This
post was originally published on
this siteWith Agents for Amazon Bedrock, applications can use generative artificial intelligence (generative AI) to run tasks across multiple systems and data sources. Starting today, these new capabilities streamline the creation and management of agents:
Quick agent creation – You can now quickly create an agent and optionally add instructions and action groups later, providing flexibility and agility for your development process.
Agent builder – All agent configurations can be operated in the new agent builder section of the console.
Simplified configuration – Action groups can use a simplified schema that just lists functions and parameters without having to provide an API schema.
Return of control –You can skip using an AWS Lambda function and return control to the application invoking the agent. In this way, the application can directly integrate with systems outside AWS or call internal endpoints hosted in any Amazon Virtual Private Cloud (Amazon VPC) without the need to integrate the required networking and security configurations with a Lambda function.
Infrastructure as code – You can use AWS CloudFormation to deploy and manage agents with the new simplified configuration, ensuring consistency and reproducibility across environments for your generative AI applications.
Let’s see how these enhancements work in practice.
Creating an agent using the new simplified console
To test the new experience, I want to build an agent that can help me reply to an email containing customer feedback. I can use generative AI, but a single invocation of a foundation model (FM) is not enough because I need to interact with other systems. To do that, I use an agent.
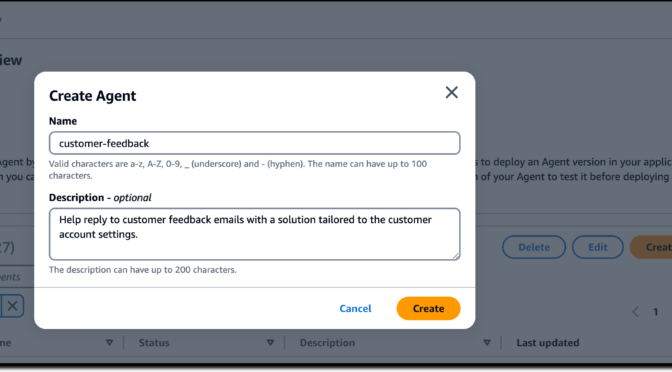
In the Amazon Bedrock console, I choose Agents from the navigation pane and then Create Agent. I enter a name for the agent (customer-feedback) and a description. Using the new interface, I proceed and create the agent without providing additional information at this stage.
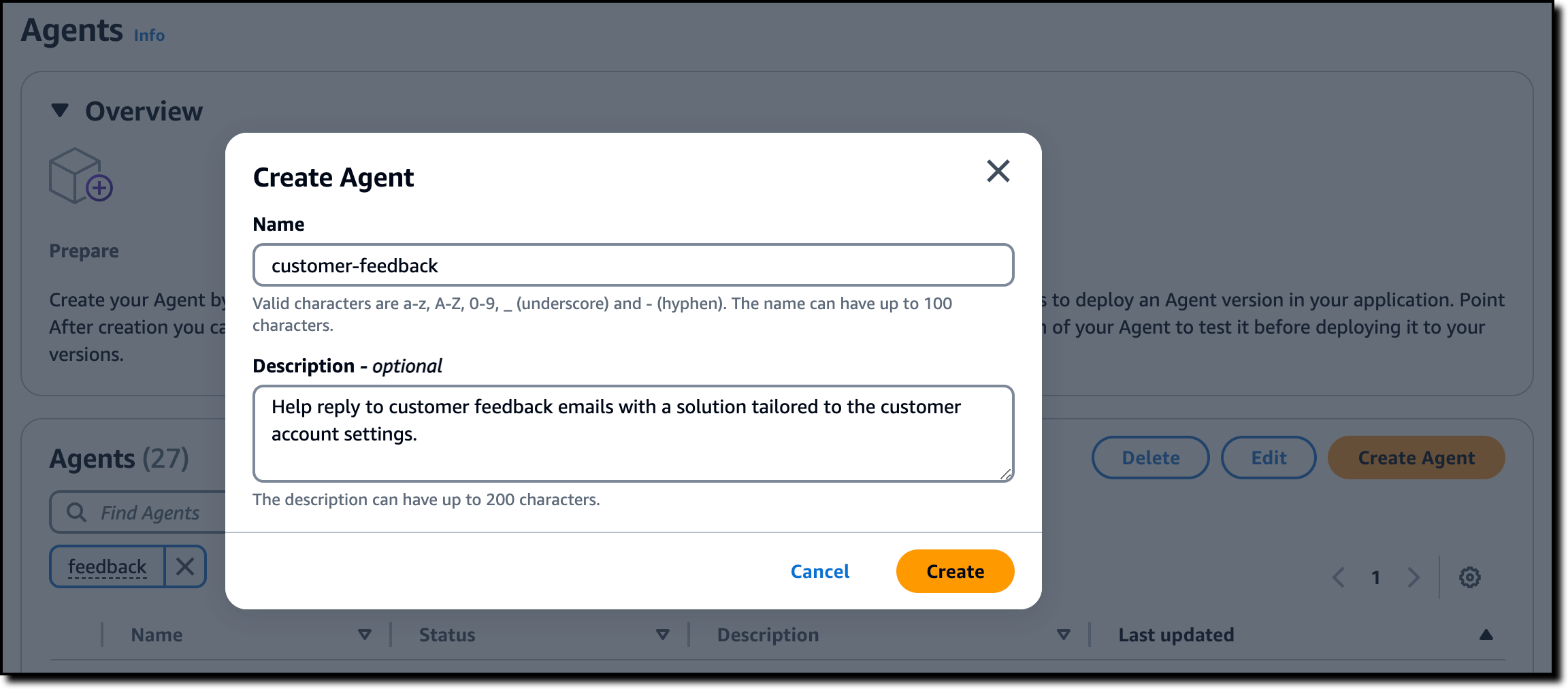
I am now presented with the Agent builder, the place where I can access and edit the overall configuration of an agent. In the Agent resource role, I leave the default setting as Create and use a new service role so that the AWS Identity and Access Management (IAM) role assumed by the agent is automatically created for me. For the model, I select Anthropic and Claude 3 Sonnet.
