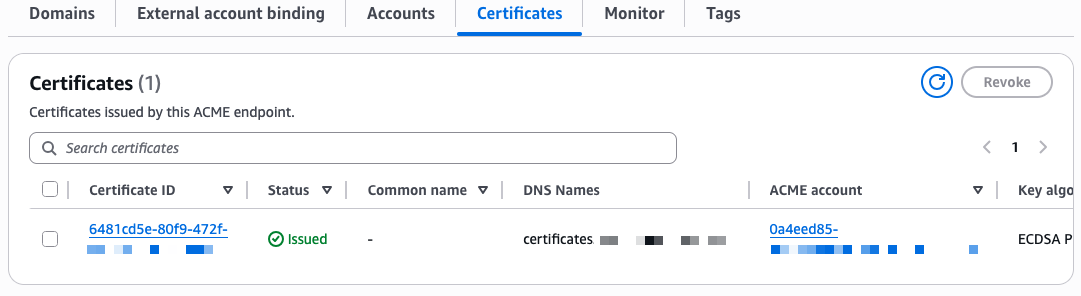
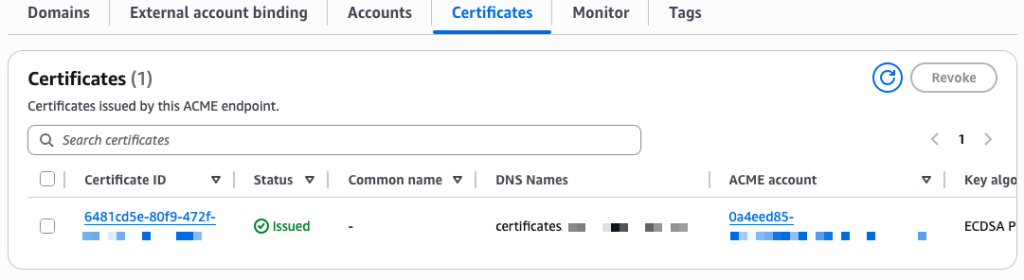
The certificate is now visible in the ACM console under the ACME certificates tab, alongside any certificates issued through the console or API.
Availability and pricing
ACME support in AWS Certificate Manager is available today in all commercial AWS Regions and will be available in AWS GovCloud (US), the China Regions, and the AWS European Sovereign Cloud partitions at a later date.
Pricing is per domain included in each certificate at the time of issuance, with a different price for fully qualified domain names and wildcards. Volume tiers are calculated based on total domain occurrences across all certificates issued per month in your AWS account. For details, see the ACM pricing page.
To get started, visit the ACM section on the AWS console or read the documentation.
— seb