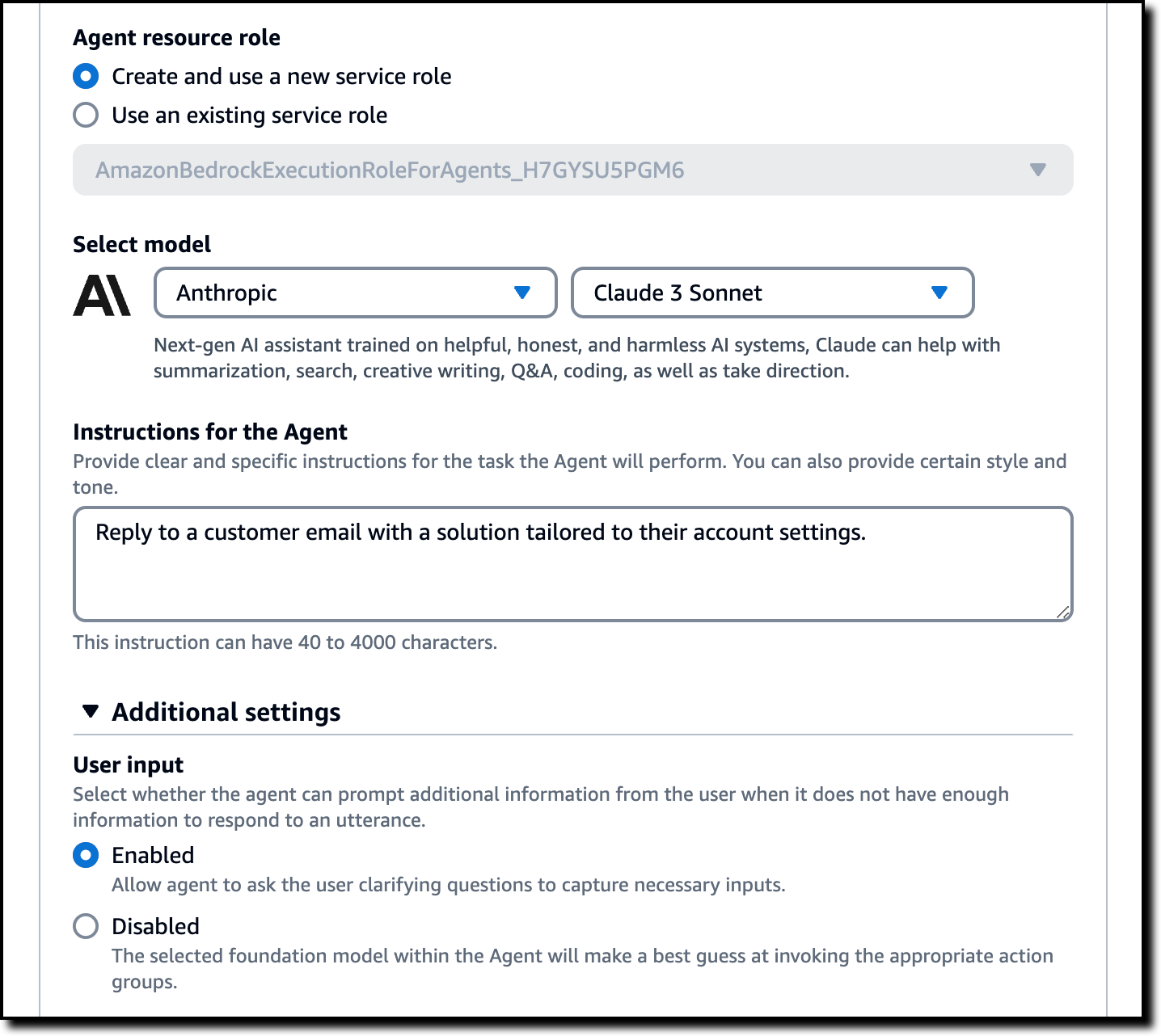
In Instructions for the Agent, I provide clear and specific instructions for the task the agent has to perform. Here, I can also specify the style and tone I want the agent to use when replying. For my use case, I enter:
Help reply to customer feedback emails with a solution tailored to the customer account settings.
In Additional settings, I select Enabled for User input so that the agent can ask for additional details when it does not have enough information to respond. Then, I choose Save to update the configuration of the agent.
I now choose Add in the Action groups section. Action groups are the way agents can interact with external systems to gather more information or perform actions. I enter a name (retrieve-customer-settings) and a description for the action group:
Retrieve customer settings including customer ID.
The description is optional but, when provided, is passed to the model to help choose when to use this action group.
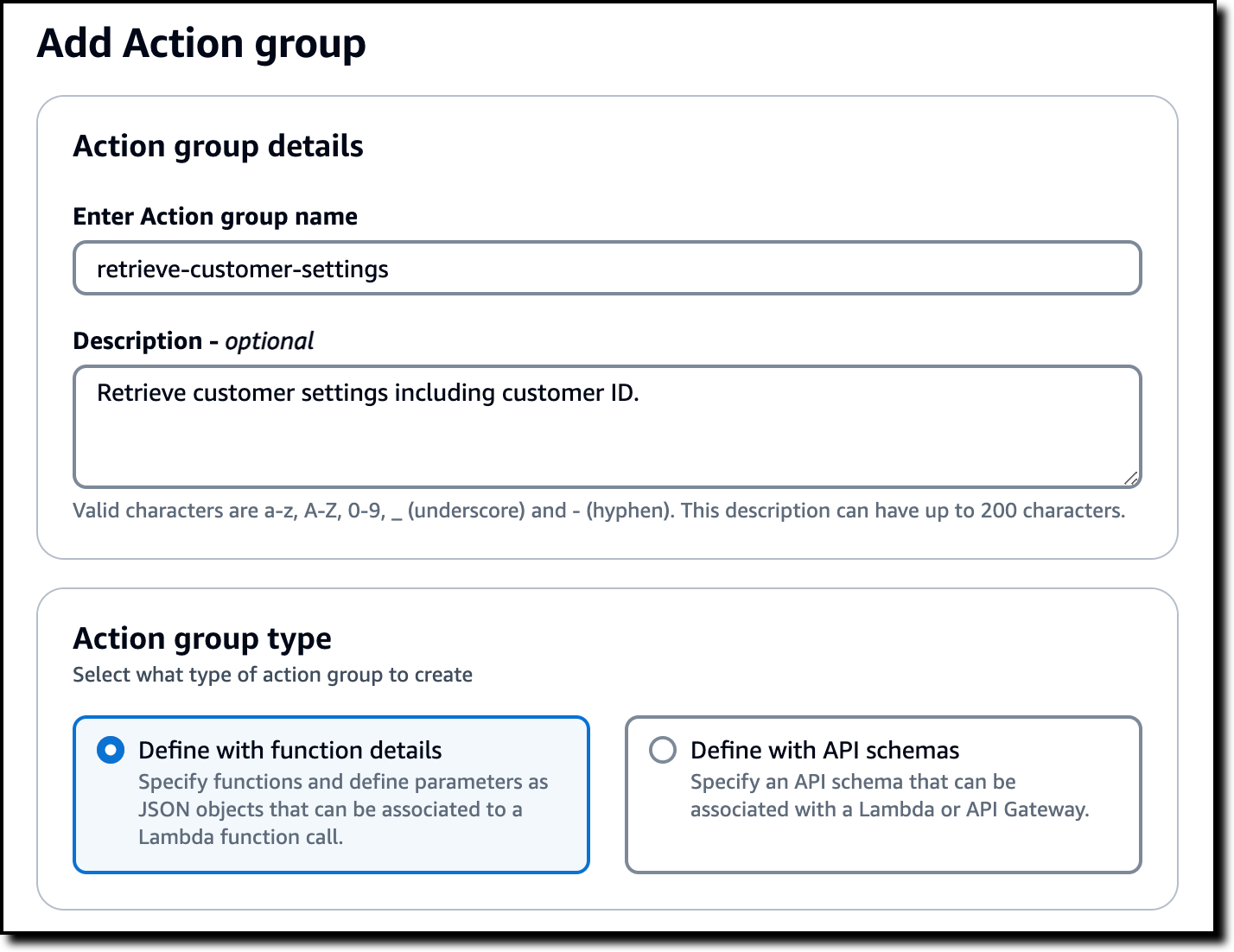
In Action group type, I select Define with function details so that I only need to specify functions and their parameters. The other option here (Define with API schemas) corresponds to the previous way of configuring action groups using an API schema.
Action group functions can be associated to a Lambda function call or configured to return control to the user or application invoking the agent so that they can provide a response to the function. The option to return control is useful for four main use cases:
- When it’s easier to call an API from an existing application (for example, the one invoking the agent) than building a new Lambda function with the correct authentication and network configurations as required by the API
- When the duration of the task goes beyond the maximum Lambda function timeout of 15 minutes so that I can handle the task with an application running in containers or virtual servers or use a workflow orchestration such as AWS Step Functions
- When I have time-consuming actions because, with the return of control, the agent doesn’t wait for the action to complete before proceeding to the next step, and the invoking application can run actions asynchronously in the background while the orchestration flow of the agent continues
- When I need a quick way to mock the interaction with an API during the development and testing and of an agent
In Action group invocation, I can specify the Lambda function that will be invoked when this action group is identified by the model during orchestration. I can ask the console to quickly create a new Lambda function, to select an existing Lambda function, or return control so that the user or application invoking the agent will ask for details to generate a response. I select Return Control to show how that works in the console.

I configure the first function of the action group. I enter a name (retrieve-customer-settings-from-crm) and the following description for the function:
Retrieve customer settings from CRM including customer ID using the customer email in the sender/from fields of the email.
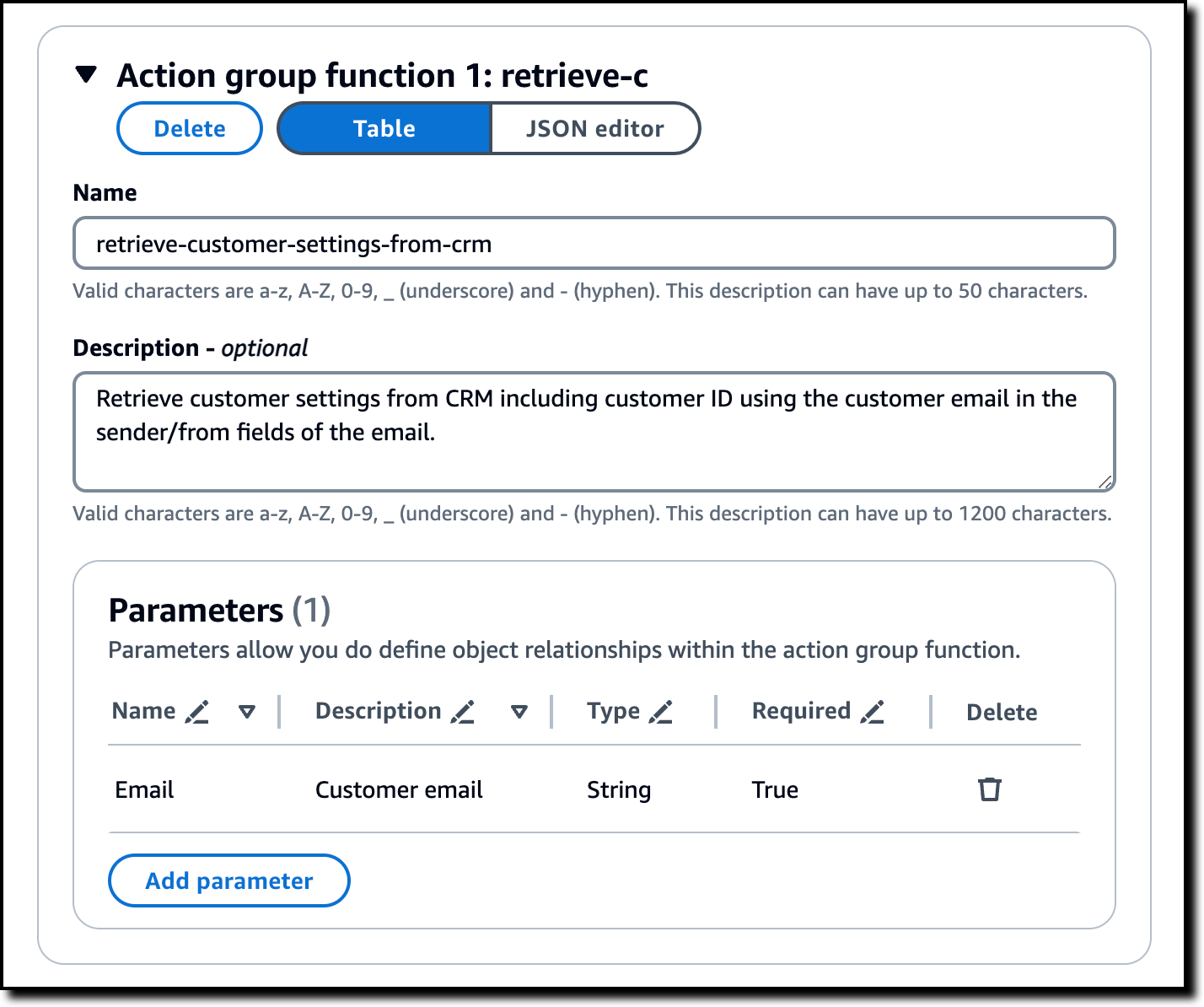
In Parameters, I add email with Customer email as the description. This is a parameter of type String and is required by this function. I choose Add to complete the creation of the action group.
Because, for my use case, I expect many customers to have issues when logging in, I add another action group (named check-login-status) with the following description:
Check customer login status.
This time, I select the option to create a new Lambda function so that I can handle these requests in code.
For this action group, I configure a function (named check-customer-login-status-in-login-system) with the following description:
Check customer login status in login system using the customer ID from settings.
In Parameters, I add customer_id, another required parameter of type String. Then, I choose Add to complete the creation of the second action group.
When I open the configuration of this action group, I see the name of the Lambda function that has been created in my account. There, I choose View to open the Lambda function in the console.
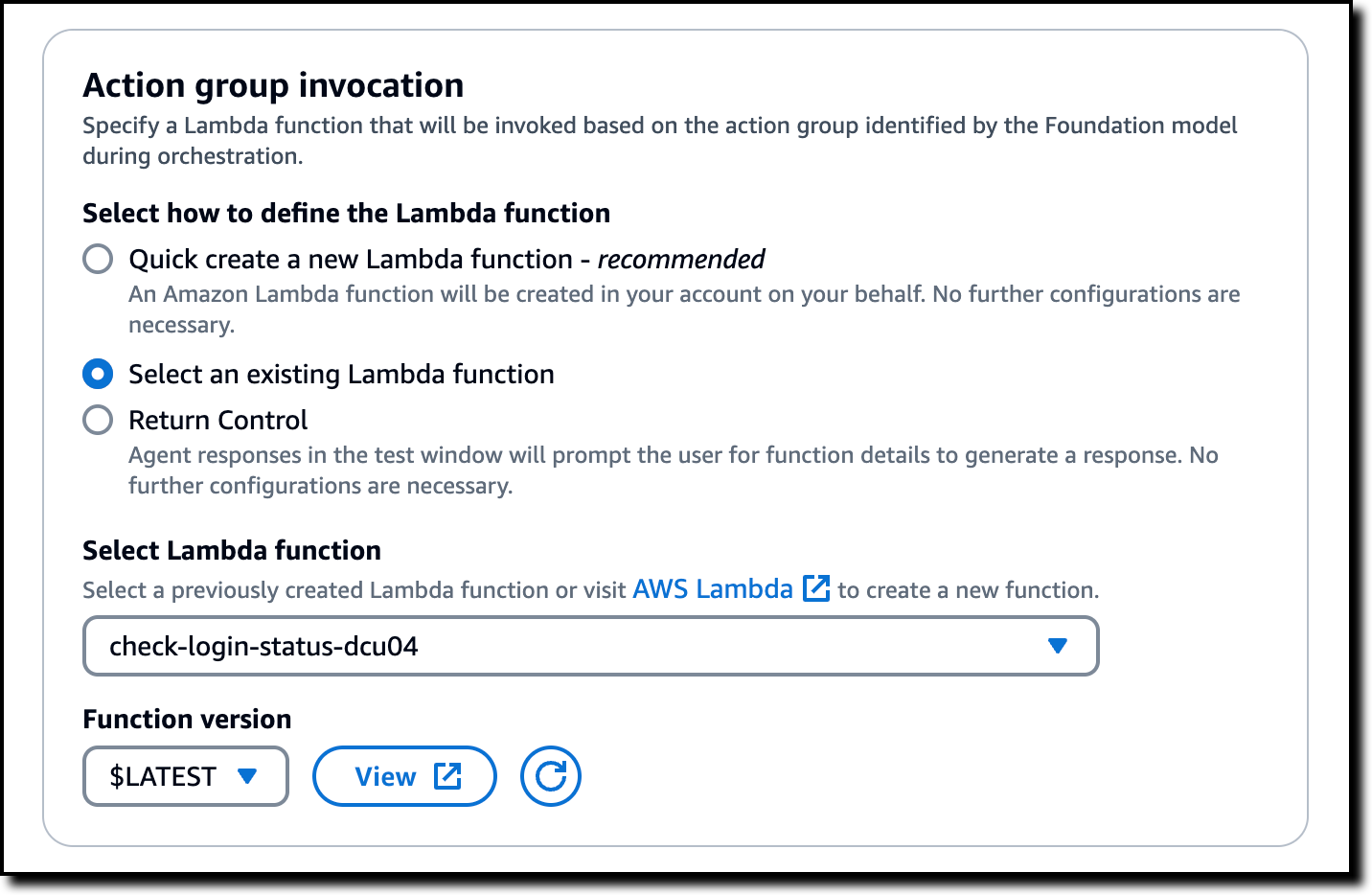
In the Lambda console, I edit the starting code that has been provided and implement my business case:
import json
def lambda_handler(event, context):
print(event)
agent = event['agent']
actionGroup = event['actionGroup']
function = event['function']
parameters = event.get('parameters', [])
# Execute your business logic here. For more information,
# refer to: https://docs.aws.amazon.com/bedrock/latest/userguide/agents-lambda.html
if actionGroup == 'check-login-status' and function == 'check-customer-login-status-in-login-system':
response = {
"status": "unknown"
}
for p in parameters:
if p['name'] == 'customer_id' and p['type'] == 'string' and p['value'] == '12345':
response = {
"status": "not verified",
"reason": "the email address has not been verified",
"solution": "please verify your email address"
}
else:
response = {
"error": "Unknown action group {} or function {}".format(actionGroup, function)
}
responseBody = {
"TEXT": {
"body": json.dumps(response)
}
}
action_response = {
'actionGroup': actionGroup,
'function': function,
'functionResponse': {
'responseBody': responseBody
}
}
dummy_function_response = {'response': action_response, 'messageVersion': event['messageVersion']}
print("Response: {}".format(dummy_function_response))
return dummy_function_response
I choose Deploy in the Lambda console. The function is configured with a resource-based policy that allows Amazon Bedrock to invoke the function. For this reason, I don’t need to update the IAM role used by the agent.
I am ready to test the agent. Back in the Amazon Bedrock console, with the agent selected, I look for the Test Agent section. There, I choose Prepare to prepare the agent and test it with the latest changes.
As input to the agent, I provide this sample email:
From: danilop@example.com
Subject: Problems logging in
Hi, when I try to log into my account, I get an error and cannot proceed further. Can you check? Thank you, Danilo
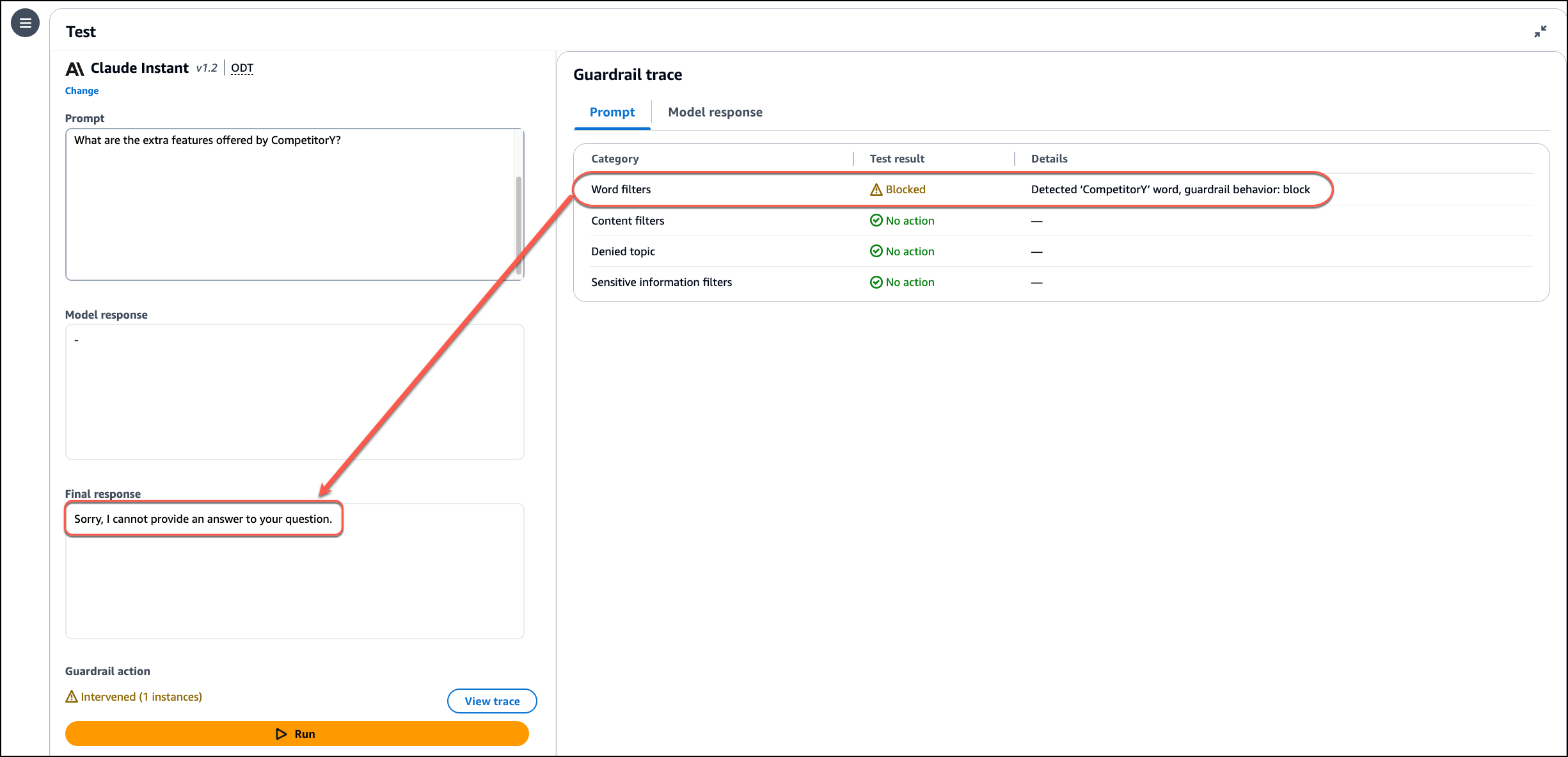
In the first step, the agent orchestration decides to use the first action group (retrieve-customer-settings) and function (retrieve-customer-settings-from-crm). This function is configured to return control, and in the console, I am asked to provide the output of the action group function. The customer email address is provided as the input parameter.
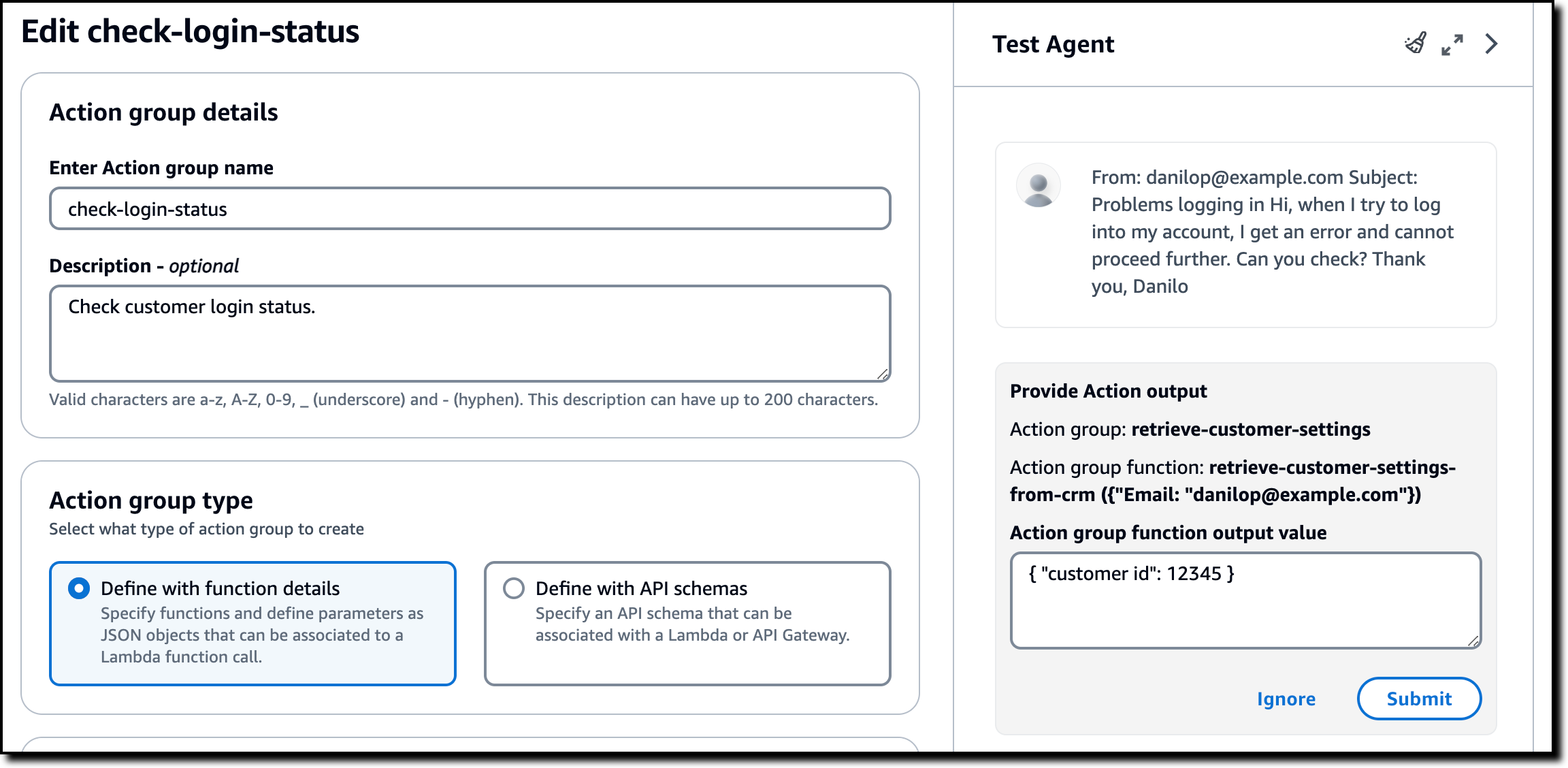
To simulate an interaction with an application, I reply with a JSON syntax and choose Submit:
{ "customer id": 12345 }
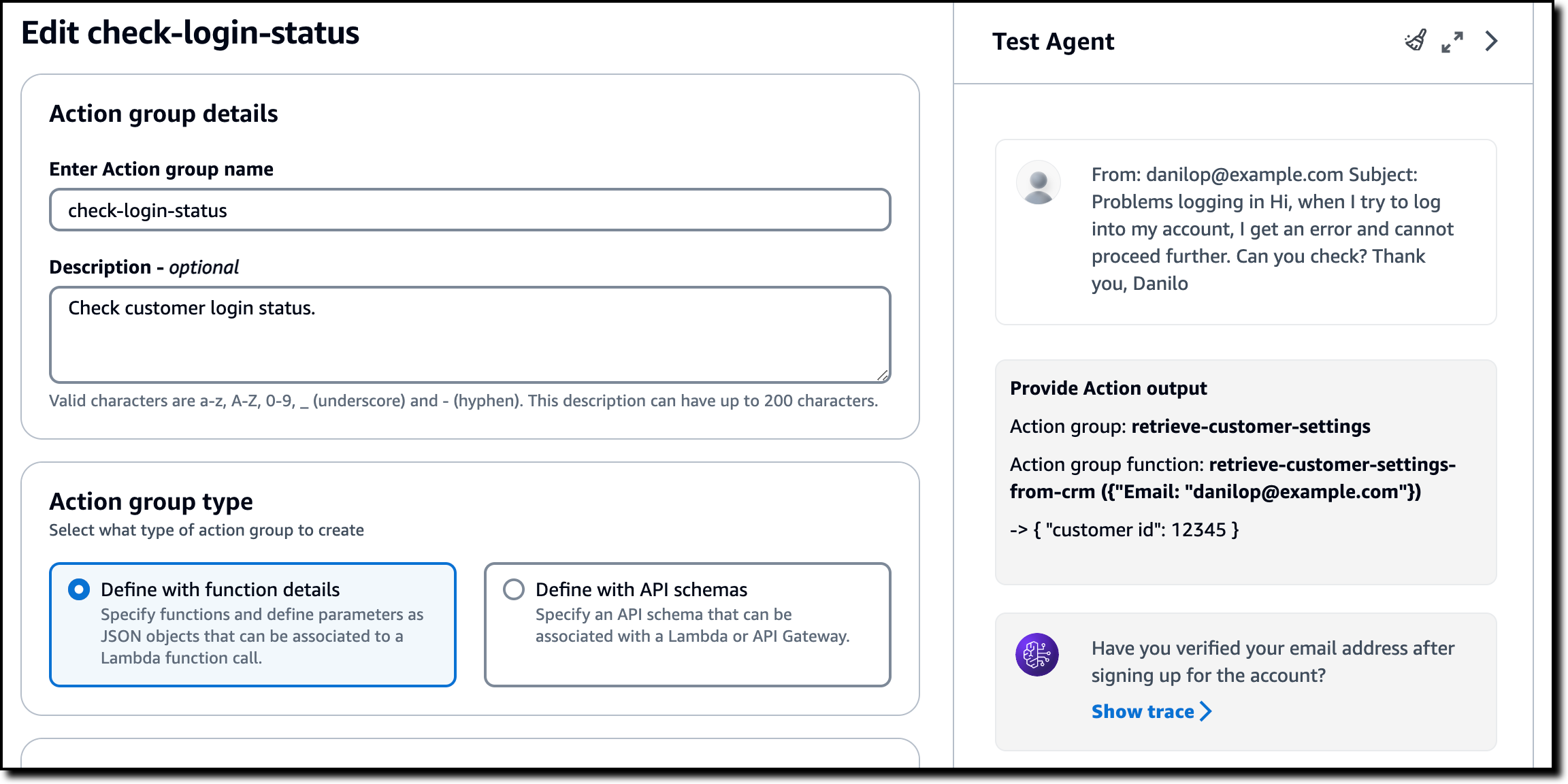
In the next step, the agent has the information required to use the second action group (check-login-status) and function (check-customer-login-status-in-login-system) to call the Lambda function. In return, the Lambda function provides this JSON payload:
{
"status": "not verified",
"reason": "the email address has not been verified",
"solution": "please verify your email address"
}
Using this content, the agent can complete its task and suggest the correct solution for this customer.
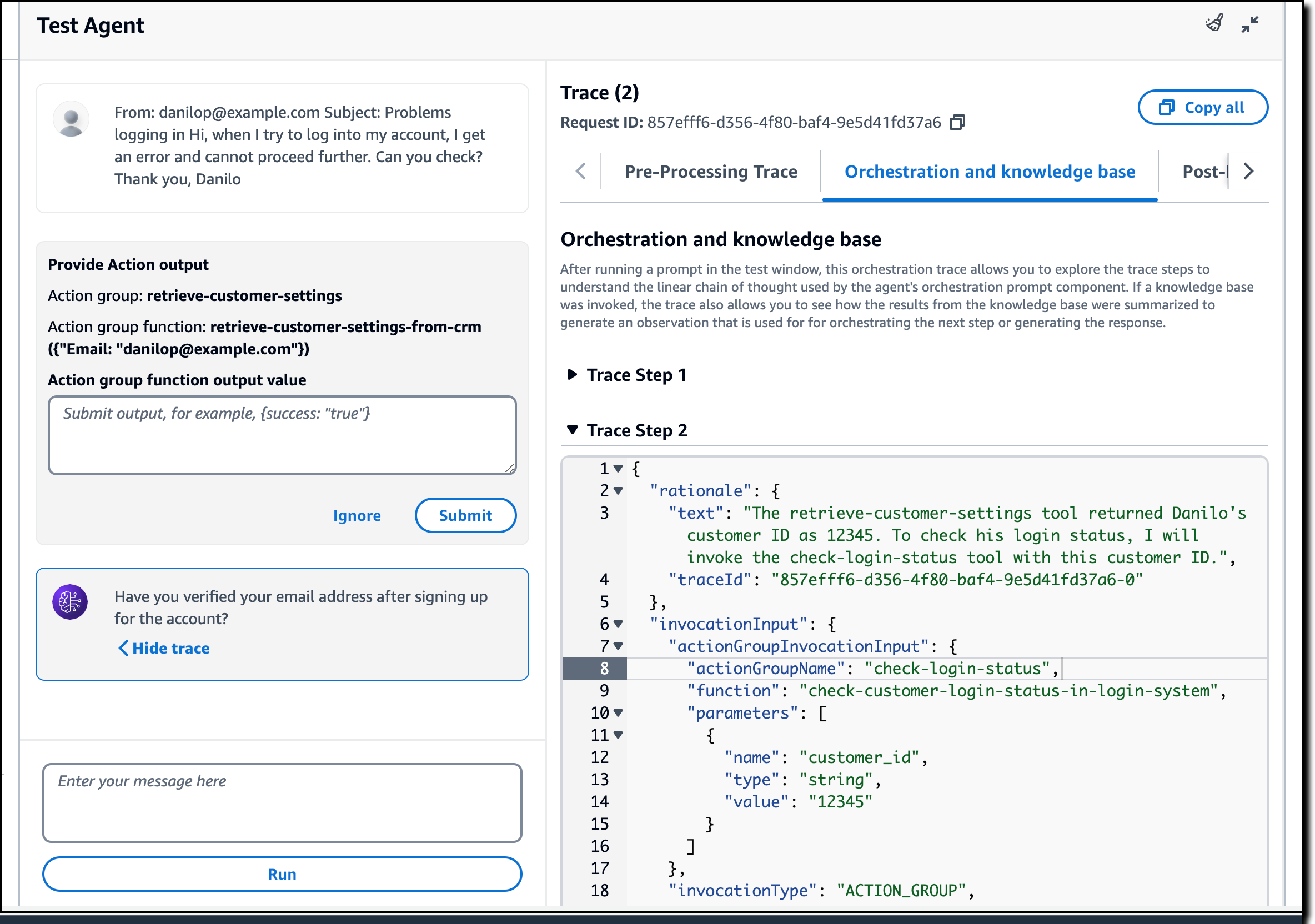
I am satisfied with the result, but I want to know more about what happened under the hood. I choose Show trace where I can see the details of each step of the agent orchestration. This helps me understand the agent decisions and correct the configurations of the agent groups if they are not used as I expect.
Things to know
You can use the new simplified experience to create and manage Agents for Amazon Bedrock in the US East (N. Virginia) and US West (Oregon) AWS Regions.
You can now create an agent without having to specify an API schema or provide a Lambda function for the action groups. You just need to list the parameters that the action group needs. When invoking the agent, you can choose to return control with the details of the operation to perform so that you can handle the operation in your existing applications or if the duration is longer than the maximum Lambda function timeout.
CloudFormation support for Agents for Amazon Bedrock has been released recently and is now being updated to support the new simplified syntax.
To learn more:
— Danilo